tpchgen-rs World’s fastest open source TPC-H data generator, written in Rust
Posted on: Thu 10 April 2025 by Andrew Lamb, Achraf B, and Sean Smith
TLDR: TPC-H SF=100 in 1min using tpchgen-rs vs 30min+ with dbgen.
3 members of the Apache DataFusion community used Rust and open source development to build tpchgen-rs, a fully open TPC-H data generator over 20x faster than any other implementation we know of.
It is now possible to create the TPC-H SF=100 dataset in 72.23 seconds (1.4 GB/s
😎) on a Macbook Air M3 with 16GB of memory, compared to the classic dbgen
which takes 30 minutes1 (0.05GB/sec). On the same machine, it takes less than
2 minutes to create all 36 GB of SF=100 in Apache Parquet format, which takes 44 minutes using DuckDB.
It is finally convenient and efficient to run TPC-H queries locally when testing
analytical engines such as DataFusion.
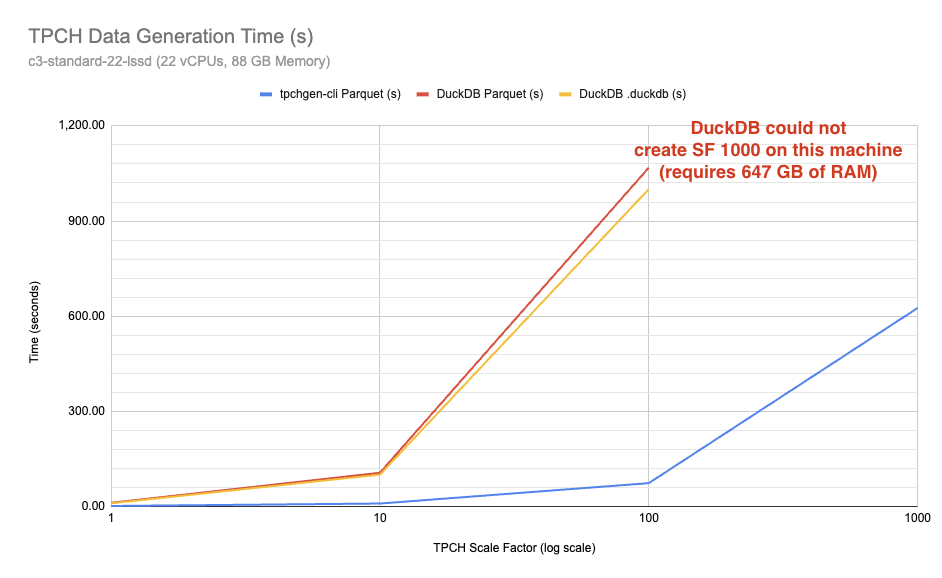
Figure 1: Time to create TPC-H dataset for Scale Factor (see below) 1, 10,
100 and 1000 as 8 individual SNAPPY compressed parquet files using a 22 core GCP
VM with 88GB of memory. For Scale Factor(SF) 100 tpchgen takes 1 minute and 14 seconds and
DuckDB takes 17 minutes and 48 seconds. For SF=1000, tpchgen takes 10
minutes and 26 and uses about 5 GB of RAM at peak, and we could not measure
DuckDB’s time as it requires 647 GB of RAM, more than the 88 GB that was
available on our test machine. The testing methodology is in the
documentation.
This blog explains what TPC-H is, how we ported the vintage C data generator to Rust (yes, RWIR) and optimized its performance over the course of a few weeks of part-time work. We began this project so we can easily generate TPC-H data in Apache DataFusion and GlareDB.
Try it for yourself¶
The tool is entirely open source under the Apache 2.0 license. Visit the tpchgen-rs repository or try it for yourself by run the following commands after installing Rust:
$ cargo install tpchgen-cli
# create SF=1 in classic TBL format
$ tpchgen-cli -s 1
# create SF=10 in Parquet
$ tpchgen-cli -s 10 --format=parquet
What is TPC-H / dbgen?¶
The popular TPC-H benchmark (often referred to as TPCH) helps evaluate the performance of database systems on OLAP queries, the kind used to build BI dashboards.
TPC-H has become a de facto standard for analytic systems. While there are well
known limitations as the data and queries do not well represent many real world
use cases, the majority of analytic database papers and industrial systems still
use TPC-H query performance benchmarks as a baseline. You will inevitably find
multiple results for “TPCH Performance <your favorite database>” in any
search engine.
