Aggregating Millions of Groups Fast in Apache Arrow DataFusion 28.0.0
Posted on: Sat 05 August 2023 by alamb, Dandandan, tustvold
Aggregating Millions of Groups Fast in Apache Arrow DataFusion¶
Andrew Lamb, Daniël Heres, Raphael Taylor-Davies,
Note: this article was originally published on the InfluxData Blog
TLDR¶
Grouped aggregations are a core part of any analytic tool, creating understandable summaries of huge data volumes. Apache Arrow DataFusion’s parallel aggregation capability is 2-3x faster in the newly released version 28.0.0 for queries with a large number (10,000 or more) of groups.
Improving aggregation performance matters to all users of DataFusion. For example, both InfluxDB, a time series data platform and Coralogix, a full-stack observability platform, aggregate vast amounts of raw data to monitor and create insights for our customers. Improving DataFusion’s performance lets us provide better user experiences by generating insights faster with fewer resources. Because DataFusion is open source and released under the permissive Apache 2.0 license, the whole DataFusion community benefits as well.
With the new optimizations, DataFusion’s grouping speed is now close to DuckDB, a system that regularly reports great grouping benchmark performance numbers. Figure 1 contains a representative sample of ClickBench on a single Parquet file, and the full results are at the end of this article.
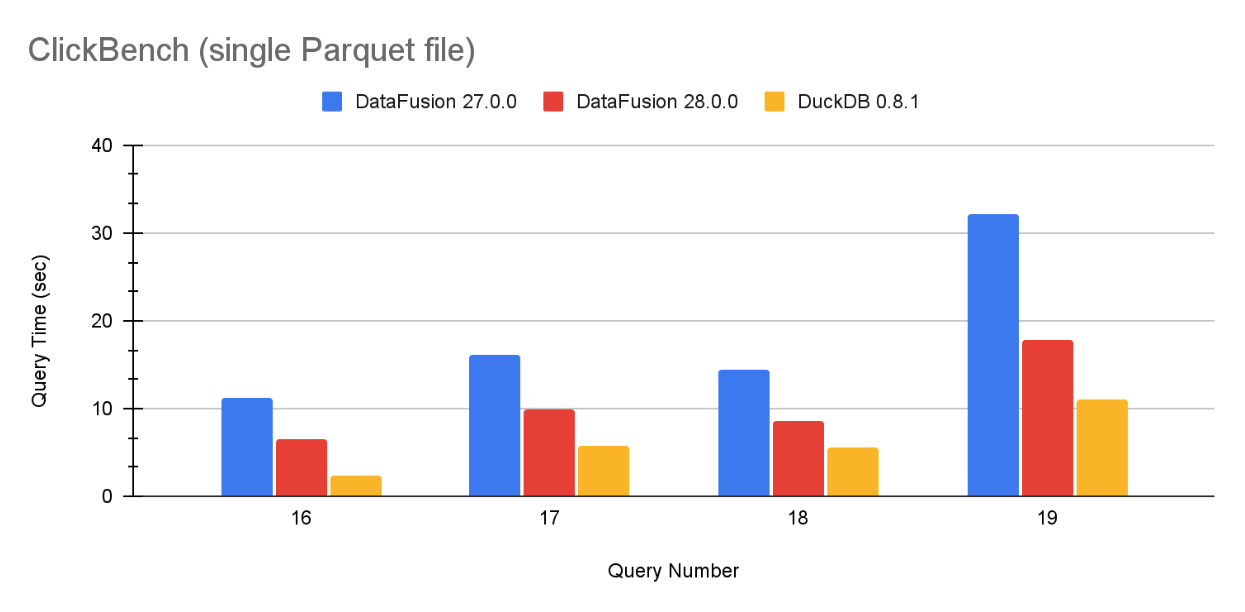
Figure 1: Query performance for ClickBench queries on queries 16, 17, 18 and 19 on a single Parquet file for DataFusion 27.0.0, DataFusion 28.0.0 and DuckDB 0.8.1.
Introduction to high cardinality grouping¶
Aggregation is a fancy word for computing summary statistics across many rows that have the same value in one or more columns. We call the rows with the same values groups and “high cardinality” means there are a large number of distinct groups in the dataset. At the time of writing, a “large” number of groups in analytic engines is around 10,000.
