Apache DataFusion Comet 0.16.0 Release
Posted on: Thu 07 May 2026 by pmc
The Apache DataFusion PMC is pleased to announce version 0.16.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for improved performance and efficiency without requiring any code changes.
This release covers approximately three weeks of development work and is the result of merging 115 PRs from 17 contributors. See the change log for more information.
Expanded Spark 4 Support¶
Spark 4 is a major theme of this release. Comet now ships first-class support for both Spark 4.0.2 and Spark 4.1.1, with dedicated Maven profiles, shim sources, and CI matrices for each.
- Spark 4.1.1: New
spark-4.1Maven profile and shim sources, with Comet's PR test matrix and Spark SQL test suites enabled against Spark 4.1.1. The default Maven profile has been updated to Spark 4.1 / Scala 2.13 to reflect that this is now the primary development target. - Shared 4.x shims: Identical pieces of the Spark 4.0 and 4.1 shims have been consolidated into a shared
spark-4.xsource tree, reducing duplication as more 4.x minor versions land. - Spark 4.0 / JDK 21: Added a Spark 4.0 / JDK 21 CI profile to validate Comet on the JDK most users are expected to deploy with Spark 4.
Adapting to Spark 4 Behavior Changes¶
Spark 4 introduced a number of type, planner, and on-disk format changes relative to Spark 3.x. Several correctness fixes this release bring Comet's behavior in line with these changes:
Varianttype (new in Spark 4.0): Spark 4.0 added a newVariantdata type for semi-structured data. Comet does not yet read the shredded Variant on-disk format natively, and delegates these scans to Spark.- String collation (new in Spark 4.0): Spark 4.0 added collation support for
StringType. Comet's native operators do not yet implement non-default collations, so hash join and sort-merge join reject collated string join keys, and shuffle, sort, and aggregate fall back to Spark when keys carry a non-default collation. - Wider
TimestampNTZTypeusage: Spark 4 usesTimestampNTZType(timestamp without time zone) in more places than 3.x — for example, in expression return types and as the inferred type for some literal forms. Comet adds support this cycle for cast to and fromtimestamp_ntz, cast from string totimestamp_ntz, andunix_timestampoverTimestampNTZTypeinputs. to_jsonandarray_compact(Spark 4.0): Spark 4.0 adjusted output formatting and return-type metadata for these expressions; Comet now matches the new behavior.- BloomFilter V2 (new in Spark 4.1): Spark 4.1 introduced a new BloomFilter binary format with different bit-scattering. Comet now reads this format so that runtime filters produced by Spark 4.1 remain usable in native execution.
- Spark 4.1.1 analyzer refinements: Spark 4.1.1 changed how struct projections handle the case where
every requested child field is missing from the Parquet file, and how
allowDecimalPrecisionLossflows through theDecimalPrecisionrule. Comet now preserves parent-struct nullness in the first case and the storedallowDecimalPrecisionLossflag in the second.
Most of these behavior differences were caught because Comet runs the full Apache Spark SQL test suite
against each supported Spark version — 3.4.3, 3.5.8, 4.0.2, and 4.1.1 — as part of CI. Running Spark's
own correctness tests through Comet's native execution path is what surfaces semantic shifts like
TimestampNTZType propagation, ANSI-driven cast and overflow changes, BloomFilter V2 encoding, and the
4.1.1 analyzer rule changes, often before they show up in user workloads. As more Spark 4.x minor releases
land, this same harness is what gives us confidence that Comet keeps up.
ANSI SQL Semantics¶
Spark 4 enables ANSI SQL semantics by default. ANSI mode changes how arithmetic overflow, invalid casts, division by zero, and similar error conditions are handled, and Spark itself now treats this as the standard configuration rather than an opt-in.
This is a critical area for any Spark accelerator: an engine that falls back to vanilla Spark whenever ANSI is
enabled effectively does not run on Spark 4 by default. Comet implements ANSI semantics for the expressions
it supports natively, including arithmetic overflow checks, ANSI cast behavior, and try_* variants.
Queries running with spark.sql.ansi.enabled=true continue to be accelerated rather than falling back.
See the Comet Compatibility Guide for details on which expressions have full ANSI coverage.
Expanded Adaptive Execution Support¶
Modern Spark plans are adaptive: AQE re-plans stages at runtime, Dynamic Partition Pruning (DPP) prunes
fact-table partitions based on broadcast dimension filters, and ReuseExchange and ReuseSubquery ensure
that a broadcast or subquery referenced in multiple places executes only once. For star-schema workloads,
these mechanisms are not optional. They are often the difference between a query that reads 1% of the fact
table and one that reads all of it.
