What two months with the Comet community got our Spark workload on Amazon EKS
Posted on: Wed 03 June 2026 by Manabu McCloskey (AWS), Vara Bonthu (AWS)
Introduction¶
Apache Spark workloads are some of the most common and cost-intensive jobs running on Kubernetes. Our customers at AWS are always on the lookout for meaningful speedups, since any speedup translates directly into lower bills. That's what got us interested in Apache DataFusion Comet. The local TPC-DS and TPC-H benchmarks looked very good, and we wanted to see how Comet would hold up on a more realistic setup.
When we ran a 3TB TPC-DS benchmark on Spark 3.5.8 on Amazon EKS, Comet was 11% slower than vanilla Spark, and we hit several operational issues along the way that made it hard to keep the cluster running smoothly. We built a reproducible benchmark kit and worked closely with the Comet maintainers to validate fixes as they landed. The same benchmark now runs 32% faster than vanilla Spark on the same setup. The rest of this post walks through the issues we hit and what changed in Comet to address them.
Setup¶
We ran TPC-DS at 3TB scale on Spark 3.5.8 on Amazon EKS, comparing vanilla Spark against Apache DataFusion Comet. Each executor pod was sized at 58 GB of RAM. We ran the same benchmark on three Comet versions, 0.14.0, 0.15.0, and 0.16.0, so we could see how the project progressed across releases. The full cluster topology, Spark configurations, and benchmark scripts we used are documented on the Data on EKS benchmark page.
What we ran into¶
We hit four classes of issues running Comet at scale on Amazon EKS. The first three were operational and the fourth was the source of most of the regression. The Data on EKS benchmark page has full configurations and error traces for each one.
Excessive DNS queries¶
Comet executors were generating up to 5,000 DNS queries per second per pod, roughly 500x what vanilla Spark issued, which pushed us against the Route 53 Resolver per-ENI limit of 1,024 queries per second and triggered intermittent UnknownHostException failures. The root cause was that Comet's native Rust layer was creating a fresh object store instance for every Parquet file read, each with its own HTTP connection pool. The fix in #3802 added a process-wide cache for object stores, which collapsed DNS volume back to vanilla-Spark levels.
Unreliable S3 region detection¶
Without an explicitly configured endpoint region, jobs failed intermittently with Generic S3 error: Failed to resolve region. The cause was the same caching gap as DNS: Comet called the S3 HeadBucket API for every Parquet file read to resolve the region, and those calls were getting throttled under concurrent load. The same fix in #3802 caches the resolved region per bucket, so HeadBucket runs once per bucket and the endpoint.region workaround is no longer required.
High memory footprint¶
Comet consistently used about 67% more memory than vanilla Spark and required a 32 GB off-heap pool to run reliably. The root cause was in shuffle memory sizing: for each Spark task, Comet spun up two concurrent native execution contexts (pre-shuffle and shuffle writer), each allocating its own memory pool at the per-task limit. The fix in #3924 makes the two contexts share a single pool, bringing Comet's memory footprint much closer to vanilla Spark.
Missing DPP support¶
The biggest performance hit came from how Comet handled Dynamic Partition Pruning (DPP). DPP is a Spark optimization that prunes fact-table partitions at runtime based on filters from broadcast dimensions. For star-schema workloads like TPC-DS, DPP is often the difference between scanning 1% of a fact table and scanning all of it.
In Comet 0.14.0, the native Parquet scan didn't support DPP, so any query with a DPP filter would fall back to vanilla Spark for that scan. Falling back was expected, but the fallback path had a planning bug that caused dramatic regressions. The resulting plan ran a Spark scan with a Comet shuffle on top, with the DPP filter effectively dropped, so the Spark scan read every partition. Queries like q25 regressed dramatically as a result.
The fix in #3982 makes shuffle fallback decisions sticky across the two planning passes, removing the regression. Comet 0.16.0 then closes the broader gap by adding native DPP support to the Parquet scan itself, including broadcast exchange reuse so that the dimension table is broadcast only once. The 78 queries that previously fell back went from 30-50% native execution to 80-97% native. The full set of changes is described in the Comet 0.16.0 release announcement on the DataFusion blog.
How we worked with the Comet community¶
The improvement came out of a feedback loop with the Comet maintainers. We brought something they didn't have ready access to: a 3TB workload running on real Amazon EKS infrastructure, with people who could reproduce issues at scale and validate fixes against production-like conditions. The full set of issues we worked through is tracked in #3799.