For example the ClickBench hits dataset contains 100 million anonymized user clicks across a set of websites. ClickBench Query 17 is:
SELECT "UserID", "SearchPhrase", COUNT(*)
FROM hits
GROUP BY "UserID", "SearchPhrase"
ORDER BY COUNT(*)
DESC LIMIT 10;
In English, this query finds “the top ten (user, search phrase) combinations, across all clicks” and produces the following results (there are no search phrases for the top ten users):
+---------------------+--------------+-----------------+
| UserID | SearchPhrase | COUNT(UInt8(1)) |
+---------------------+--------------+-----------------+
| 1313338681122956954 | | 29097 |
| 1907779576417363396 | | 25333 |
| 2305303682471783379 | | 10597 |
| 7982623143712728547 | | 6669 |
| 7280399273658728997 | | 6408 |
| 1090981537032625727 | | 6196 |
| 5730251990344211405 | | 6019 |
| 6018350421959114808 | | 5990 |
| 835157184735512989 | | 5209 |
| 770542365400669095 | | 4906 |
+---------------------+--------------+-----------------+
The ClickBench dataset contains
- 99,997,497 total rows[^1]
- 17,630,976 different users (distinct UserIDs)[^2]
- 6,019,103 different search phrases[^3]
- 24,070,560 distinct combinations[^4] of (UserID, SearchPhrase) Thus, to answer the query, DataFusion must map each of the 100M different input rows into one of the 24 million different groups, and keep count of how many such rows there are in each group.
The solution¶
Like most concepts in databases and other analytic systems, the basic ideas of this algorithm are straightforward and taught in introductory computer science courses. You could compute the query with a program such as this[^5]:
import pandas as pd
from collections import defaultdict
from operator import itemgetter
# read file
hits = pd.read_parquet('hits.parquet', engine='pyarrow')
# build groups
counts = defaultdict(int)
for index, row in hits.iterrows():
group = (row['UserID'], row['SearchPhrase']);
# update the dict entry for the corresponding key
counts[group] += 1
# Print the top 10 values
print (dict(sorted(counts.items(), key=itemgetter(1), reverse=True)[:10]))
This approach, while simple, is both slow and very memory inefficient. It requires over 40 seconds to compute the results for less than 1% of the dataset[^6]. Both DataFusion 28.0.0 and DuckDB 0.8.1 compute results in under 10 seconds for the entire dataset.
To answer this query quickly and efficiently, you have to write your code such that it:
- Keeps all cores busy aggregating via parallelized computation
- Updates aggregate values quickly, using vectorizable loops that are easy for compilers to translate into the high performance SIMD instructions available in modern CPUs.
The rest of this article explains how grouping works in DataFusion and the improvements we made in 28.0.0.
Two phase parallel partitioned grouping¶
Both DataFusion 27.0. and 28.0.0 use state-of-the-art, two phase parallel hash partitioned grouping, similar to other high-performance vectorized engines like DuckDB’s Parallel Grouped Aggregates. In pictures this looks like:
▲ ▲
│ │
│ │
│ │
┌───────────────────────┐ ┌───────────────────┐
│ GroupBy │ │ GroupBy │ Step 4
│ (Final) │ │ (Final) │
└───────────────────────┘ └───────────────────┘
▲ ▲
│ │
└────────────┬───────────┘
│
│
┌─────────────────────────┐
│ Repartition │ Step 3
│ HASH(x) │
└─────────────────────────┘
▲
│
┌────────────┴──────────┐
│ │
│ │
┌────────────────────┐ ┌─────────────────────┐
│ GroupyBy │ │ GroupBy │ Step 2
│ (Partial) │ │ (Partial) │
└────────────────────┘ └─────────────────────┘
▲ ▲
┌──┘ └─┐
│ │
.─────────. .─────────.
,─' '─. ,─' '─.
; Input : ; Input : Step 1
: Stream 1 ; : Stream 2 ;
╲ ╱ ╲ ╱
'─. ,─' '─. ,─'
`───────' `───────'
Figure 2: Two phase repartitioned grouping: data flows from bottom (source) to top (results) in two phases. First (Steps 1 and 2), each core reads the data into a core-specific hash table, computing intermediate aggregates without any cross-core coordination. Then (Steps 3 and 4) DataFusion divides the data (“repartitions”) into distinct subsets by group value, and each subset is sent to a specific core which computes the final aggregate.
