Embedding User-Defined Indexes in Apache Parquet Files
Posted on: Mon 14 July 2025 by Qi Zhu (Cloudera), Jigao Luo (Systems Group at TU Darmstadt), and Andrew Lamb (InfluxData)
It’s a common misconception that Apache Parquet files are limited to basic Min/Max/Null Count statistics and Bloom filters, and that adding more advanced indexes requires changing the specification or creating a new file format. In fact, footer metadata and offset-based addressing already provide everything needed to embed user-defined index structures within Parquet files without breaking compatibility with other Parquet readers.
Motivating Example: Imagine your data has a Nation column with dozens of distinct values across thousands of Parquet files. You execute:
SELECT AVG(sales_amount)
FROM sales
WHERE nation = 'Singapore'
GROUP BY year;
Relying on the min/max statistics from the Parquet format will be ineffective at pruning files when Nation spans "Argentina" through "Zimbabwe". Instead of relying on a Bloom Filter, you may want to store a list of every distinct Nation value in the file near the end. At query time, your engine will read that tiny list and skip any file that does not contain 'Singapore'. This special distinct value index can yield dramatically better file‑pruning performance for your engine, all while preserving full compatibility with standard Parquet readers.
In this post, we review how indexes are stored in the Apache Parquet format, explain the mechanism for storing user-defined indexes, and finally show how to read and write a user-defined index using Apache DataFusion.
Introduction¶
Apache Parquet is a popular columnar file format with well understood and production grade libraries for high‑performance analytics. Features like efficient encodings, column pruning, and predicate pushdown work well for many common query patterns. Apache DataFusion includes a highly optimized Parquet implementation and has excellent performance in general. However, some production query patterns require more than the statistics included in the Parquet format itself1.
Many systems improve query performance using external indexes or other metadata in addition to Parquet. For example, Apache Iceberg's Scan Planning uses metadata stored in separate files or an in memory cache, and the parquet_index.rs and advanced_parquet_index.rs examples in the DataFusion repository use external files for Parquet pruning (skipping).
External indexes are powerful and widespread, but they have some drawbacks:
- Increased Cost and Operational Complexity: You need additional files and systems as well as the original Parquet.
- Synchronization Risks: The external index may become out of sync with the Parquet data if you do not manage it carefully.
Proponents have even cited these drawbacks as justification for new file formats, such as Microsoft's Amudai.
However, Parquet is extensible with user-defined indexes: Parquet tolerates unknown bytes within the file body and permits arbitrary key/value pairs in its footer metadata. These two features enable embedding user-defined indexes directly in the file—no extra files, no format forks, and no compatibility breakage.
Parquet File Anatomy & Standard Index Structures¶
Logically, Parquet files contain row groups, each with column chunks, which in turn contain data pages. Physically, a Parquet file is a sequence of bytes with a Thrift-encoded footer metadata containing metadata about the file structure. The footer metadata includes the schema, row groups, column chunks, and other metadata required to read the file.
The Parquet format includes three main types2 of optional index structures:
-
Min/Max/Null Count Statistics for each chunk in a row group. Engines use these to quickly skip row groups that do not match a query predicate.
-
Page Index: Offsets, sizes, and statistics for each data page. Engines use these to quickly locate data pages without scanning all pages for a column chunk.
-
Bloom Filters: Data structure to quickly determine if a value is present in a column chunk without scanning any data pages. Particularly useful for equality and
INpredicates.
