Apache DataFusion is now the fastest single node engine for querying Apache Parquet files
Posted on: Mon 18 November 2024 by Andrew Lamb, Staff Engineer at InfluxData
I am extremely excited to announce that Apache DataFusion is the fastest engine for querying Apache Parquet files in ClickBench. It is faster than DuckDB, chDB and Clickhouse using the same hardware. It also marks the first time a Rust-based engine holds the top spot, which has previously been held by traditional C/C++-based engines.


Figure 1: 2024-11-16 ClickBench Results for the ‘hot’[^1] run against the
partitioned 14 GB Parquet dataset (100 files, each ~140MB) on a c6a.4xlarge (16
CPU / 32 GB RAM) VM. Measurements are relative (1.x) to results using
different hardware.
Best in class performance on Parquet is now available to anyone. DataFusion’s open design lets you start quickly with a full featured Query Engine, including SQL, data formats, catalogs, and more, and then customize any behavior you need. I predict the continued emergence of new classes of data systems now that creators can focus the bulk of their innovation on areas such as query languages, system integrations, and data formats rather than trying to play catchup with core engine performance.
ClickBench also includes results for proprietary storage formats, which require costly load / export steps, making them useful in fewer use cases and thus much less important than open formats (though the idea of use case specific formats is interesting[^2]).
This blog post highlights some of the techniques we used to achieve this performance, and celebrates the teamwork involved.
A Strong History of Performance Improvements¶
Performance has long been a core focus for DataFusion's community, and speed attracts users and contributors. Recently, we seem to have been even more focused on performance, including in July, 2024 when Mehmet Ozan Kabak, CEO of Synnada, again suggested focusing on performance. This got many of us excited (who doesn’t love a challenge!), and we have subsequently rallied to steadily improve the performance release on release as shown in Figure 2.

Figure 2: ClickBench performance improved over 30% between DataFusion 34 (released Dec. 2023) and DataFusion 43 (released Nov. 2024).
Like all good optimization efforts, ours took sustained effort as DataFusion ran out of single 2x performance improvements several years ago. Working together our community of engineers from around the world[^3] and all experience levels[^4] pulled it off (check out this discussion to get a sense). It may be a "hobo sandwich" [^5], but it is a tasty one!
Of course, most of these techniques have been implemented and described before, but until now they were only available in proprietary systems such as Vertica, DataBricks Photon, or Snowflake or in tightly integrated open source systems such as DuckDB or ClickHouse which were not designed to be extended.
StringView¶
Performance improved for all queries when DataFusion switched to using Arrow
StringView. Using StringView “just” saves some copies and avoids one memory
access for certain comparisons. However, these copies and comparisons happen to
occur in many of the hottest loops during query processing, so optimizing them
resulted in measurable performance improvements.
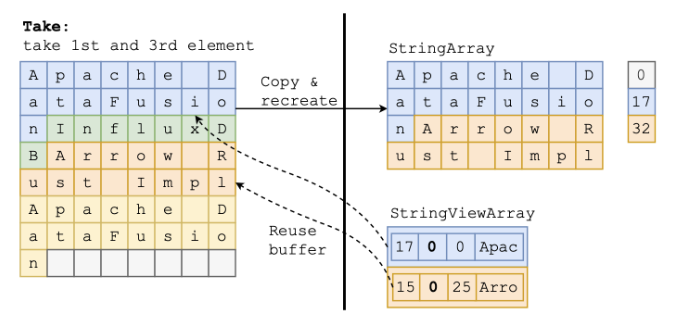
Figure 3: Figure from Using StringView / German Style Strings to Make
Queries Faster: Part 1 showing how StringView saves copying data in many cases.
Using StringView to make DataFusion faster for ClickBench required substantial careful, low level optimization work described in Using StringView / German Style Strings to Make Queries Faster: Part 1 and Part 2. However, it also required extending the rest of DataFusion’s operations to support the new type. You can get a sense of the magnitude of the work required by looking at the 100+ pull requests linked to the epic in arrow-rs (here) and three major epics (here, here and here) in DataFusion.