Some of our setup choices made the reports useful early on. We ran TPC-DS sequentially against vanilla Spark and Comet on the same 12-node cluster (r8gd.12xlarge instances), with a Grafana dashboard tracking DNS query rate, executor memory, network bandwidth, and storage throughput. That's how we caught the DNS spike and the elevated memory baseline before they blocked any jobs. We also used AI-assisted analysis of Spark's event logs and driver logs to narrow down which queries and stages were regressing, which made the bug reports concrete enough that maintainers could act on them without a long back-and-forth.
Each issue we filed bundled those logs together with Comet's explainFallback output, stack traces, and a minimal reproduction. The maintainers had enough to work with from the first message most of the time, which kept the back-and-forth short.
The other side of the loop was experimental builds. When Comet maintainers pushed a candidate fix to a branch, we would build a Comet image off it and run a subset of TPC-DS against our 3TB workload to validate. Most coordination happened through a shared Slack channel and was tracked through GitHub issues, with both sides often responding within minutes during business hours.
Three examples give a sense of the cadence. We reported the DNS query volume and S3 region detection issues on March 25, 2026. Comet maintainers had a fix proposed the next day and merged on March 31. We reported the memory footprint issue the same day, and the shared-pool fix landed on April 13.
The DPP work was the deepest collaboration of the three. While testing experimental builds containing the earlier DPP changes, we hit a separate problem with DPP under AQE that crashed the driver on specific plans. Reproducing it reliably took several iterations, and the fix on the maintainer side took similar care. We reported it on April 9 (#3870) and the fix landed on April 17.
