Apache DataFusion Comet: Benchmarks Derived From TPC-H#
The following benchmarks were performed on an EKS cluster (r6i.24xlarge instances with EBS storage) with data stored in S3.
Benchmark Results#
Total time to run all queries (lower is better).
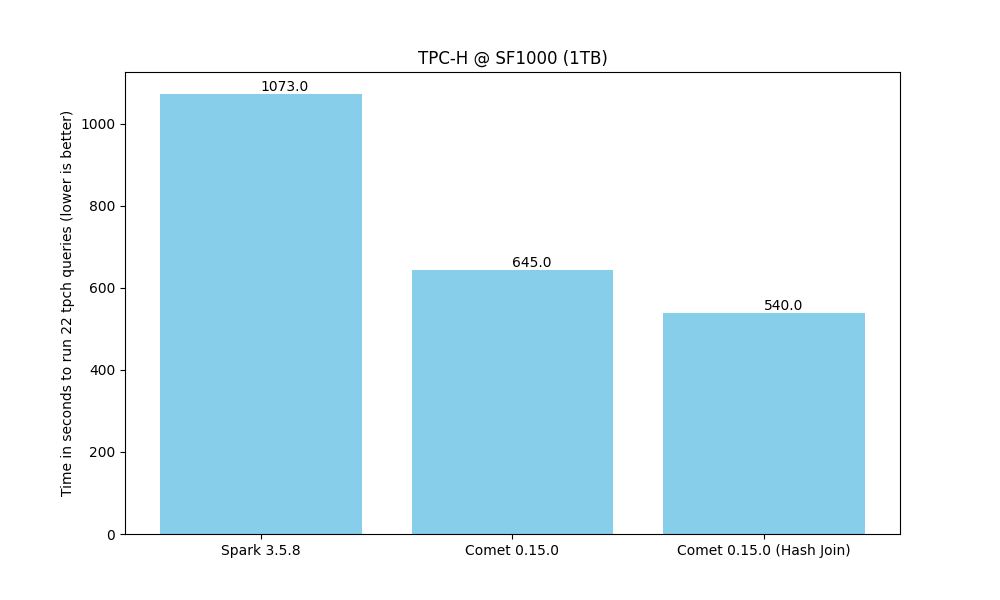
The following charts are based on the tuned run using hash join.
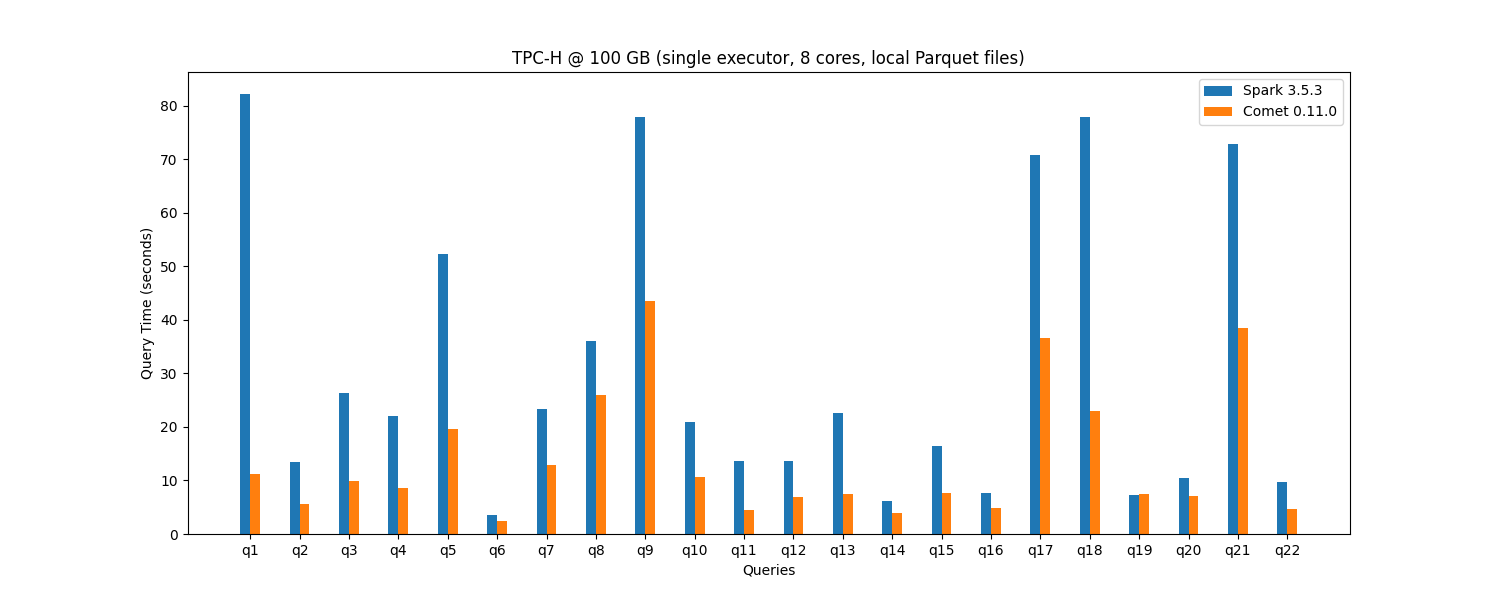
Per-query breakdown showing the relative performance of Spark and Comet.
