Apache DataFusion Python 46.0.0 Released
Posted on: Sun 30 March 2025 by timsaucer
We are happy to announce that datafusion-python 46.0.0 has been released. This release brings in all of the new features of the core DataFusion 46.0.0 library. Since the last blog post for datafusion-python 43.1.0, a large number of improvements have been made that can be found in the changelogs.
We highly recommend reviewing the upstream DataFusion 46.0.0 announcement.
Easier file reading¶
In these releases we have introduced two new ways to more easily read files into DataFrames.
PR #982 introduced a series of easier read functions for Parquet, JSON, CSV, and AVRO files. This introduces a concept of a global context that is available by default when using these methods. Now instead of creating a default Session Context and then calling the read methods, you can simply import these read alternative methods and begin working with your DataFrames. Below is an example of how easy to use this new approach is.
from datafusion.io import read_parquet
df = read_parquet(path="./examples/tpch/data/customer.parquet")
PR #980 adds a method for setting up a session context to use URL tables. With this enabled, you can use a path to a local file as a table name. An example of how to use this is demonstrated in the following snippet.
import datafusion
ctx = datafusion.SessionContext().enable_url_table()
df = ctx.table("./examples/tpch/data/customer.parquet")
Registering Table Views¶
DataFusion supports registering a logical plan as a view with a session context. This
allows creating views in one part of your work flow and passinng the session
context to other places where that logical plan can be reused. This is an useful
feature for building up complex workflows and for code clarity. PR #1016 enables this
feature in datafusion-python.
For example, supposing you have a DataFrame called df1, you could use this code snippet
to register the view and then use it in another place:
ctx.register_view("view1", df1)
And then in another portion of your code which has access to the same session context you can retrieve the DataFrame with:
df2 = ctx.table("view1")
Asynchronous Iteration of Record Batches¶
Retrieving a RecordBatch from a RecordBatchStream was a synchronous call, which would
require the end user's code to wait for the data retrieval. This is described in
Issue 974. We continue to support this as a synchronous iterator, but we have also added
in the ability to retrieve the RecordBatch using the Python asynchronous anext
function.
Default ZSTD Compression for Parquet files¶
With PR #981, we change the saving of Parquet files to use zstd compression by default.
Previously the default was uncompressed, causing excessive disk storage. Zstd is an
excellent compression scheme that balances speed and compression ratio. Users can still
save their Parquet files uncompressed by passing in the appropriate value to the
compression argument when calling DataFrame.write_parquet.
UDF Decorators¶
In PRs #1040 and #1061 we add methods to make creating user defined functions
easier and take advantage of Python decorators. With these PRs you can save a step
from defining a method and then defining a udf of that method. Instead you can
simply add the appropriate udf decorator. Similar methods exist for aggregate
and window user defined functions.
@udf([pa.int64(), pa.int64()], pa.bool_(), "stable")
def my_custom_function(
age: pa.Array,
favorite_number: pa.Array,
) -> pa.Array:
pass
uv package management¶
uv is an extremely fast Python package manager, written in Rust. In the previous version
of datafusion-python we had a combination of settings of PyPi and Conda. Instead, we
switch to using uv is our primary method for dependency management.
For most users of DataFusion, this change will be transparent. You can still install
via pip or conda. For developers, the instructions in the repository have been updated.
Code cleanup¶
In an effort to improve our code cleanliness and ensure we are following Python best practices, we use ruff to perform Python linting. Until now we enabled only a portion of the available linters available. In PRs #1055 and #1062, we enable many more of these linters and made code improvements to ensure we are following these recommendations.
Improved Jupyter Notebook rendering¶
Since PR #839 in DataFusion 41.0.0 we have been able to render DataFrames using html in
jupyter notebooks. This is a big improvement over the show command when we have the
ability to render tables. In PR #1036 we went a step further and added in a variety
of features.
- Now html tables are scrollable, vertically and horizontally.
- When data are truncated, we report this to the user.