Two things kept the loop fast. The maintainers knew the Comet and DataFusion codebases well enough to turn around fixes within hours of a clean reproduction. We had a stable test cluster and could quickly deploy unreleased branches into it, so validation was never the bottleneck.
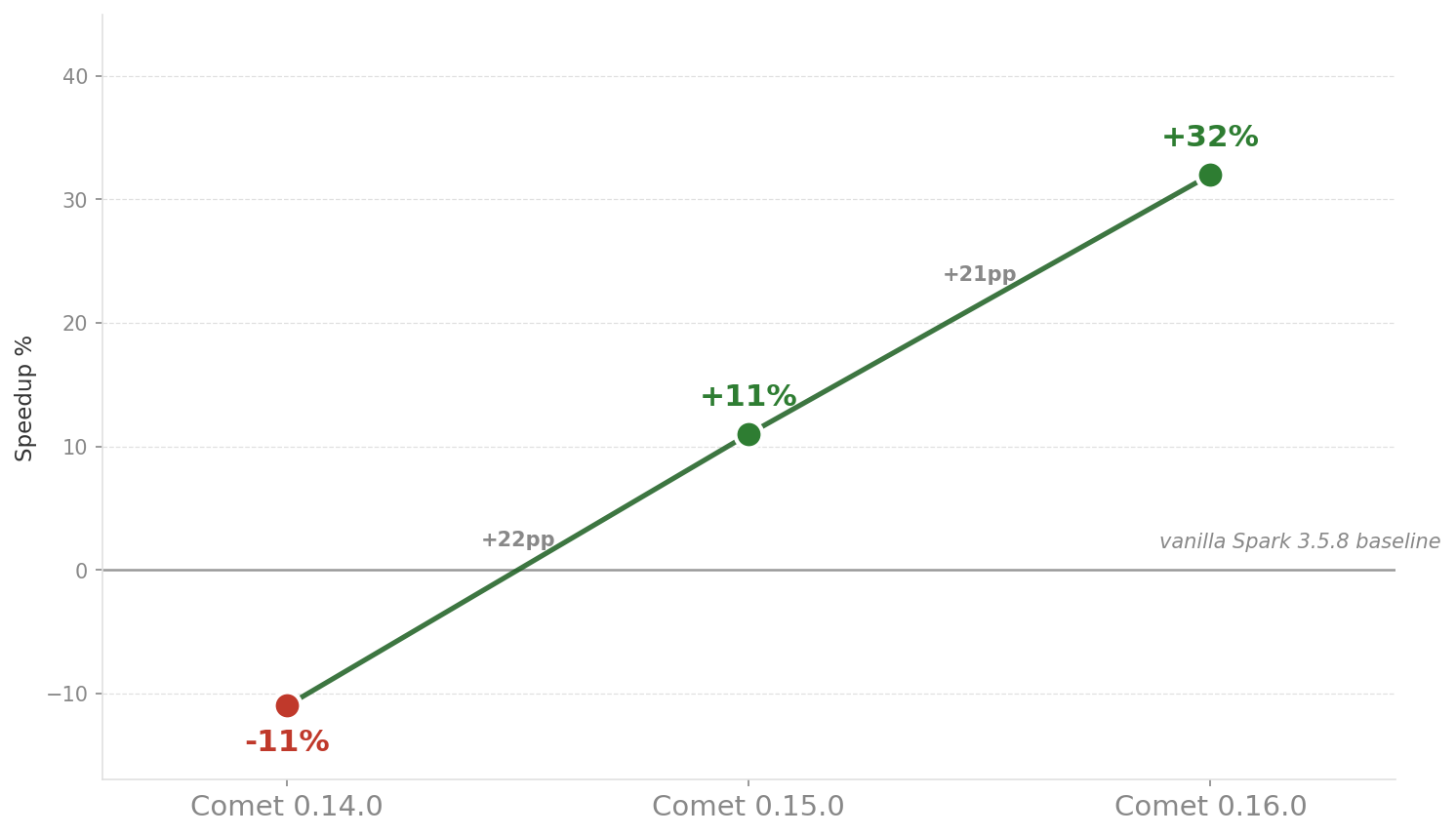
Across roughly two months, every issue we surfaced was fixed upstream. The 0.15.0 release picked up the DNS, S3 region, and memory fixes, which moved the same benchmark from 11% slower than vanilla Spark to 11% faster. The 0.16.0 release added the DPP work and pushed it to 32% faster.
Results¶
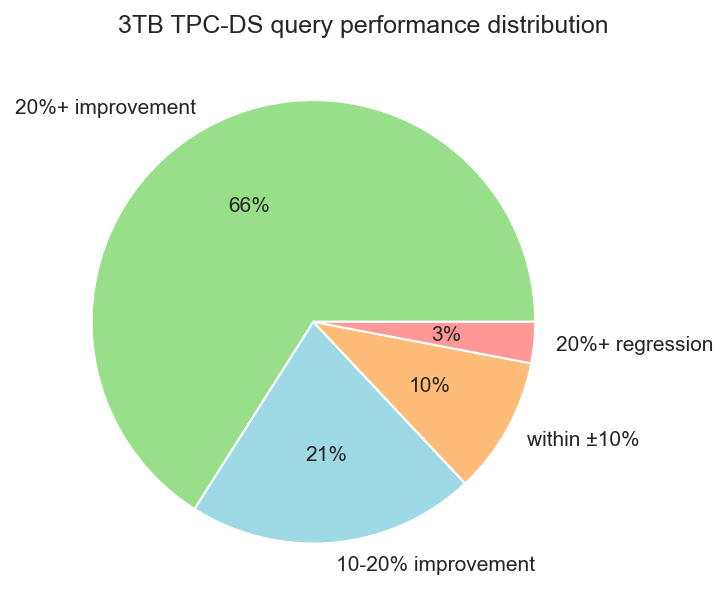
Full per-query results live on the Data on EKS benchmark page. On Parquet, the workload as a whole runs 32% faster than vanilla Spark 3.5.8 on the same cluster. Of the TPC-DS queries, 66% improve by 20% or more, with the largest speedup on q86 at 3.47× faster (+71%).
The DPP fixes drove most of the gains, with the shared memory pool fix improving how reliably Comet runs under tight per-task memory limits.
We also ran the same benchmark against Iceberg tables, where Comet was 37% faster overall and 90% of queries saw 20% or more improvement.
Conclusion¶
The improvement we saw came from staying in close contact with the Comet maintainers over two months of testing, reporting, and validating fixes. Comet 0.16.0 now runs our 3TB TPC-DS workload 32% faster than vanilla Spark on the same EKS cluster.
If you're running Spark on Kubernetes at scale, Comet is worth evaluating against your own workloads. And if you hit issues like the ones we did, file them upstream. Apache DataFusion and Comet are open source projects that improve fastest when users contribute back, whether to datafusion-comet or datafusion.