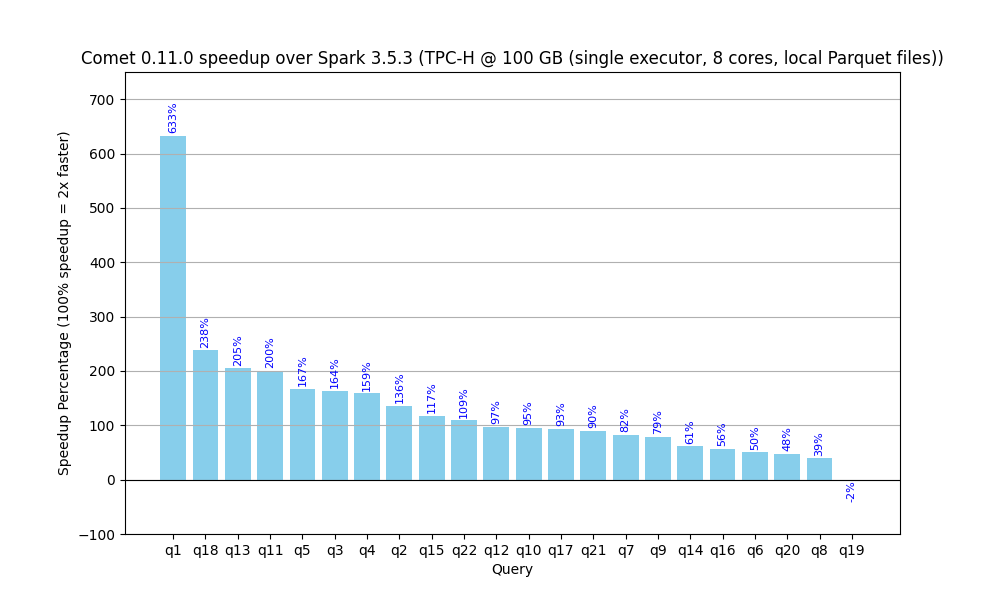
How much Comet accelerates each query in relative terms.
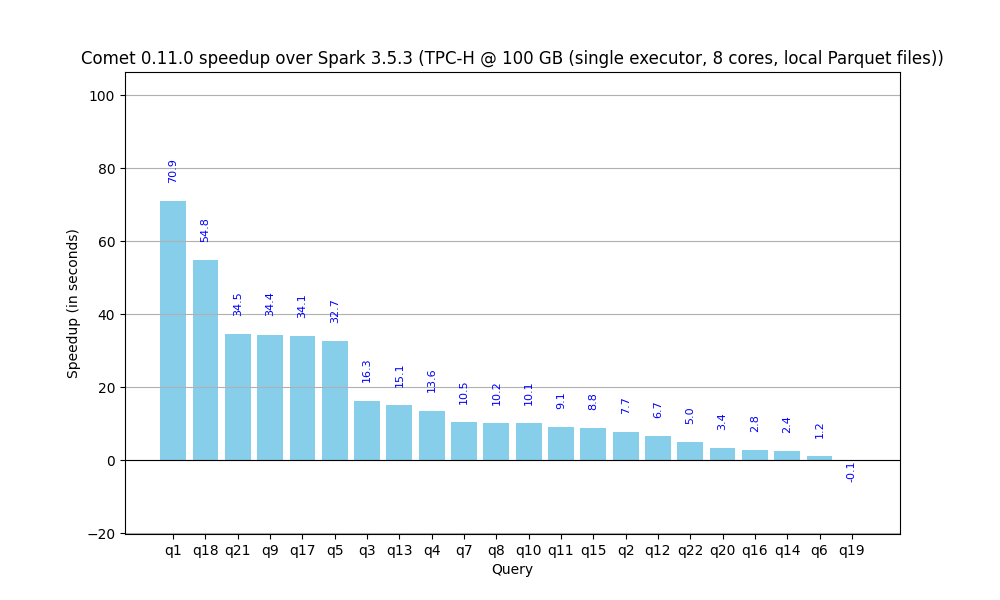
How much Comet accelerates each query in absolute terms.
Configuration#
Common:
spark.executor.instances=32
spark.executor.cores=16
spark.memory.fraction=0.6
spark.memory.storageFraction=0.2
# Kubernetes CPU constraints
spark.kubernetes.executor.request.cores=8
spark.kubernetes.executor.limit.cores=8
Spark:
spark.executor.memory=64G
spark.executor.memoryOverhead=10G
Comet:
spark.executor.memory=32G
spark.executor.memoryOverhead=10G
spark.memory.offHeap.enabled=true
spark.memory.offHeap.size=32G
Comet (Tuned)#
spark.comet.exec.forceShuffledHashJoin=true
spark.comet.memoryPool.fraction=0.8