- Instead of showing a small number of rows, we collect up to 2 megabytes of data to display. Since we have scrollable tables, we are able to make more data available to the user without sacrificing notebook usability.
- We report explicitly when the DataFrame is empty. Previously we would not output anything for an empty table. This indicator is helpful to users to ensure their plans are written correctly. Sometimes a non-output can be overlooked.
- For long output of data, we generate a collapsed view of the data with an option for the user to click on it to expand the data.
In the below view you can see an example of some of these features such as the expandable text and scroll bars.
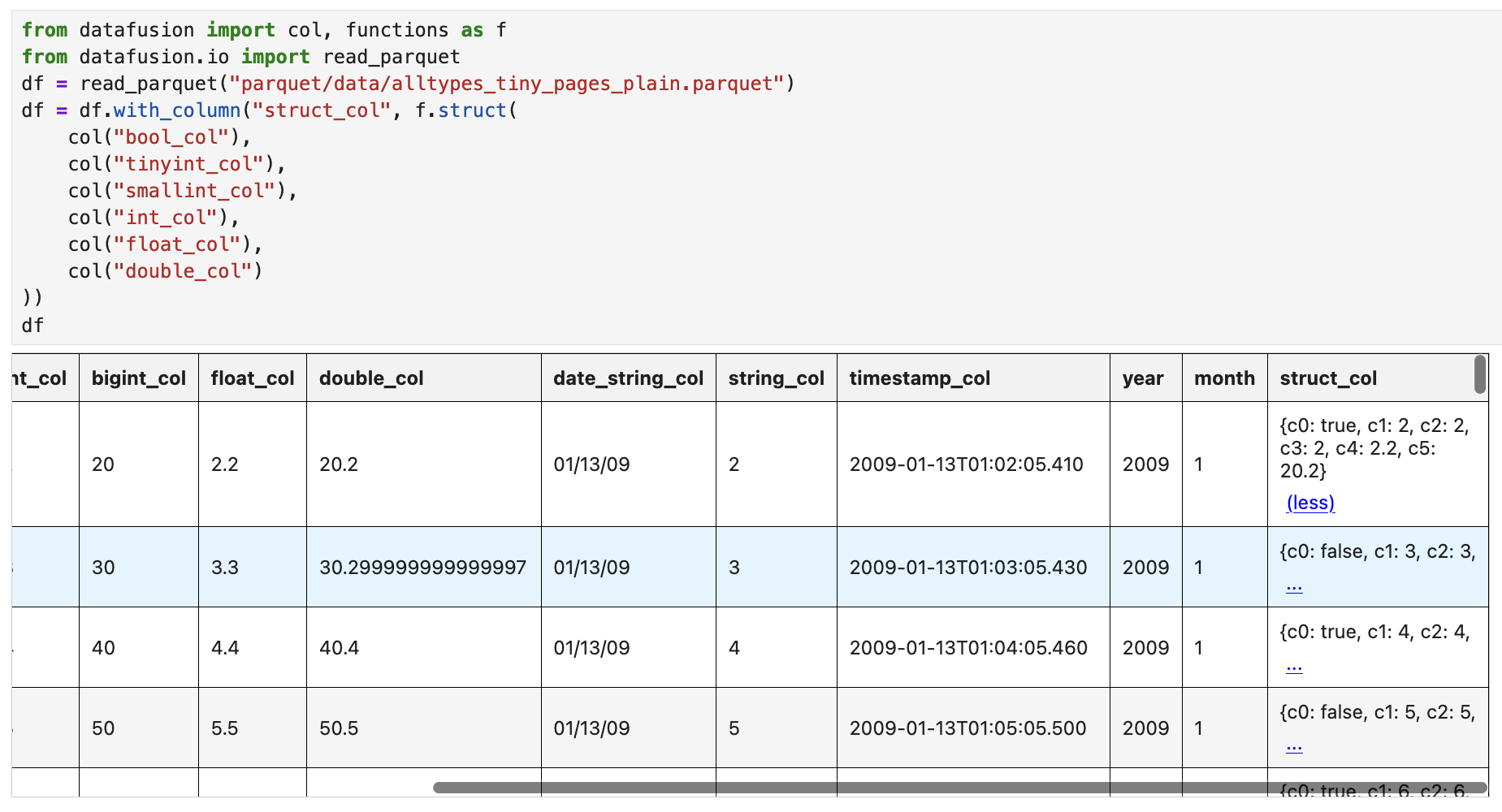
Extension Documentation¶
We have recently added Extension Documentation to the DataFusion in Python website. We have received many requests about how to better understand how to integrate DataFusion in Python with other Rust libraries. To address these questions we wrote an article about some of the difficulties that we encounter when using Rust libraries in Python and our approach to addressing them.
