Welcome to the Apache DataFusion Blog!
Here you can find the latest updates from DataFusion and related projects.
Posted on: Tue 31 March 2026 by Tim Saucer (rerun.io)
One of DataFusion's greatest strengths is its extensibility. If your data lives
in a custom format, behind an API, or in a system that DataFusion does not
natively support, you can teach DataFusion to read it by implementing a
custom table provider. This post walks through the three layers you …
Posted on: Wed 18 March 2026 by pmc
The Apache DataFusion PMC is pleased to announce version 0.14.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
This release covers approximately eight weeks of development …
Posted on: Fri 30 January 2026 by pmc
The Apache DataFusion PMC is pleased to announce version 0.13.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
This release covers approximately eight weeks of development …
Posted on: Mon 12 January 2026 by Geoffrey Claude (Datadog)
If you embed DataFusion in your product, your users will eventually run SQL that DataFusion does not recognize. Not because the query is unreasonable, but because SQL in practice includes many dialects and system-specific statements.
Suppose you store data as Parquet files on S3 and want users to attach an …
Posted on: Thu 04 December 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.12.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
This release covers approximately four weeks of development …
Posted on: Tue 21 October 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.11.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
This release covers approximately five weeks of development …
Posted on: Sun 21 September 2025 by Tim Saucer(rerun.io), Dewey Dunnington(Wherobots), Andrew Lamb(InfluxData)
Apache DataFusion significantly improves support for user
defined types and metadata. The user defined function APIs let users access
metadata on the input columns to functions and produce metadata in the output.
User defined types == extension types
DataFusion directly uses Apache Arrow's DataTypes as its type system. This
has …
Posted on: Tue 16 September 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.10.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
This release covers approximately ten weeks of development …
Posted on: Wed 10 September 2025 by Adrian Garcia Badaracco (Pydantic), Andrew Lamb (InfluxData)
This blog post introduces the query engine optimization techniques called TopK
and dynamic filters. We describe the motivating use case, how these
optimizations work, and how we implemented them with the Apache DataFusion
community to improve performance by an order of magnitude for some query
patterns.
Motivation and Results
The …
Posted on: Fri 15 August 2025 by Andrew Lamb (InfluxData)
It is a common misconception that Apache Parquet requires (slow) reparsing of
metadata and is limited to indexing structures provided by the format. In fact,
caching parsed metadata and using custom external indexes along with
Parquet's hierarchical data organization can significantly speed up query
processing.
In this blog, I describe …
Posted on: Mon 28 July 2025 by pmc
Introduction
We are proud to announce the release of DataFusion 49.0.0. This blog post highlights some of
the major improvements since the release of DataFusion 48.0.0. The complete list of changes is available in the changelog.
DataFusion continues to focus on enhancing performance, as …
Posted on: Mon 14 July 2025 by Qi Zhu (Cloudera), Jigao Luo (Systems Group at TU Darmstadt), and Andrew Lamb (InfluxData)
It’s a common misconception that Apache Parquet files are limited to basic Min/Max/Null Count statistics and Bloom filters, and that adding more advanced indexes requires changing the specification or creating a new file format. In fact, footer metadata and offset-based addressing already provide everything needed to embed …
Posted on: Tue 01 July 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.9.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
This release covers approximately ten weeks of development …
Posted on: Sun 15 June 2025 by alamb, akurmustafa
Note: this blog was originally published on the InfluxData blog
Introduction
Sometimes Query Optimizers are seen as a sort of black magic, “the most
challenging problem in computer
science,” according to Father
Pavlo, or some behind-the-scenes player. We believe this perception is because:
-
One must implement the rest of a …
Posted on: Sun 15 June 2025 by alamb, akurmustafa
Note, this blog was originally published on the InfluxData blog.
In the first part of this post, we discussed what a Query Optimizer is, what
role it plays, and described how industrial optimizers are organized. In this
second post, we describe various optimizations that are found in Apache
DataFusion and …
Posted on: Tue 06 May 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.8.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
This release covers approximately six weeks of development …
Posted on: Sat 19 April 2025 by Aditya Singh Rathore, Andrew Lamb
Window functions are a powerful feature in SQL, allowing for complex analytical computations over a subset of data. However, efficiently implementing them, especially sliding windows, can be quite challenging. With Apache DataFusion's user-defined window functions, developers can easily take advantage of all the effort put into DataFusion's implementation.