The two phases are critical for keeping cores busy in a multi-core system. Both phases use the same hash table approach (explained in the next section), but differ in how the groups are distributed and the partial results emitted from the accumulators. The first phase aggregates data as soon as possible after it is produced. However, as shown in Figure 2, the groups can be anywhere in any input, so the same group is often found on many different cores. The second phase uses a hash function to redistribute data evenly across the cores, so each group value is processed by exactly one core which emits the final results for that group.
┌─────┐ ┌─────┐
│ 1 │ │ 3 │
│ 2 │ │ 4 │ 2. After Repartitioning: each
└─────┘ └─────┘ group key appears in exactly
┌─────┐ ┌─────┐ one partition
│ 1 │ │ 3 │
│ 2 │ │ 4 │
└─────┘ └─────┘
─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
┌─────┐ ┌─────┐
│ 2 │ │ 2 │
│ 1 │ │ 2 │
│ 3 │ │ 3 │
│ 4 │ │ 1 │
└─────┘ └─────┘ 1. Input Stream: groups
... ... values are spread
┌─────┐ ┌─────┐ arbitrarily over each input
│ 1 │ │ 4 │
│ 4 │ │ 3 │
│ 1 │ │ 1 │
│ 4 │ │ 3 │
│ 3 │ │ 2 │
│ 2 │ │ 2 │
│ 2 │ └─────┘
└─────┘
Core A Core B
Figure 3: Group value distribution across 2 cores during aggregation phases. In the first phase, every group value 1, 2, 3, 4, is present in the input stream processed by each core. In the second phase, after repartitioning, the group values 1 and 2 are processed by core A, and values 3 and 4 are processed only by core B.
There are some additional subtleties in the DataFusion implementation not mentioned above due to space constraints, such as:
- The policy of when to emit data from the first phase’s hash table (e.g. because the data is partially sorted)
- Handling specific filters per aggregate (due to the
FILTERSQL clause) - Data types of intermediate values (which may not be the same as the final output for some aggregates such as
AVG). - Action taken when memory use exceeds its budget.
Hash grouping¶
DataFusion queries can compute many different aggregate functions for each group, both built in and/or user defined AggregateUDFs. The state for each aggregate function, called an accumulator, is tracked with a hash table (DataFusion uses the excellent HashBrown RawTable API), which logically stores the “index” identifying the specific group value.
Hash grouping in 27.0.0¶
As shown in Figure 3, DataFusion 27.0.0 stores the data in a GroupState structure which, unsurprisingly, tracks the state for each group. The state for each group consists of:
- The actual value of the group columns, in Arrow Row format.
- In-progress accumulations (e.g. the running counts for the
COUNTaggregate) for each group, in one of two possible formats (AccumulatororRowAccumulator). - Scratch space for tracking which rows match each aggregate in each batch.
┌──────────────────────────────────────┐
│ │
│ ... │
│ ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ │
│ ┃ ┃ │
┌─────────┐ │ ┃ ┌──────────────────────────────┐ ┃ │
│ │ │ ┃ │group values: OwnedRow │ ┃ │
│ ┌─────┐ │ │ ┃ └──────────────────────────────┘ ┃ │
│ │ 5 │ │ │ ┃ ┌──────────────────────────────┐ ┃ │
│ ├─────┤ │ │ ┃ │Row accumulator: │ ┃ │
│ │ 9 │─┼────┐ │ ┃ │Vec<u8> │ ┃ │
│ ├─────┤ │ │ │ ┃ └──────────────────────────────┘ ┃ │
│ │ ... │ │ │ │ ┃ ┌──────────────────────┐ ┃ │
│ ├─────┤ │ │ │ ┃ │┌──────────────┐ │ ┃ │
│ │ 1 │ │ │ │ ┃ ││Accumulator 1 │ │ ┃ │
│ ├─────┤ │ │ │ ┃ │└──────────────┘ │ ┃ │
│ │ ... │ │ │ │ ┃ │┌──────────────┐ │ ┃ │
│ └─────┘ │ │ │ ┃ ││Accumulator 2 │ │ ┃ │
│ │ │ │ ┃ │└──────────────┘ │ ┃ │
└─────────┘ │ │ ┃ │ Box<dyn Accumulator> │ ┃ │
Hash Table │ │ ┃ └──────────────────────┘ ┃ │
│ │ ┃ ┌─────────────────────────┐ ┃ │
│ │ ┃ │scratch indices: Vec<u32>│ ┃ │
│ │ ┃ └─────────────────────────┘ ┃ │
│ │ ┃ GroupState ┃ │
└─────▶ │ ┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛ │
│ │
Hash table tracks an │ ... │
index into group_states │ │
└──────────────────────────────────────┘
group_states: Vec<GroupState>
There is one GroupState PER GROUP
Figure 4: Hash group operator structure in DataFusion 27.0.0. A hash table maps each group to a GroupState which contains all the per-group states.