The benchmark was created at a time when access to high performance analytical systems was not widespread, so the Transaction Processing Performance Council defined a process of formal result verification. More recently, given the broad availability of free and open source database systems, it is common for users to run and verify TPC-H performance themselves.
TPC-H simulates a business environment with eight tables: REGION, NATION,
SUPPLIER, CUSTOMER, PART, PARTSUPP, ORDERS, and LINEITEM. These
tables are linked by foreign keys in a normalized schema representing a supply
chain with parts, suppliers, customers and orders. The benchmark itself is 22
SQL queries containing joins, aggregations, and sorting operations.
The queries run against data created with dbgen, a program
written in a pre C-99 dialect, which generates data in a format called TBL
(example in Figure 2). dbgen creates data for each of the 8 tables for a
certain Scale Factor, commonly abbreviated as SF. Example Scale Factors and
corresponding dataset sizes are shown in Table 1. There is no theoretical upper
bound on the Scale Factor.
103|2844|845|3|23|40177.32|0.01|0.04|N|O|1996-09-11|1996-09-18|1996-09-26|NONE|FOB|ironic accou|
229|10540|801|6|29|42065.66|0.04|0.00|R|F|1994-01-14|1994-02-16|1994-01-22|NONE|FOB|uriously pending |
263|2396|649|1|22|28564.58|0.06|0.08|R|F|1994-08-24|1994-06-20|1994-09-09|NONE|FOB|efully express fo|
327|4172|427|2|9|9685.53|0.09|0.05|A|F|1995-05-24|1995-07-11|1995-06-05|NONE|AIR| asymptotes are fu|
450|5627|393|4|40|61304.80|0.05|0.03|R|F|1995-03-20|1995-05-25|1995-04-14|NONE|RAIL|ve. asymptote|
Figure 2: Example TBL formatted output of dbgen for the LINEITEM table
| Scale Factor | Data Size (TBL) | Data Size (Parquet) |
| 0.1 | 103 Mb | 31 Mb |
| 1 | 1 Gb | 340 Mb |
| 10 | 10 Gb | 3.6 Gb |
| 100 | 107 Gb | 38 Gb |
| 1000 | 1089 Gb | 379 Gb |
Table 1: TPC-H data set sizes at different scale factors for both TBL and Apache Parquet.
Why do we need a new TPC-H Data generator?¶
Despite the known limitations of the TPC-H benchmark, it is so well known that it
is used frequently in database performance analysis. To run TPC-H, you must first
load the data, using dbgen, which is not ideal for several reasons:
- You must find and compile a copy of the 15+ year old C program (for example electrum/tpch-dbgen)
dbgenrequires substantial time (Figure 3) and is not able to use more than one core.- It outputs TBL format, which typically requires loading into your database (for example, here is how to do so in Apache DataFusion) prior to query.
- The implementation makes substantial assumptions about the operating environment, making it difficult to extend or embed into other systems.2
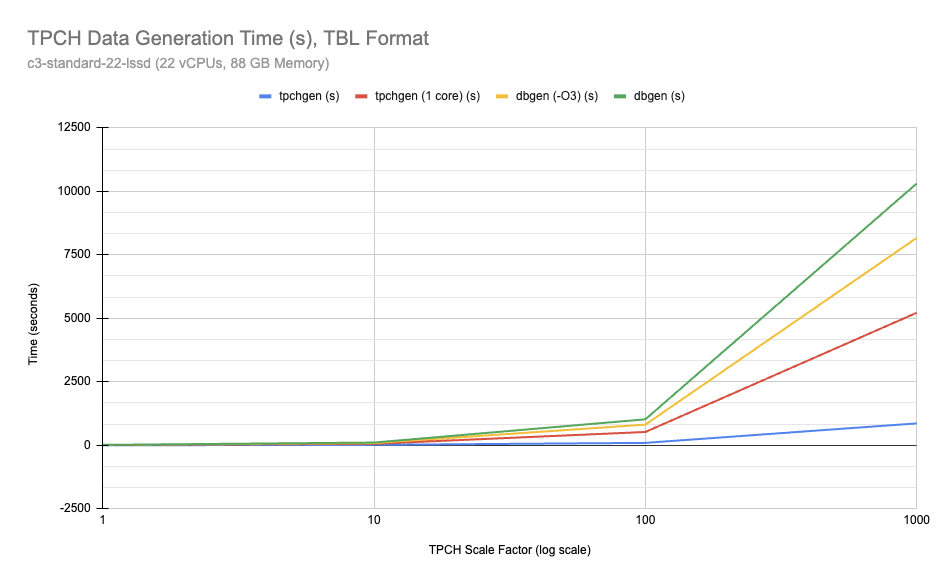
Figure 3: Time to generate TPC-H data in TBL format. tpchgen is
shown in blue. tpchgen restricted to a single core is shown in red. Unmodified
dbgen is shown in green and dbgen modified to use -O3 optimization level
is shown in yellow.
