Using Rust async for Query Execution and Cancelling Long-Running Queries
Posted on: Mon 30 June 2025 by Pepijn Van Eeckhoudt
Have you ever tried to cancel a query that just wouldn't stop?
In this post, we'll review how Rust's async programming model works, how DataFusion uses that model for CPU intensive tasks, and how this is used to cancel queries.
Then we'll review some cases where queries could not be canceled in DataFusion and what the community did to resolve the problem.
Understanding Rust's Async Model¶
DataFusion, somewhat unconventionally, uses the Rust async system and the Tokio task scheduler for CPU intensive processing.
To really understand the cancellation problem you first need to be familiar with Rust's asynchronous programming model which is a bit different from what you might be used to from other ecosystems.
Let's go over the basics again as a refresher.
If you're familiar with the ins and outs of Future and async you can skip this section.
Futures Are Inert¶
Rust's asynchronous programming model is built around the Future<T> trait.
In contrast to, for instance, Javascript's Promise or Java's Future a Rust Future does not necessarily represent an actively running asynchronous job.
Instead, a Future<T> represents a lazy calculation that only makes progress when explicitly asked to do so.
This is done by calling the poll method of a Future.
If nobody polls a Future explicitly, it is an inert object.
Calling Future::poll results in one of two options:
Poll::Pendingif the evaluation is not yet complete, most often because it needs to wait for something like I/O before it can continuePoll::Ready<T>when it has completed and produced a value
When a Future returns Pending, it saves its internal state so it can pick up where it left off the next time you poll it.
This internal state management makes Rust's Futures memory-efficient and composable.
Rather than freezing the full call stack leading to a certain point, only the relevant state to resume the future needs to be retained.
Additionally, a Future must set up the necessary signaling to notify the caller when it should call poll again, to avoid a busy-waiting loop.
This is done using a Waker which the Future receives via the Context parameter of the poll function.
Manual implementations of Future are most often little finite state machines.
Each state in the process of completing the calculation is modeled as a variant of an enum.
Before a Future returns Pending, it bundles the data required to resume in an enum variant, stores that enum variant in itself, and then returns.
While compact and efficient, the resulting code is often quite verbose.
The async keyword was introduced to make life easier on Rust programmers.
It provides elegant syntactic sugar for the manual state machine Future approach.
When you write an async function or block, the compiler transforms linear code into a state machine based Future similar to the one described above for you.
Since all the state management is compiler generated and hidden from sight, async code tends to be easier to write initially, more readable afterward, while maintaining the same underlying mechanics.
The await keyword complements async pausing execution until a Future completes.
When you .await a Future, you're essentially telling the compiler to generate code that:
- Polls the
Futurewith the current (implicit) asynchronous context - If
pollreturnsPoll::Pending, save the state of theFutureso that it can resume at this point and returnPoll::Pending - If it returns
Poll::Ready(value), continue execution with that value
From Futures to Streams¶
The futures crate extends the Future model with a trait named Stream.
Stream<Item = T> represents a sequence of values that are each produced asynchronously rather than just a single value.
It's the asynchronous equivalent of Iterator<Item = T>.
The Stream trait has one method named poll_next that returns:
Poll::Pendingwhen the next value isn't ready yet, just like aFuturewouldPoll::Ready(Some(value))when a new value is availablePoll::Ready(None)when the stream is exhausted
Under the hood, an implementation of Stream is very similar to a Future.
Typically, they're also implemented as state machines, the main difference being that they produce multiple values rather than just one.
Just like Future, a Stream is inert unless explicitly polled.
Now that we understand the basics of Rust's async model, let's see how DataFusion leverages these concepts to execute queries.
How DataFusion Executes Queries¶
In DataFusion, the short version of how queries are executed is as follows (you can find more in-depth coverage of this in the DataFusion documentation):
- First the query is compiled into a tree of
ExecutionPlannodes ExecutionPlan::executeis called on the root of the tree.- This method returns a
SendableRecordBatchStream(a pinnedBox<dyn Stream<RecordBatch>>) Stream::poll_nextis called in a loop to get the results
In other words, the execution of a DataFusion query boils down to polling an asynchronous stream.