To compute the aggregate, DataFusion performs the following steps for each input batch:
- Calculate hash using efficient vectorized code, specialized for each data type.
- Determine group indexes for each input row using the hash table (creating new entries for newly seen groups).
- Update Accumulators for each group that had input rows, assembling the rows into a contiguous range for vectorized accumulator if there are a sufficient number of them.
DataFusion also stores the hash values in the table to avoid potentially costly hash recomputation when resizing the hash table.
This scheme works very well for a relatively small number of distinct groups: all accumulators are efficiently updated with large contiguous batches of rows.
However, this scheme is not ideal for high cardinality grouping due to:
- Multiple allocations per group for the group value row format, as well as for the
RowAccumulators and eachAccumulator. TheAccumulatormay have additional allocations within it as well. - Non-vectorized updates: Accumulator updates often fall back to a slower non-vectorized form because the number of distinct groups is large (and thus number of values per group is small) in each input batch.
Hash grouping in 28.0.0¶
For 28.0.0, we rewrote the core group by implementation following traditional system optimization principles: fewer allocations, type specialization, and aggressive vectorization.
DataFusion 28.0.0 uses the same RawTable and still stores group indexes. The major differences, as shown in Figure 4, are:
- Group values are stored either
- Inline in the
RawTable(for single columns of primitive types), where the conversion to Row format costs more than its benefit - In a separate Rows structure with a single contiguous allocation for all groups values, rather than an allocation per group. Accumulators manage the state for all the groups internally, so the code to update intermediate values is a tight type specialized loop. The new
GroupsAccumulatorinterface results in highly efficient type accumulator update loops.
- Inline in the
┌───────────────────────────────────┐ ┌───────────────────────┐
│ ┌ ─ ─ ─ ─ ─ ┐ ┌─────────────────┐│ │ ┏━━━━━━━━━━━━━━━━━━━┓ │
│ │ ││ │ ┃ ┌──────────────┐ ┃ │
│ │ │ │ ┌ ─ ─ ┐┌─────┐ ││ │ ┃ │┌───────────┐ │ ┃ │
│ │ X │ 5 │ ││ │ ┃ ││ value1 │ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ │└───────────┘ │ ┃ │
│ │ Q │ 9 │──┼┼──┐ │ ┃ │ ... │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ └──┼─╋─▶│ │ ┃ │
│ │ ... │ ... │ ││ │ ┃ │┌───────────┐ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ ││ valueN │ │ ┃ │
│ │ H │ 1 │ ││ │ ┃ │└───────────┘ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ │values: Vec<T>│ ┃ │
│ Rows │ ... │ ... │ ││ │ ┃ └──────────────┘ ┃ │
│ │ │ │ └ ─ ─ ┘└─────┘ ││ │ ┃ ┃ │
│ ─ ─ ─ ─ ─ ─ │ ││ │ ┃ GroupsAccumulator ┃ │
│ └─────────────────┘│ │ ┗━━━━━━━━━━━━━━━━━━━┛ │
│ Hash Table │ │ │
│ │ │ ... │
└───────────────────────────────────┘ └───────────────────────┘
GroupState Accumulators
Hash table value stores group_indexes One GroupsAccumulator
and group values. per aggregate. Each
stores the state for
Group values are stored either inline *ALL* groups, typically
in the hash table or in a single using a native Vec<T>
allocation using the arrow Row format
Figure 5: Hash group operator structure in DataFusion 28.0.0. Group values are stored either directly in the hash table, or in a single allocation using the arrow Row format. The hash table contains group indexes. A single GroupsAccumulator stores the per-aggregate state for all groups.