dbgen is so inconvenient and takes so long that vendors often provide
preloaded TPC-H data, for example Snowflake Sample Data, Databricks Sample
datasets and DuckDB Pre-Generated Data Sets.
In addition to pre-generated datasets, DuckDB also provides a TPC-H extension for generating TPC-H datasets within DuckDB. This is so much easier to use than the current alternatives that it leads many researchers and other thought leaders to use DuckDB to evaluate new ideas. For example, Wan Shen Lim explicitly mentioned the ease of creating the TPC-H dataset as one reason the first student project of CMU-799 Spring 2025 used DuckDB.
As beneficial as the DuckDB TPC-H extension is, it is non-ideal for several reasons:
- Creates data in a proprietary format, which requires export to use in other systems.
- Requires significant time (e.g. 17 minutes for Scale Factor 10).
- Requires unnecessarily large amounts of memory (e.g. 71 GB for Scale Factor 10)
The above limitations makes it impractical to generate Scale Factor 100 and above on laptops or standard workstations, though DuckDB offers pre-computed files for larger factors3.
Why Rust?¶
Realistically we used Rust because we wanted to integrate the data generator into Apache DataFusion and GlareDB. However, we also believe Rust is superior to C/C++ due to its comparable performance, but much higher programmer productivity (Figure 4). Productivity in this case refers to the ease of optimizing and adding multithreading without introducing hard to debug memory safety or concurrency issues.
While Rust does allow unsafe access to memory (eliding bounds checking, for example), when required for performance, our implementation is entirely memory safe. The only unsafe code is used to skip UTF8 validation on known ASCII strings.

Figure 4: Lamb Theory of System Language Evolution from Boston University MiDAS Fall 2024 (Data Systems Seminar), recording. Special thanks to @KurtFehlhauer
How: The Journey¶
We did it together as a team in the open over the course of a few weeks. Wan Shen Lim inspired the project by pointing out the benefits of easy TPC-H dataset creation and suggesting we check out a Java port on February 11, 2025. Achraf made first commit a few days later on February 16, and Andrew and Sean started helping on March 8, 2025 and we released version 0.1 on March 30, 2025.
Optimizing Single Threaded Performance¶
Archaf completed the end to end conformance tests, to ensure correctness, and an initial cli check in on March 15, 2025.
On a Macbook Pro M3 (Nov 2023), the initial performance numbers were actually slower than the original Java implementation which was ported 😭. This wasn’t surprising since the focus of the first version was to get a byte of byte compatible port, and knew about the performance shortcomings and how to approach them.
| Scale Factor | Time |
| 1 | 0m10.307s |
| 10 | 1m26.530s |
| 100 | 14m56.986s |
Table 2: Performance of running the initial tpchgen-cli, measured with
time target/release/tpchgen-cli -s $SCALE_FACTOR
With this strong foundation we began optimizing the code using Rust’s low level memory management to improve performance while retaining memory safely. We spent several days obsessing over low level details and implemented a textbook like list of optimizations:
- Avoiding startup overhead,
- not copying strings (many more PRs as well)
- Rust’s zero overhead abstractions for dates
- Static strings (entirely safely with static lifetimes)
- Generics to avoid virtual function call overhead
- Moving lookups from runtime to load time
At the time of writing, single threaded performance is now 2.5x-2.7x faster than the initial version, as shown in Table 3.
| Scale Factor | Time | Times faster |
| 1 | 0m4.079s | 2.5x |
| 10 | 0m31.616s | 2.7x |
| 100 | 5m28.083s | 2.7x |
Table 3: Single threaded tpchgen-cli performance, measured with time target/release/tpchgen-cli -s $SCALE_FACTOR --num-threads=1
Multi-threading¶
Then we applied Rust’s fearless concurrency – with a single, small PR (272 net new lines) we updated the same memory safe code to run with multiple threads and consume bounded memory using tokio for the thread scheduler4.