Like all Stream implementations, we need to explicitly poll the stream for the query to make progress.
The Stream we get in step 2 is actually the root of a tree of Streams that mostly mirrors the execution plan tree.
Each stream tree node processes the record batches it gets from its children.
The leaves of the tree produce record batches themselves.
Query execution progresses each time you call poll_next on the root stream.
This call typically cascades down the tree, with each node calling poll_next on its children to get the data it needs to process.
Here's where the first signs of problems start to show up: some operations (like aggregations, sorts, or certain join phases) need to process a lot of data before producing any output.
When poll_next encounters one of these operations, it might require substantial work before it can return a record batch.
Tokio and Cooperative Scheduling¶
We need to make a small detour now via Tokio's scheduler before we can get to the query cancellation problem. DataFusion makes use of the Tokio asynchronous runtime, which uses a cooperative scheduling model. This is fundamentally different from preemptive scheduling that you might be used to:
- In preemptive scheduling, the system can interrupt a task at any time to run something else
- In cooperative scheduling, tasks must voluntarily yield control back to the scheduler
This distinction is crucial for understanding our cancellation problem.
A task in Tokio is modeled as a Future which is passed to one of the task initiation functions like spawn.
Tokio runs the task by calling Future::poll in a loop until it returns Poll::Ready.
While that Future::poll call is running, Tokio has no way to forcibly interrupt it.
It must cooperate by periodically yielding control, either by returning Poll::Pending or Poll::Ready.
Similarly, when you try to abort a task by calling JoinHandle::abort(), the Tokio runtime can't immediately force it to stop.
You're just telling Tokio: "When this task next yields control, don't call Future::poll anymore."
If the task never yields, it can't be aborted.
The Cancellation Problem¶
With all the necessary background in place, now let's look at how the DataFusion CLI tries to run and cancel a query. The code below is a simplified version of what the CLI actually does:
fn exec_query() {
let runtime: tokio::runtime::Runtime = ...;
let stream: SendableRecordBatchStream = ...;
runtime.block_on(async {
tokio::select! {
next_batch = stream.next() => ...
_ = signal::ctrl_c() => ...,
}
})
}
First the CLI sets up a Tokio runtime instance.
It then reads the query to execute from standard input or file and turns it into a Stream.
Then it calls next on stream which is an async wrapper for poll_next.
It passes this to the select! macro along with a ctrl-C handler.
The select! macro races these two Futures and completes when either one finishes.
The intent is that when you press Ctrl+C, the signal::ctrl_c() Future should complete.
The stream is cancelled when it is dropped as it is inert by itself and nothing will be able to call poll_next again.
But there's a catch: select! still follows cooperative scheduling rules.
It polls each Future in sequence, and if the first one (our query) gets stuck in a long computation, it never gets around to polling the cancellation signal.
Imagine a query that needs to calculate something intensive, like sorting billions of rows.
Unless the sorting Stream is written with care (which the one in DataFusion is), the poll_next call may take several minutes or even longer without returning.
During this time, Tokio can't check if you've pressed Ctrl+C, and the query continues running despite your cancellation request.
A Closer Look at Blocking Operators¶
Let's peel back a layer of the onion and look at what's happening in a blocking poll_next implementation.
Here's a drastically simplified version of a COUNT(*) aggregation - something you might use in a query like SELECT COUNT(*) FROM table:
struct BlockingStream {
// the input: an inner stream that is wrapped
stream: SendableRecordBatchStream,
count: usize,
finished: bool,
}
impl Stream for BlockingStream {
type Item = Result<RecordBatch>;
fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
if self.finished {
// return None if we're finished
return Poll::Ready(None);
}
loop {
// poll the input stream to get the next batch if ready
match ready!(self.stream.poll_next_unpin(cx)) {
// increment the counter if we got a batch
Some(Ok(batch)) => self.count += batch.num_rows(),
// on end-of-stream, create a record batch for the counter
None => {
self.finished = true;
return Poll::Ready(Some(Ok(create_record_batch(self.count))));
}
// pass on any errors verbatim
Some(Err(e)) => return Poll::Ready(Some(Err(e))),
}
}
}
}
How does this code work? Let's break it down step by step:
1. Initial check: We first check if we've already finished processing. If so, we return Ready(None) to signal the end of our stream:
if self.finished {
return Poll::Ready(None);
}
2. Processing loop: If we're not done yet, we enter a loop to process incoming batches from our input stream:
loop {
match ready!(self.stream.poll_next_unpin(cx)) {
// Handle different cases...