Migration Guide¶
During the upgrade from DataFusion 43.0.0 to DataFusion 44.0.0 as our upstream core dependency, we discovered a few changes were necessary within our repository and our unit tests. These notes serve to help guide users who may encounter similar issues when upgrading.
RuntimeConfigis now deprecated in favor ofRuntimeEnvBuilder. The migration is fairly straightforward, and the corresponding classes have been marked as deprecated. For end users it should be simply a matter of changing the class name.- If you perform a
concatof astring_viewandstring, it will now return astring_viewinstead of astring. This likely only impacts unit tests that are validating return types. In general, it is recommended to switch to usingstring_viewwhenever possible. You can see the blog articles String View Pt 1 and Pt 2 for more information on these performance improvements. - The function
date_partnow returns anint32instead of afloat64. This is likely only impactful to unit tests. - We have upgraded the Python minimum version to 3.9 since 3.8 is no longer officially supported.
Coming Soon¶
There is a lot of excitement around the upcoming work. This list is not comprehensive, but a glimpse into some of the upcoming work includes:
- Reusable DataFusion UDFs: The way user defined functions are currently written in
datafusion-pythonis slightly different from those written for the upstream Rustdatafusion. The core ideas are usually the same, but it means it takes effort for users to re-implement functions already written for Rust projects to be usable in Python. Issue #1017 addresses this topic. Work is well underway to make it easier to expose these user functions through the FFI boundary. This means that the work that already exists in repositories such as those found in the datafusion-contrib project can be easily re-used in Python. This will provide a low effort way to expose significant functionality to the DataFusion in Python community. - Additional table providers: We have work well underway to provide a host of table providers
to
datafusion-pythonincluding: sqlite, duckdb, postgres, odbc, and mysql! In datafusion-contrib #279 we track the progress of this excellent work. Once complete, users will be able topip installthis library and get easy access to all of these table providers. This is another way we are leveraging the FFI work to greatly expand the usability ofdatafusion-pythonwith relatively low effort. - External catalog and schema providers: For users who wish to go beyond table providers and have an entire custom catalog with schema, Issue #1091 tracks the progress of exposing this in Python. With this work, if you have already written a Rust based table catalog you will be able to interface it in Python similar to the work described for the table providers above.
This is only a sample of the great work that is being done. If there are features you would love to see, we encourage you to open an issue and join us as we build something wonderful.
Appreciation¶
We would like to thank everyone who has helped with these releases through their helpful conversations, code review, issue descriptions, and code authoring. We would especially like to thank the following authors of PRs who made these releases possible, listed in alphabetical order by username: @chenkovsky, @CrystalZhou0529, @ion-elgreco, @jsai28, @kevinjqliu, @kylebarron, @kosiew, @nirnayroy, and @Spaarsh.
Thank you!
Get Involved¶
The DataFusion Python team is an active and engaging community and we would love to have you join us and help the project.
Here are some ways to get involved:
-
Learn more by visiting the DataFusion Python project page.
-
Try out the project and provide feedback, file issues, and contribute code.
-
Join us on ASF Slack or the Arrow Rust Discord Server.