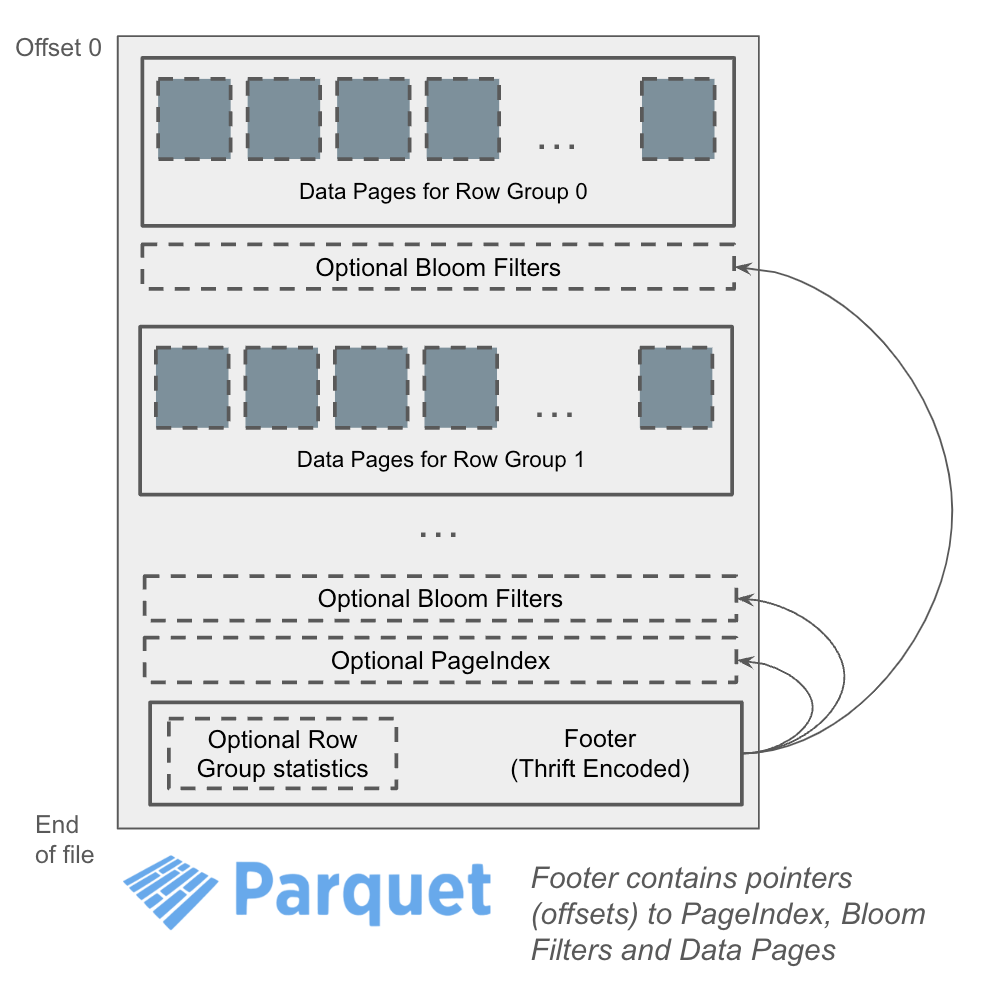
Figure 1: Parquet file layout with standard index structures (as written by arrow-rs).
Only the Min/Max/Null Count Statistics are stored inline in the Parquet footer metadata. The Page Index and Bloom Filters are typically stored in the file body before the Thrift-encoded footer metadata. The locations of these index structures are recorded in the footer metadata, as shown in Figure 1. Parquet readers that do not understand these structures simply ignore them.
Modern Parquet writers create these indexes automatically and provide APIs to control their generation and placement. For example, the Rust Parquet Library provides Parquet WriterProperties, EnabledStatistics, and BloomFilterPosition.
Embedding User Defined Indexes in Parquet Files¶
Embedding user-defined indexes in Parquet files is straightforward and follows the same principles as standard index structures6:
-
Serialize the index into a binary format and write it into the file body before the Thrift-encoded footer metadata.
-
Record the index location in the footer metadata as a key/value pair, such as
"my_index_offset" -> "<byte-offset>".
Figure 2 shows the resulting file layout.