This new structure improves performance significantly for high cardinality groups due to:
- Reduced allocations: There are no longer any individual allocations per group.
- Contiguous native accumulator states: Type-specialized accumulators store the values for all groups in a single contiguous allocation using a Rust Vec<T> of some native type.
- Vectorized state update: The inner aggregate update loops, which are type-specialized and in terms of native
Vecs, are well-vectorized by the Rust compiler (thanks LLVM!).
Notes¶
Some vectorized grouping implementations store the accumulator state row-wise directly in the hash table, which often uses modern CPU caches efficiently. Managing accumulator state in columnar fashion may sacrifice some cache locality, however it ensures the size of the hash table remains small, even when there are large numbers of groups and aggregates, making it easier for the compiler to vectorize the accumulator update.
Depending on the cost of recomputing hash values, DataFusion 28.0.0 may or may not store the hash values in the table. This optimizes the tradeoff between the cost of computing the hash value (which is expensive for strings, for example) vs. the cost of storing it in the hash table.
One subtlety that arises from pushing state updates into GroupsAccumulators is that each accumulator must handle similar variations with/without filtering and with/without nulls in the input. DataFusion 28.0.0 uses a templated NullState which encapsulates these common patterns across accumulators.
The code structure is heavily influenced by the fact DataFusion is implemented using Rust, a new(ish) systems programming language focused on speed and safety. Rust heavily discourages many of the traditional pointer casting “tricks” used in C/C++ hash grouping implementations. The DataFusion aggregation code is almost entirely safe, deviating into unsafe only when necessary. (Rust is a great choice because it makes DataFusion fast, easy to embed, and prevents many crashes and security issues often associated with multi-threaded C/C++ code).
ClickBench results¶
The full results of running the ClickBench queries against the single Parquet file with DataFusion 27.0.0, DataFusion 28.0.0, and DuckDB 0.8.1 are below. These numbers were run on a GCP e2-standard-8 machine with 8 cores and 32 GB of RAM, using the scripts here.
As the industry moves towards data systems assembled from components, it is increasingly important that they exchange data using open standards such as Apache Arrow and Parquet rather than custom storage and in-memory formats. Thus, this benchmark uses a single input Parquet file representative of many DataFusion users and aligned with the current trend in analytics of avoiding a costly load/transformation into a custom storage format prior to query.