}
}
The ready! macro checks if the input stream returned Pending and if so, immediately returns Pending from our function as well.
3. Processing data: For each batch we receive, we simply add its row count to our running total:
Some(Ok(batch)) => self.count += batch.num_rows(),
4. End of input: When the child stream is exhausted (returns None), we calculate our final result and convert it into a record batch (omitted for brevity):
None => {
self.finished = true;
return Poll::Ready(Some(Ok(create_record_batch(self.count))));
}
5. Error handling: If we encounter an error, we pass it along immediately:
Some(Err(e)) => return Poll::Ready(Some(Err(e))),
This code looks perfectly reasonable at first glance.
But there's a subtle issue lurking here: what happens if the input stream always returns Ready and never returns Pending?
In that case, the processing loop will keep running without returning Poll::Pending and thus never yield control back to Tokio's scheduler.
This means we could be stuck in a single poll_next call for quite some time - exactly the scenario that prevents query cancellation from working!
So how do we solve this problem? Let's explore some strategies to ensure our operators yield control periodically.
Unblocking Operators¶
Now let's look at how we can ensure we return Pending every now and then.
Independent Cooperative Operators¶
One simple way to return Pending is using a loop counter.
We do the exact same thing as before, but on each loop iteration we decrement our counter.
If the counter hits zero we return Pending.
The following example ensures we iterate at most 128 times before yielding.
struct CountingSourceStream {
counter: usize
}
impl Stream for CountingSourceStream {
type Item = Result<RecordBatch>;
fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
if self.counter >= 128 {
self.counter = 0;
cx.waker().wake_by_ref();
return Poll::Pending;
}
self.counter += 1;
let batch = ...;
Ready(Some(Ok(batch)))
}
}
If CountingSourceStream was the input for the BlockingStream example above,
the BlockingStream will receive a Pending periodically causing it to yield too.
Can we really solve the cancel problem simply by periodically yielding in source streams?
Unfortunately, no. Let's look at what happens when we start combining operators in more complex configurations. Suppose we create a plan like this.
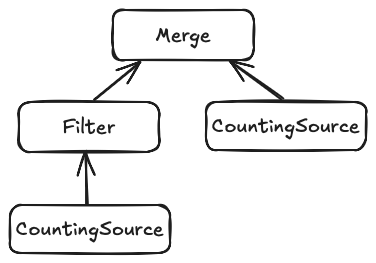
Each CountingSource produces a Pending every 128 batches.
The Filter is a stream that drops a batch every 50 record batches.
Merge is a simple combining operator the uses futures::stream::select to combine two stream.
When we set this stream in motion, the merge operator will poll the left and right branch in a round-robin fashion.
The sources will each emit Pending every 128 batches, but since the Filter drops batches, they arrive out-of-phase at the merge operator.
As a consequence the merge operator will always have the opportunity of polling the other stream when one returns Pending.
The Merge stream thus is an always ready stream, even though the sources are yielding.
If we use Merge as the input to our aggregating operator we're right back where we started.
Coordinated Cooperation¶
Wouldn't it be great if we could get all the operators to coordinate amongst each other?
When one of them determines that it's time to yield, all the other operators agree and start returning Pending as well.
That way our task would be coaxed towards yielding even if it tried to poll many different operators.
Luckily(?), the developers of Tokio ran into the exact same problem described above when network servers were under heavy load and came up with a solution.
Back in 2020, Tokio 0.2.14 introduced a per-task operation budget.
Rather than having individual counters littered throughout the code, the Tokio runtime itself manages a per task counter which is decremented by Tokio resources.