In …
Posted on: Thu 10 April 2025 by Andrew Lamb, Achraf B, and Sean Smith
TLDR: TPC-H SF=100 in 1min using tpchgen-rs vs 30min+ with dbgen.
3 members of the Apache DataFusion community used Rust and open source
development to build tpchgen-rs, a fully open TPC-H data generator over 20x
faster than any other implementation we know of.
It is now possible to create …
Posted on: Thu 20 March 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.7.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims to …
Posted on: Thu 20 March 2025 by Xiangpeng Hao
Editor's Note: This blog was first published on Xiangpeng Hao's blog. Thanks to InfluxData for sponsoring this work as part of his PhD funding.
Apache Parquet has become the industry standard for storing columnar data, and reading Parquet efficiently -- especially from remote storage -- is crucial for query performance.
Apache DataFusion …
Posted on: Mon 17 February 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.6.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims to …
Posted on: Fri 17 January 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.5.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims to …
Posted on: Wed 20 November 2024 by pmc
The Apache DataFusion PMC is pleased to announce version 0.4.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims to …
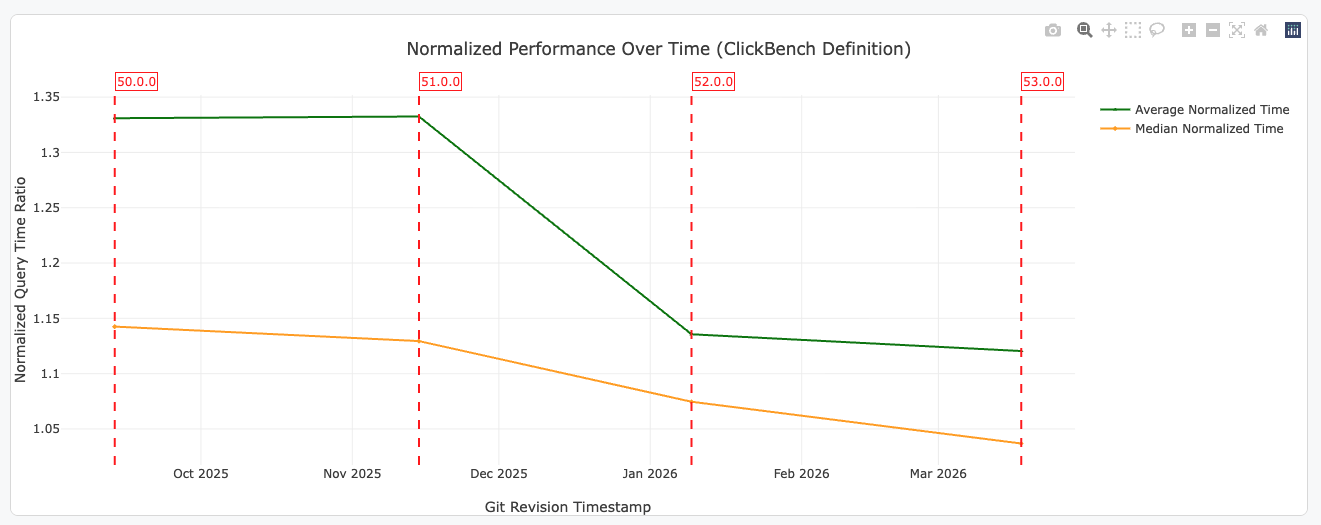
Posted on: Mon 18 November 2024 by Andrew Lamb, Staff Engineer at InfluxData
I am extremely excited to announce that Apache DataFusion is the
fastest engine for querying Apache Parquet files in ClickBench. It is faster
than DuckDB, chDB and Clickhouse using the same hardware. It also marks
the first time a Rust-based engine holds the top spot, which has previously
been …
Posted on: Fri 27 September 2024 by pmc
The Apache DataFusion PMC is pleased to announce version 0.3.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims to …
Posted on: Fri 13 September 2024 by Xiangpeng Hao, Andrew Lamb
Editor's Note: This blog series was first published on the InfluxData blog. Thanks to InfluxData for sponsoring this work as Xiangpeng Hao's summer intern project
In the first post, we discussed the nuances required to accelerate Parquet loading using StringViewArray by reusing buffers and reducing copies.