Here is a partial list of people involved in the project (I am sorry to those whom I forgot)
- Arrow: Xiangpeng Hao (InfluxData’s amazing 2024 summer intern and UW Madison PhD), Yijun Zhao from DataBend Labs, and Raphael Taylor-Davies laid the foundation. RinChanNOW from Tencent and Andrew Duffy from SpiralDB helped push it along in the early days, and Liang-Chi Hsieh, Daniël Heres reviewed and provided guidance.
- DataFusion: Xiangpeng Hao, again charted the initial path and Weijun Huang, Dharan Aditya Lordworms, Jax Liu, wiedld, Tai Le Manh, yi wang, doupache, Jay Zhan , Xin Li and Kaifeng Zheng made it real.
- DataFusion String Function Migration: Trent Hauck organized the effort and set the patterns, Jax Liu made a clever testing framework, and Austin Liu, Dmitrii Bu, Tai Le Manh, Chojan Shang, WeblWabl, Lordworms, iamthinh, Bruce Ritchie, Kaifeng Zheng, and Xin Li bashed out the conversions.
Parquet¶
Part of the reason for DataFusion's speed in ClickBench is reading Parquet files (really) quickly, which reflects invested effort in the Parquet reading system (see Querying Parquet with Millisecond Latency )
The DataFusion ParquetExec (built on the Rust Parquet Implementation) is now the most sophisticated open source Parquet reader I know of. It has every optimization we can think of for reading Parquet, including projection pushdown, predicate pushdown (row group metadata, page index, and bloom filters), limit pushdown, parallel reading, interleaved I/O, and late materialized filtering (coming soon ™️ by default). Some recent work from June recently unblocked a remaining hurdle for enabling late materialized filtering, and conveniently Xiangpeng Hao is working on the final piece (no pressure😅)
Skipping Partial Aggregation When It Doesn't Help¶
Many ClickBench queries are aggregations that summarize millions of rows, a common task for reporting and dashboarding. DataFusion uses state of the art two phase aggregation plans. Normally, two phase aggregation works well as the first phase consolidates many rows immediately after reading, while the data is still in cache. However, for certain “high cardinality” aggregate queries (that have large numbers of groups), the two phase aggregation strategy used in DataFusion was inefficient, manifesting in relatively slower performance compared to other engines for ClickBench queries such as
SELECT "WatchID", "ClientIP", COUNT(*) AS c, ...
FROM hits
GROUP BY "WatchID", "ClientIP" /* <----- 13M Distinct Groups!!! */
ORDER BY c DESC
LIMIT 10;
For such queries, the first aggregation phase does not significantly reduce the number of rows, which wastes significant effort. Eduard Karacharov contributed a dynamic strategy to bypass the first phase when it is not working efficiently, shown in Figure 4.