Prior to 0.16.0, Comet's native scans only partially participated in this machinery. CometNativeScanExec
(the DataFusion-based native Parquet scan) fell back to Spark entirely whenever a DPP filter was present.
CometIcebergNativeScanExec supported non-AQE DPP as of 0.15.0
(#3349), but without broadcast exchange reuse, so
the DPP subquery re-executed the dimension broadcast.
Comet 0.16.0 closes both gaps and aligns the native Parquet and native Iceberg scans on a single DPP and subquery-resolution path:
- Non-AQE DPP for native Parquet, with broadcast exchange reuse
(#4011,
#4037): A new
CometSubqueryBroadcastExecreplaces Spark'sSubqueryBroadcastExecin DPP expressions and wraps aCometBroadcastExchangeExec, soReuseExchangeAndSubquerymatches the join side and the DPP subquery and broadcasts the dimension exactly once. - AQE DPP for native Parquet (#4112): Under AQE,
Spark's
PlanAdaptiveDynamicPruningFilterscannot match Comet's broadcast hash join and would otherwise rewrite DPP toTrueLiteral, disabling pruning. 0.16.0 interceptsSubqueryAdaptiveBroadcastExecbefore Spark's rule runs, and applies Spark's decision tree in a Comet-aware rule that searches both the current stage and the root plan for a reusable broadcast. DPP subqueries are registered in AQE's sharedsubqueryCacheso cross-plan DPP (for example, a main query and a scalar subquery referencing the same dimension) deduplicates correctly. A narrower tagging-based fallback covers Spark 3.4, which lacks theinjectQueryStageOptimizerRuleextension point. - AQE DPP broadcast reuse for native Iceberg
(#4215): Lifts
runtimeFiltersto a top-level constructor field onCometIcebergNativeScanExec(mirroringBatchScanExec), so Spark's expression-rewrite passes can see and convert the DPP subquery. The sameCometSubqueryBroadcastExecmachinery from the Parquet path now handles the Iceberg case. - Scalar subquery pushdown and AQE subquery reuse
(#4053,
SPARK-43402):
CometNativeScanExecnow participates in scalar subquery pushdown into Parquet data filters, and in AQE-time subquery deduplication via a newCometReuseSubqueryrule that re-applies Spark'sReuseAdaptiveSubqueryalgorithm after Comet's node replacements.
Measured impact on TPC-DS: 78 queries previously fell back to Spark whenever DPP filters were planned, running 30–50% natively. With native DPP in 0.16.0, the same queries run 80–97% natively. Representative examples:
| Query | Before | After |
|---|---|---|
| q1 | 36% | 96% |
| q4 | 31% | 95% |
| q31 | 31% | 95% |
| q74 | 32% | 95% |
| q92 | 36% | 95% |
Several Spark SQL DPP tests that Comet previously skipped are re-enabled to guarantee Spark compatibility and prevent regressions.
Improved TPC-DS Benchmark Results¶
TPC-DS performance increased significantly compared to the 0.15.0 release and Comet is now very close to 2x faster than Spark.
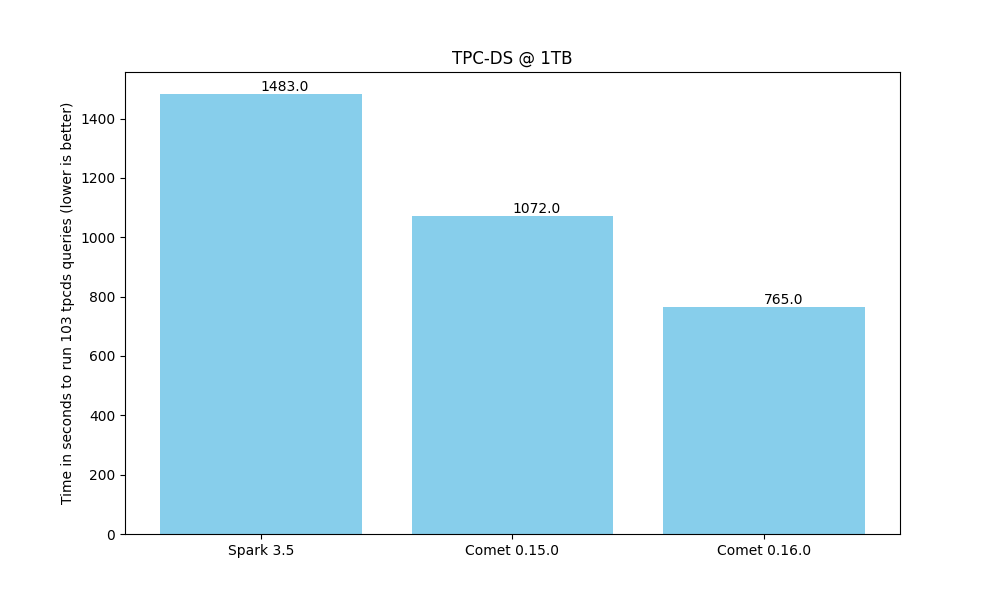
See the Comet Benchmarking Guide for more details about these benchmark results.