When the counter hits zero, all resources start returning Pending.
The task will then yield, after which the Tokio runtime resets the counter.
To illustrate what this process looks like, let's have a look at the execution of the following query Stream tree when polled in a Tokio task.
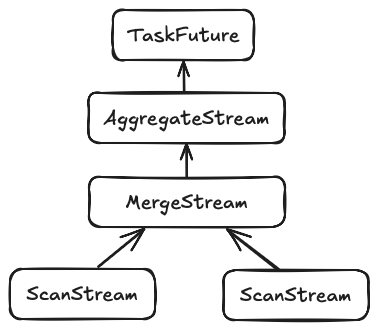
If we assume a task budget of 1 unit, each time Tokio schedules the task would result in the following sequence of function calls.
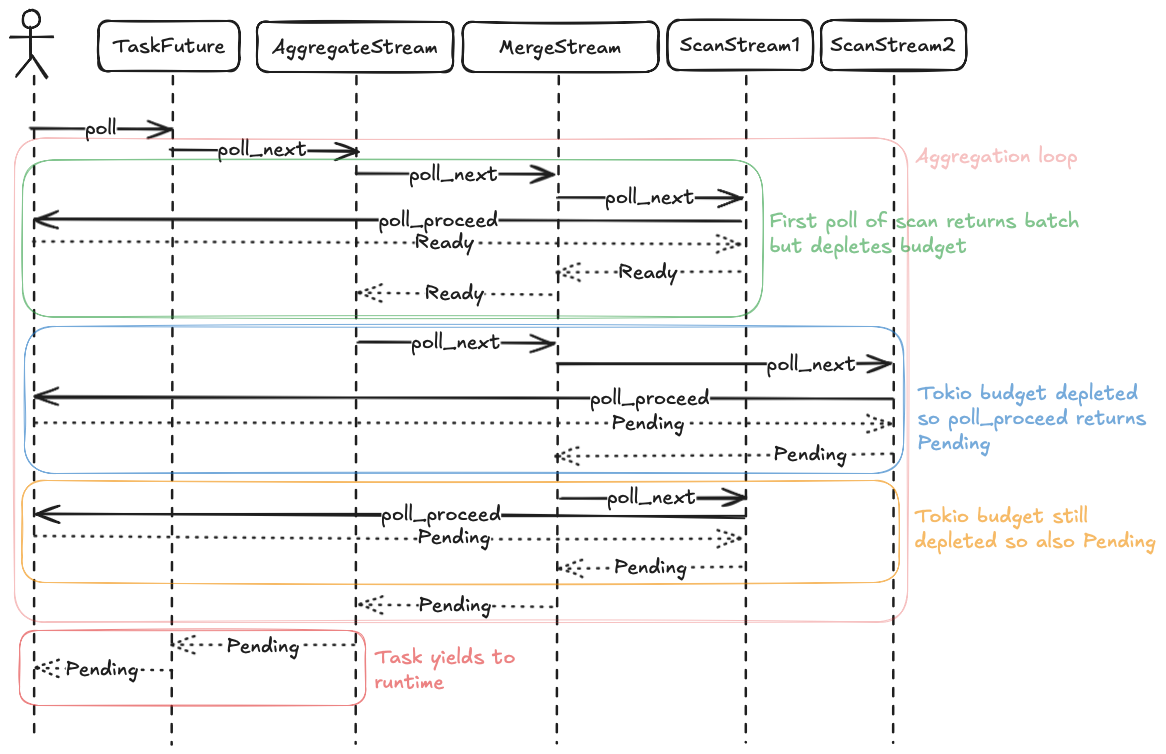
The aggregation stream would try to poll the merge stream in a loop.
The first iteration of the loop consumes the single unit of budget, and returns Ready.
The second iteration polls the merge stream again which now tries to poll the second scan stream.
Since there is no budget remaining Pending is returned.
The merge stream may now try to poll the first source stream again, but since the budget is still depleted Pending is returned as well.
The merge stream now has no other option than to return Pending itself as well, causing the aggregation to break out of its loop.