As shown in Table 4, with this change, tpchgen-cli generates the full SF=100
dataset in 32 seconds (which is 3.3 GB/sec 🤯). Further investigation reveals
that at SF=100 our generator is actually IO bound (which is not the case for
dbgen or duckdb) – it creates data faster than can be written to an SSD.
When writing to /dev/null tpchgen generates the entire dataset in 25 seconds
(4 GB/s).
| Scale Factor | Time | Times faster than initial implementation | Times faster than optimized single threaded |
| 1 | 0m1.369s | 7.3x | 3x |
| 10 | 0m3.828s | 22.6x | 8.2x |
| 100 | 0m32.615s | 27.5x | 10x |
| 100 (to /dev/null) | 0m25.088s | 35.7x | 13.1x |
Table 4: tpchgen-cli (multithreaded) performance measured with time target/release/tpchgen-cli -s $SCALE_FACTOR
Using Rust and async streams, the data generator is also fully streaming: memory
use does not increase with increasing data size / scale factors5. The DuckDB
generator seems to require far more memory than is commonly available on
developer laptops and memory use increases with scale factor. With tpchgen-cli
it is perfectly possible to create data for SF=10000 or larger on a machine with
16GB of memory (assuming sufficient storage capacity).
Direct to parquet¶
At this point, tpchgen-cli could very quickly generate the TBL format.
However, as described above, the TBL is annoying to work with, because
- It has no header
- It is like a CSV but the delimiter is
| - Each line ends with an extra
|delimiter before the newline 🙄 - No system that we know can read them without additional configuration.
We next added support for CSV generation (special thanks @niebayes from Datalayers for finding and fixing bugs) which performs at the same speed as TBL. While CSV files are far more standard than TBL, they must still be parsed prior to load and automatic type inference may not deduce the types needed for the TPC-H benchmarks (e.g. floating point vs Decimal).
What would be far more useful is a typed, efficient columnar format such as Apache Parquet which is supported by all modern query engines. So we made a tpchgen-arrow crate to create Apache Arrow arrays directly and then a small 300 line PR to feed those arrays to the Rust Parquet writer, again using tokio for parallelized but memory bound work.
This approach was simple, fast and scalable, as shown in Table 5. Even though creating Parquet files is significantly more computationally expensive than TBL or CSV, tpchgen-cli creates the full SF=100 parquet format dataset in less than 45 seconds.
| Scale Factor | Time to generate Parquet | Speed compared to tbl generation |
| 1 | 0m1.649s | 0.8x |
| 10 | 0m5.643s | 0.7x |
| 100 | 0m45.243s | 0.7x |
| 100 (to /dev/null) | 0m45.153s | 0.5x |
Table 5: tpchgen-cli Parquet generation performance measured with time
target/release/tpchgen-cli -s $SCALE_FACTOR --format=parquet
Conclusion 👊🎤¶
In just a few days, with some fellow database nerds and the power of Rust, we built something 10x better than what currently exists. We hope it inspires more research into analytical systems using the TPC-H dataset and that people build awesome things with it. For example, Sean has already added on-demand generation of tables to GlareDB. Please consider joining us and helping out at https://github.com/clflushopt/tpchgen-rs.
We met while working together on Apache DataFusion in various capacities. If you are looking for a community of like minded people hacking on databases, we welcome you to come join us. We are in the process of integrating this into DataFusion (see apache/datafusion#14608) if you are interested in helping 🎣
About the Authors:¶
- Andrew Lamb (@alamb) is a Staff Engineer at InfluxData and a PMC member of Apache DataFusion and Apache Arrow.
- Achraf B (@clflushopt) is a Software Engineer at Optable where he works on data infrastructure.
- Sean Smith (@scsmithr) is the founder of GlareDB focused on building a fast analytics database.
Footnotes¶
1: Actual Time: 30:35
2: It is possible to embed the dbgen code, which appears to be the approach taken by DuckDB. This approach was tried in GlareDB (GlareDB/glaredb#3313), but ultimately shelved given the amount of effort needed to adapt and isolate the dbgen code.
3: It is pretty amazing to imagine the machine required to generate SF300 that had 1.8TB (!!) of RAM
4: We tried to use Rayon (see discussion here), but could not easily keep memory bounded.
5: tpchgen-cli memory usage is a function of the number of threads: each thread needs some buffer space