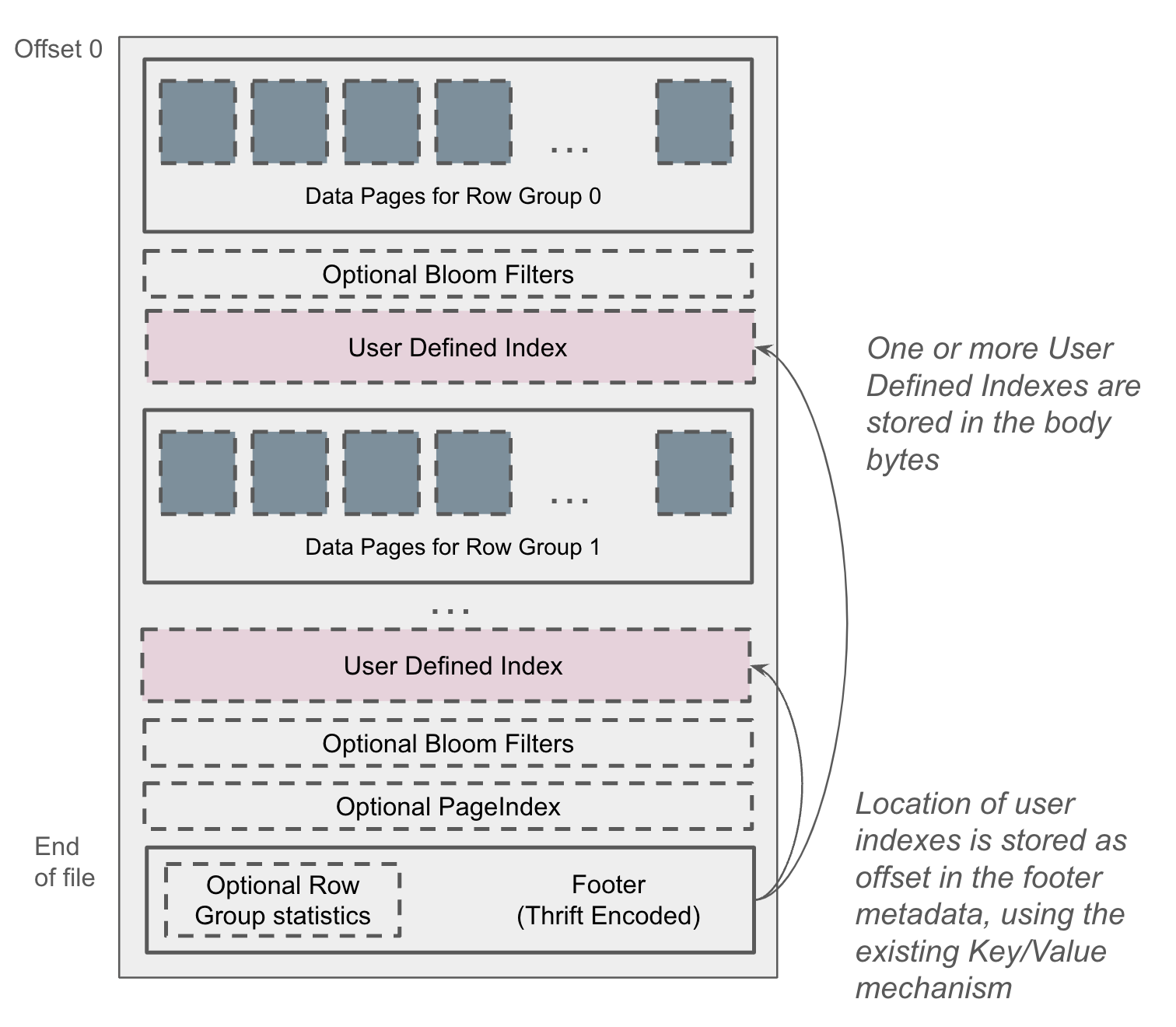
Figure 2: Parquet file layout with user-defined indexes.