The Pending result bubbles all the way up to the Tokio runtime, at which point the runtime regains control.
When the runtime reschedules the task, it resets the budget and calls poll on the task Future again for another round of progress.
The key mechanism that makes this work well is the single task budget that's shared amongst all the scan streams.
Once the budget is depleted, no streams can make any further progress without first returning control to tokio.
This causes all possible avenues the task has to make progress to return Pending which results in the task being nudged towards yielding control.
As it turns out DataFusion was already using this mechanism implicitly.
Every exchange-like operator (such as RepartitionExec) internally makes use of a Tokio multiple producer, single consumer Channel.
When calling Receiver::recv for one of these channels, a unit of Tokio task budget is consumed.
As a consequence, query plans that made use of exchange-like operators were
already mostly cancelable.
The plan cancellation bug only showed up when running parts of plans without such operators, such as when using a single core.
Now let's see how we can explicitly implement this budget-based approach in our own operators.
Depleting The Tokio Budget¶
Let's revisit our original BlockingStream and adapt it to use Tokio's budget system.
The examples given here make use of functions from the Tokio coop module that are still internal at the time of writing.
PR #7405 on the Tokio project will make these accessible for external use.
The current DataFusion code emulates these functions as well as possible using has_budget_remaining and consume_budget.
struct BudgetSourceStream {
}
impl Stream for BudgetSourceStream {
type Item = Result<RecordBatch>;
fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
let coop = ready!(tokio::task::coop::poll_proceed(cx));
let batch: Poll<Option<Self::Item>> = ...;
if batch.is_ready() {
coop.made_progress();
}
batch
}
}
The Stream now goes through the following steps:
1. Try to consume budget: the first thing the operator does is use poll_proceed to try to consume a unit of budget.
If the budget is depleted, this function will return Pending.
Otherwise, we consumed one budget unit and we can continue.
let coop = ready!(tokio::task::coop::poll_proceed(cx));
2. Try to do some work: next we try to produce a record batch. That might not be possible if we're reading from some asynchronous resource that's not ready.
let batch: Poll<Option<Self::Item>> = ...;
3. Commit the budget consumption: finally, if we did produce a batch, we need to tell Tokio that we were able to make progress.
That's done by calling the made_progress method on the value poll_proceed returned.
if batch.is_ready() {
coop.made_progress();
}
You might be wondering why the call to made_progress is necessary.
This clever construct makes it easier to manage the budget.
The value returned by poll_proceed will actually restore the budget to its original value when it is dropped unless made_progress is called.
This ensures that if we exit early from our poll_next implementation by returning Pending, that the budget we had consumed becomes available again.
The task that invoked poll_next can then use that budget again to try to make some other Stream (or any resource for that matter) make progress.
Automatic Cooperation For All Operators¶
DataFusion 49.0.0 integrates the Tokio task budget based fix in all built-in source operators. This ensures that going forward, most queries will automatically be cancelable. See the PR for more details.
The design includes:
- A new
ExecutionPlanproperty that indicates if an operator participates in cooperative scheduling or not. - A new
EnsureCooperativeoptimizer rule to inspect query plans and insertCooperativeExecnodes as needed to ensure custom source operators also participate.
These two changes combined already make it very unlikely you'll encounter any query that refuses to stop, even with custom operators.
For those situations where the automatic mechanisms are still not sufficient, there's a new datafusion::physical_plan::coop module
with utility functions that make it easy to adopt cooperative scheduling in your custom operators as well.
Acknowledgments¶
Thank you to Datadobi for sponsoring the development of this feature and to the DataFusion community contributors including Qi Zhu and Mehmet Ozan Kabak.
About DataFusion¶
Apache DataFusion is an extensible query engine toolkit, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion and similar technology are part of the next generation “Deconstructed Database” architectures, where new systems are built on a foundation of fast, modular components, rather than as a single tightly integrated system.
The DataFusion community is always looking for new contributors to help improve the project. If you are interested in learning more about how query execution works, help document or improve the DataFusion codebase, or just try it out, we would love for you to join us.