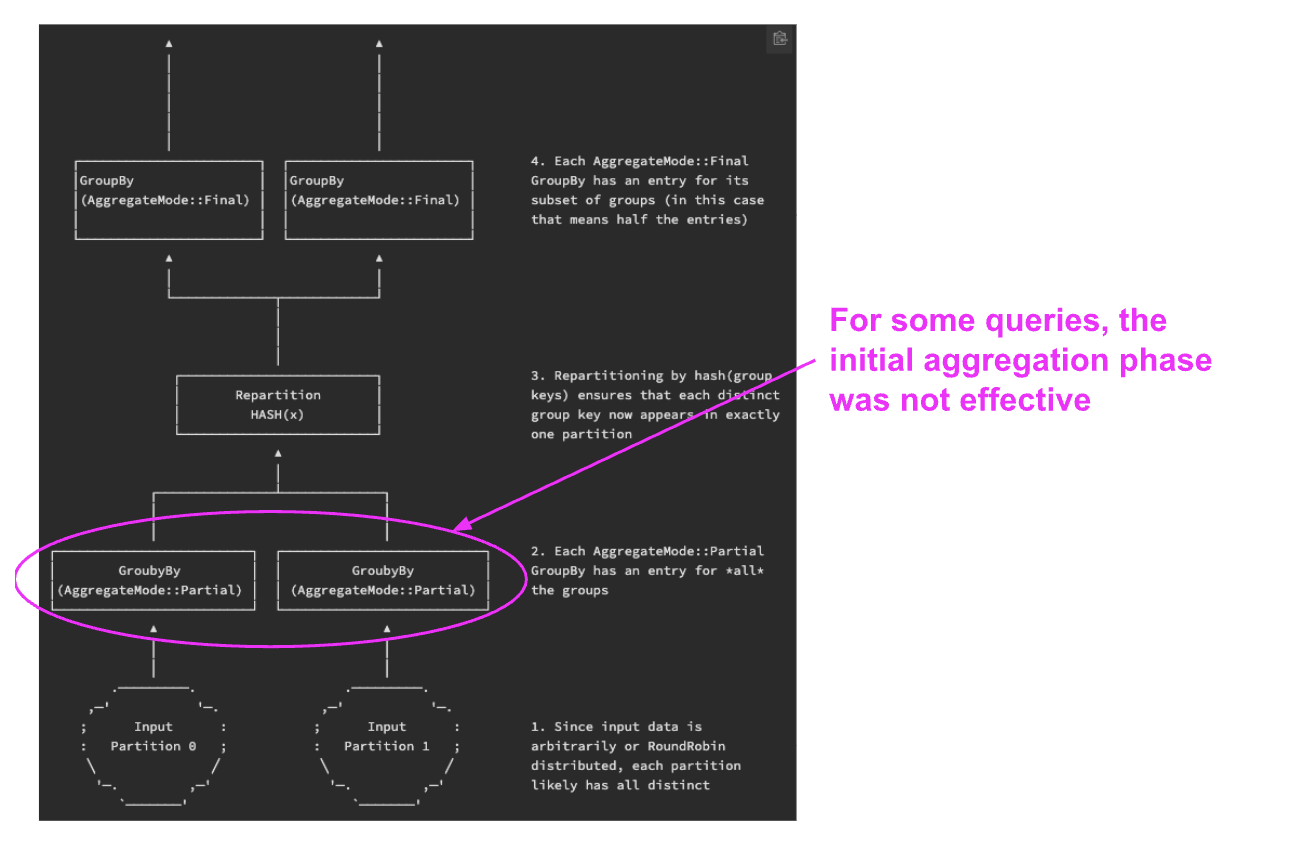
Figure 4: Diagram from DataFusion API docs showing when the multi-phase grouping is not effective
Optimized Multi-Column Grouping¶
Another method for improving analytic database performance is specialized (aka
highly optimized) versions of operations for different data types, which the
system picks at runtime based on the query. Like other systems, DataFusion has
specialized code for handling different types of group columns. For example,
there is special code that handles GROUP BY int_id and different special
code that handles GROUP BY string_id .
When a query groups by multiple columns, it is tricker to apply this technique.
For example GROUP BY string_id, int_id and GROUP BY int_id, string_id have
different optimal structures, but it is not possible to include specialized
versions for all possible combinations of group column types.
DataFusion includes a general Row based mechanism that works for any combination of column types, but this general mechanism copies each value twice as shown in Figure 5. The cost of this copy is especially high for variable length strings and binary data.