In this second …
Posted on: Wed 28 August 2024 by pmc
The Apache DataFusion PMC is pleased to announce version 0.2.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims to …
Posted on: Sat 20 July 2024 by pmc
The Apache DataFusion PMC is pleased to announce the first official source release of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for
improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims …
Posted on: Tue 07 May 2024 by pmc
Introduction
TLDR; Apache Arrow DataFusion --> Apache DataFusion
The Arrow PMC and newly created DataFusion PMC are happy to announce that as of
April 16, 2024 the Apache Arrow DataFusion subproject is now a top level
Apache Software Foundation project.
Background
Apache DataFusion is a fast, extensible query engine for building …
Posted on: Wed 06 March 2024 by pmc
Introduction
The Apache Arrow PMC is pleased to announce the donation of the Comet project,
a native Spark SQL Accelerator built on Apache Arrow DataFusion.
Comet is an Apache Spark plugin that uses Apache Arrow DataFusion to
accelerate Spark workloads. It is designed as a drop-in
replacement for Spark's JVM …
Posted on: Sat 05 August 2023 by alamb, Dandandan, tustvold
Aggregating Millions of Groups Fast in Apache Arrow DataFusion
Andrew Lamb, Daniël Heres, Raphael Taylor-Davies,
Note: this article was originally published on the InfluxData Blog
TLDR
Grouped aggregations are a core part of any analytic tool, creating understandable summaries of huge data volumes. Apache Arrow DataFusion’s parallel aggregation capability …
Posted on: Sat 24 June 2023 by pmc
It has been a whirlwind 6 months of DataFusion development since our
last update: the community has grown, many features have been added,
performance improved and we are discussing branching out to our own
top level Apache Project.
Background
Apache Arrow DataFusion is an extensible query engine and database
toolkit …
Posted on: Thu 19 January 2023 by pmc
Introduction
DataFusion is an extensible
query execution framework, written in Rust,
that uses Apache Arrow as its
in-memory format. It is targeted primarily at developers creating data
intensive analytics, and offers mature
SQL support,
a DataFrame API, and many extension points.
Systems based on DataFusion perform very well in benchmarks …
Posted on: Fri 28 October 2022 by pmc
Introduction
Ballista is an Arrow-native distributed SQL query engine implemented in Rust.
Ballista 0.9.0 is now available and is the most significant release since the project was donated to Apache
Arrow in 2021.
This release represents 4 weeks of work, with 66 commits from 14 contributors:
22 Andy …
Posted on: Tue 25 October 2022 by pmc
Introduction
Apache Arrow DataFusion 13.0.0 is released, and this blog contains an update on the project for the 5 months since our last update in May 2022.
DataFusion is an extensible and embeddable query engine, written in Rust used to create modern, fast and efficient data pipelines, ETL …
Posted on: Mon 16 May 2022 by pmc
Introduction
DataFusion is an extensible query execution framework, written in Rust, that
uses Apache Arrow as its in-memory format.
When you want to extend your Rust project with SQL support,
a DataFrame API, or the ability to read and process Parquet, JSON, Avro or CSV data, DataFusion is definitely worth …
Posted on: Mon 21 March 2022 by pmc
Introduction
Apache Arrow DataFusion is an extensible query execution framework, written in Rust, that uses Apache Arrow as its in-memory format.
When you want to extend your Rust project with SQL support, a DataFrame API, or the ability to read and process Parquet, JSON, Avro or CSV data, DataFusion is …
Posted on: Mon 28 February 2022 by pmc
Introduction
DataFusion is an extensible query execution framework, written in Rust, that uses Apache Arrow as its in-memory format.
When you want to extend your Rust project with SQL support, a DataFrame API, or the ability to read and process Parquet, JSON, Avro or CSV data, DataFusion is definitely worth …
Posted on: Fri 19 November 2021 by pmc
Introduction
DataFusion is an embedded
query engine which leverages the unique features of
Rust and Apache
Arrow to provide a system that is high
performance, easy to connect, easy to embed, and high quality.
The Apache Arrow team is pleased to announce the DataFusion 6.0.0 release. This covers …
Posted on: Mon 12 April 2021 by agrove
We are excited to announce that Ballista has been donated
to the Apache Arrow project.
Ballista is a distributed compute platform primarily implemented in Rust, and powered by Apache Arrow. It is built
on an architecture that allows other programming languages (such as Python, C++, and Java) to be supported …
Posted on: Mon 04 February 2019 by agrove
We are excited to announce that DataFusion has been donated to the Apache Arrow project. DataFusion is an in-memory query engine for the Rust implementation of Apache Arrow.
Although DataFusion was started two years ago, it was recently re-implemented to be Arrow-native and currently has limited capabilities but does support …