Other Key Features¶
Hash Join Improvements¶
BuildRight+LeftAnti(#4073): Regular hash joins now support theBuildRight+LeftAnticombination, eliminating a common fallback path. Tests previously gated onInjectRuntimeFilterSuiteissues have been re-enabled.
Aggregation¶
PartialMergeaggregation mode (#4003): ThePartialMergemode is now executed natively, allowing more multi-stage aggregation plans to remain in Comet without falling back to Spark.collect_set(#3954): Native support for thecollect_setaggregate.
New Expression Support¶
This release adds native support for the following Spark expressions:
- Math:
Pi,Cbrt,Acosh,Asinh,Atanh,ToDegrees,ToRadians - Date/time:
timestamp_seconds,unix_timestampwithTimestampNTZType - String / URL:
url_encode,url_decode,try_url_decode,str_to_map - Array / map:
arrays_zip,array_position,array_union,array_distinct,arrays_overlap,MapSort(Spark 4.0) - Cast: string to
timestamp_ntz, cast to and fromtimestamp_ntz
array_insert and array_compact have been audited and promoted to Compatible.
Object Storage¶
- OpenDAL 0.56.0: Picks up the latest OpenDAL release, including upstream object-store fixes.
- Profile credential chain:
ProfileCredentialsProvideris now mapped to the AWS profile credential chain, matching the credential resolution behavior users expect.
Native Scan Improvements¶
- Parquet field ID matching: The
native_datafusionscan now supports field-ID-based column resolution, matching Spark's behavior for files written with field IDs. - Schema-mismatch errors:
native_datafusionnow throwsSchemaColumnConvertNotSupportedExceptionon schema mismatch, allowing Spark's standard error handling to engage. - Stricter type validation: The
native_datafusionscan now detects incompatible decimal precision/scale and string/binary columns read as numeric, and delegates these reads to Spark.
Metrics and Observability¶
- Spark UI task output metrics: Native execution now reports task output metrics through the standard Spark UI path.
- Iceberg input metrics: Task-level
bytesReadis now reported for the Iceberg native scan, matching Comet's native Parquet scan. - Shuffle encode time: Shuffle operations now track encode time as a separate metric, making it easier to attribute shuffle cost.
Stability and Correctness¶
- Substring with negative start index: Fixed a Spark-incompatibility in
substringfor negative indices. - Strict floating-point comparison:
RangePartitioningnow honorsstrictFloatingPoint, ensuring NaN and ±0.0 are partitioned consistently with Spark. - Broadcast / AQE coalescing: Broadcast exchanges now bypass AQE partition coalescing, fixing plans that could otherwise be coalesced into invalid shapes.
- JNI: JNI local frame management has been hardened with explicit error handling.
- Shuffle fallback logic: Shuffle fallback decisions have been improved, with a new config to gate conversion of Spark shuffle to Comet shuffle when the child plan is non-Comet, and a fix to avoid redundant columnar shuffle when both parent and child are non-Comet.
Compatibility¶
Supported platforms include:
- Spark 3.4.3 with Java 11/17 and Scala 2.12/2.13
- Spark 3.5.8 with Java 11/17 and Scala 2.12/2.13
- Spark 4.0.2 with Java 17 and Scala 2.13
- Spark 4.1.1 with Java 17 and Scala 2.13
See the Spark Version Compatibility page for known limitations specific to each version.
This release continues to build on DataFusion 53.1 and Arrow 58.1.
Get Started with Comet 0.16.0¶
Ready to try it out? Follow the Comet 0.16.0 Installation Guide to get up and running, then point Comet at your existing Spark workloads — including Spark 4 with ANSI mode enabled — and see the speedup for yourself.