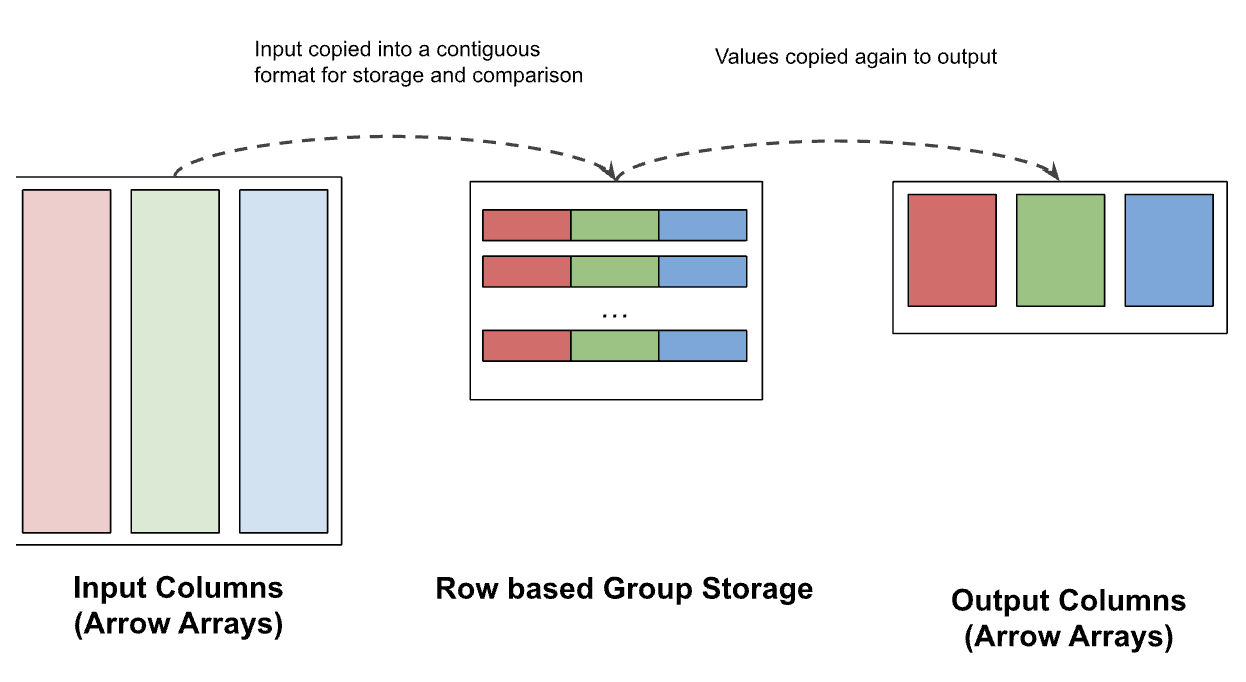
Figure 5: Prior to DataFusion 43.0.0, queries with multiple group columns used Row based group storage and copied each group value twice. This copy consumes a substantial amount of the query time for queries with many distinct groups, such as several of the queries in ClickBench.
Many optimizations in Databases boil down to simply avoiding copies, and this
was no exception. The trick was to figure out how to avoid copies without
causing per-column comparison overhead to dominate or complexity to get out of
hand. In a great example of diligent and disciplined engineering, Jay
Zhan tried several, different approaches until arriving
at the [one shipped in DataFusion 43.0.0], shown in Figure 6.
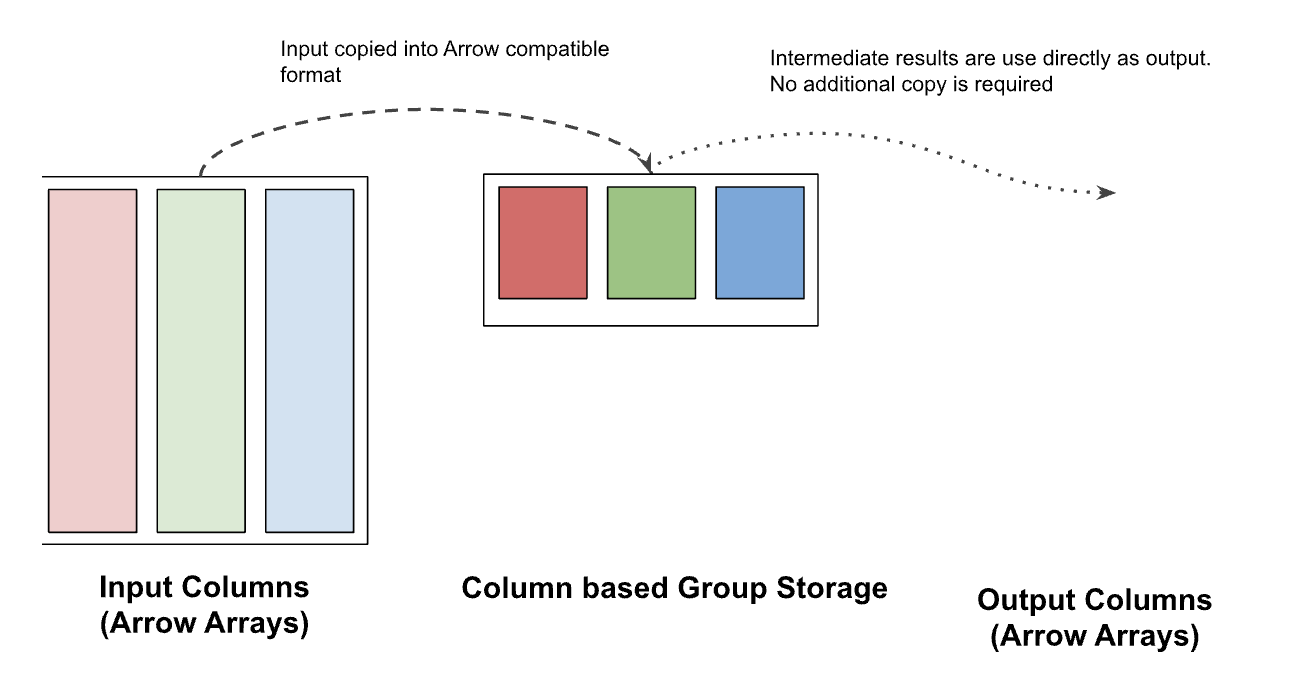
Figure 6: DataFusion 43.0.0’s new columnar group storage copies each group value exactly once, which is significantly faster when grouping by multiple columns.
Huge thanks as well to Emil Ejbyfeldt and Daniël Heres for their help reviewing and to Rachelint (kamille) for reviewing and contributing a faster vectorized append and compare for multiple groups which will be released in DataFusion 44. The discussion on the ticket is another great example of the power of the DataFusion community working together to build great software.
What’s Next 🚀¶
Just as I expect the performance of other engines to improve, DataFusion has several more performance improvements lined up itself:
- Intermediate results blocked management (thanks again Rachelint (kamille)
- Enable parquet filter pushdown by default
We are also talking about what to focus on over the next three months and are always looking for people to help! If you want to geek out (obsess??) about performance and other features with engineers from around the world, we would love you to join us.