DataFusion now reaches near-DuckDB-speeds querying Parquet data. While we don’t plan to engage in a benchmarking shootout with a team that literally wrote Fair Benchmarking Considered Difficult, hopefully everyone can agree that DataFusion 28.0.0 is a significant improvement.
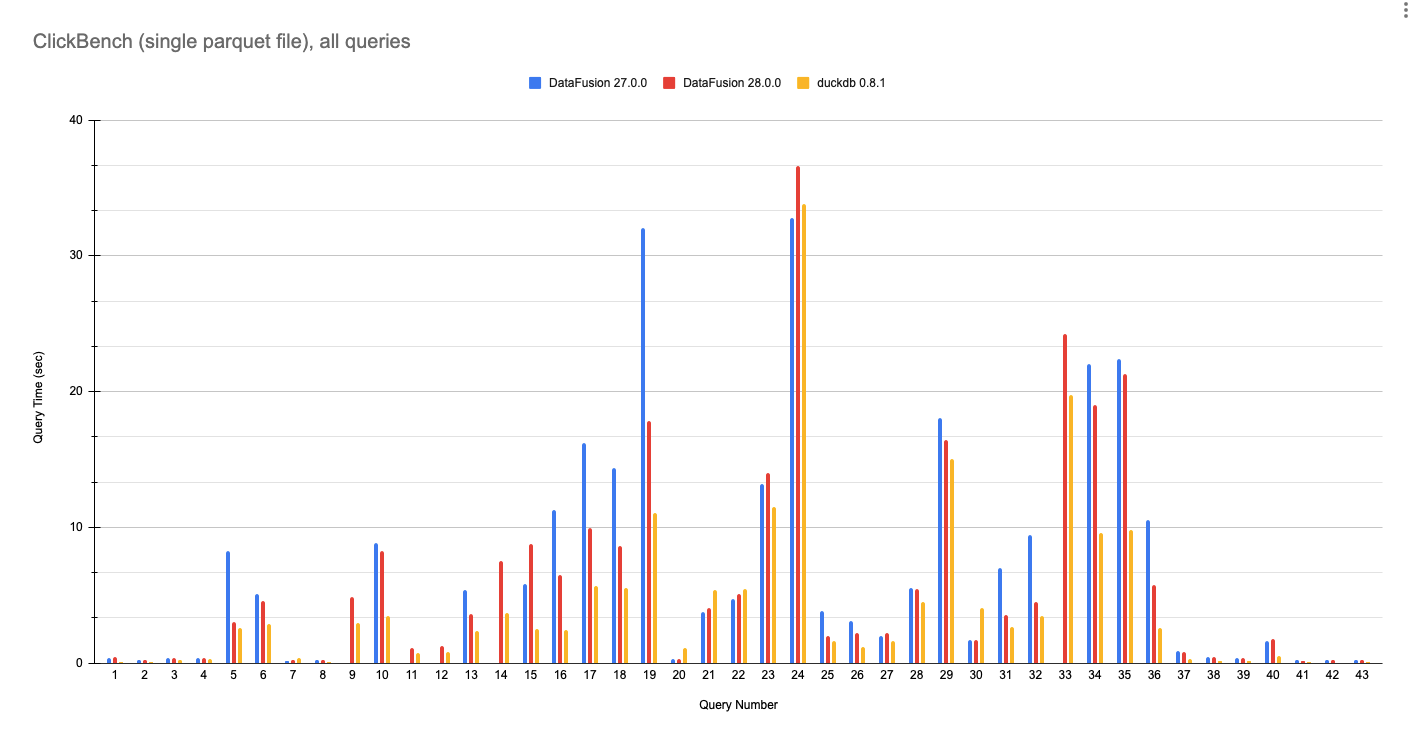
Figure 6: Performance of DataFusion 27.0.0, DataFusion 28.0.0, and DuckDB 0.8.1 on all 43 ClickBench queries against a single hits.parquet file. Lower is better.
Notes¶
DataFusion 27.0.0 was not able to run several queries due to either planner bugs (Q9, Q11, Q12, 14) or running out of memory (Q33). DataFusion 28.0.0 solves those issues.
DataFusion is faster than DuckDB for query 21 and 22, likely due to optimized implementations of string pattern matching.
Conclusion: performance matters¶
Improving aggregation performance by more than a factor of two allows developers building products and projects with DataFusion to spend more time on value-added domain specific features. We believe building systems with DataFusion is much faster than trying to build something similar from scratch. DataFusion increases productivity because it eliminates the need to rebuild well-understood, but costly to implement, analytic database technology. While we’re pleased with the improvements in DataFusion 28.0.0, we are by no means done and are pursuing (Even More) Aggregation Performance. The future for performance is bright.
Acknowledgments¶
DataFusion is a community effort and this work was not possible without contributions from many in the community. A special shout out to sunchao, yjshen, yahoNanJing, mingmwang, ozankabak, mustafasrepo, and everyone else who contributed ideas, reviews, and encouragement during this work.
About DataFusion¶
Apache Arrow DataFusion is an extensible query engine and database toolkit, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion, along with Apache Calcite, Facebook’s Velox, and similar technology are part of the next generation “Deconstructed Database” architectures, where new systems are built on a foundation of fast, modular components, rather than as a single tightly integrated system.
Notes¶
[^1]: SELECT COUNT(*) FROM 'hits.parquet';
[^2]: SELECT COUNT(DISTINCT "UserID") as num_users FROM 'hits.parquet';
[^3]: SELECT COUNT(DISTINCT "SearchPhrase") as num_phrases FROM 'hits.parquet';
[^4]: SELECT COUNT(*) FROM (SELECT DISTINCT "UserID", "SearchPhrase" FROM 'hits.parquet')
[^5]: Full script at hash.py
[^6]: hits_0.parquet, one of the files from the partitioned ClickBench dataset, which has 100,000 rows and is 117 MB in size. The entire dataset has 100,000,000 rows in a single 14 GB Parquet file. The script did not complete on the entire dataset after 40 minutes, and used 212 GB RAM at peak.