Additional Thanks¶
In addition to the people called out above, thanks:
- Patrick McGleenon for running ClickBench and gathering this data (source).
- Everyone I missed in the shoutouts – there are so many of you. We appreciate everyone.
Conclusion¶
I have dreamed about DataFusion being on top of the ClickBench leaderboard for several years. I often watched with envy improvements in systems backed by large VC investments, internet companies, or world class research institutions, and doubted that we could pull off something similar in an open source project with always limited time.
The fact that we have now surpassed those other systems in query performance I think speaks to the power and possibility of focusing on community and aligning our collective enthusiasm and skills towards a common goal. Of course, being on the top in any particular benchmark is likely fleeting as other engines will improve, but so will DataFusion!
I love working on DataFusion – the people, the quality of the code, my interactions and the results we have achieved together far surpass my expectations as well as most of my other software development experiences. I can’t wait to see what people will build next, and hope to see you online.
Notes¶
[^1]: Note that DuckDB is slightly faster on the ‘cold’ run.
[^2]: Want to try your hand at a custom format for ClickBench fame / glory?: Make DataFusion the fastest engine in ClickBench with custom file format
[^3]: We have contributors from North America, South American, Europe, Asia, Africa and Australia
[^4]: Undergraduates, PhD, Junior engineers, and getting-kind-of-crotchety experienced engineers
[^5]: Thanks to Andy Pavlo, I love that nomenclature