Like standard index structures, user-defined indexes can be stored anywhere in the file body, such as after row group data or before the footer. There is no limit to the number of user-defined indexes, nor any restriction on their granularity: they can operate at the file, row group, page, or even row level. This flexibility enables a wide range of use cases, including:
-
Row group or page-level distinct sets: a finer-grained version of the file-level example in this blog.
-
HyperLogLog sketches for distinct value estimation, addressing a common criticism3 of Parquet’s lack of cardinality estimation.
-
Additional zone maps (small materialized aggregates) such as precomputed
sums at the column chunk or data page level for faster query execution. -
Histograms or samples at the row group or column chunk level for predicate selectivity estimates.
Example: Embedding a User Defined Distinct Value Index in Parquet Files¶
This section demonstrates how to embed a simple distinct value index in Parquet files and use it for file-level pruning (skipping) in DataFusion. The full example is available in the DataFusion repository at parquet_embedded_index.rs.
Note that the example requires arrow‑rs v55.2.0 or later, which includes the new “buffered write” API (apache/arrow-rs#7714) to keep the internal byte count in sync after appending index bytes immediately after data pages.
This example is intentionally simple for clarity, but you can adapt the same approach for any index type or data types. The high-level design is:
-
Define your index payload (e.g., bitmap, Bloom filter, sketch, distinct values list, etc.).
-
Serialize your index to bytes and append them into the Parquet file body before writing the footer.
-
Record the index location by adding a key/value entry (e.g.,
"my_index_offset" -> "<byte‑offset>") in the Parquet footer metadata. -
Extend DataFusion with a custom
TableProvider(or wrap the existing Parquet provider) to use the index.
The TableProvider simply reads the footer metadata to discover the index offset, seeks to that offset and deserializes the index, and then uses the index to speed up processing (e.g., skip files, row groups, data pages, etc.).
The resulting Parquet files remain fully compatible with other tools such as DuckDB and Spark, which simply ignore the unknown index bytes and key/value metadata.
Introduction to Distinct Value Indexes¶
A distinct value index stores the unique values of a specific column. This type of index is effective for columns with a small number of distinct values and can be used to quickly skip files that do not match the query. These indexes are popular in several engines, such as the "set" Skip Index in ClickHouse and the Distinct Value Cache in InfluxDB 3.0.
For example, if the files contain a column named Category like this:
Category |
foo |
bar |
... |
baz |
foo |
The distinct value index will contain the values foo, bar, and baz. In contrast, traditional min/max statistics would store only the minimum (bar) and maximum (foo) values, so a query like
SELECT * FROM t WHERE Category = 'bas'
cannot skip the file using min/max values because bas falls between bar and foo in lexicographic order, even though bas does not appear in the column.
This is a key benefit of a distinct value index: accurate filtering without requiring the column to be sorted, unlike min/max-based pruning which is most effective when data is ordered.
While not a traditional index structure like a B-tree, the distinct value set acts as a lightweight, embedded index that enables fast pruning and is especially effective for columns with low cardinality.
Supported Filters
Distinct value indexes are most effective for equality filters, such as:
WHERE category = 'foo'
WHERE category IN ('foo', 'bar')
They can also help with NOT IN and anti-joins, as long as the engine can evaluate them using the list of known distinct values.
However, these indexes are not suitable for range predicates (e.g., category > 'foo'), as they do not preserve any ordering information. For such cases, other structures such as min/max statistics or sorted data layouts may be more effective.
We represent a distinct value index in Rust for our example as a simple HashSet<String>:
/// An index of distinct values for a single column
#[derive(Debug, Clone)]
struct DistinctIndex {
inner: HashSet<String>,
}
File Layout with Distinct Value Index¶
In this example, we write a distinct value index for the Category column into the Parquet file body after all the data pages, and record the index location in the footer metadata. The resulting file layout looks like this:
┌──────────────────────┐
│┌───────────────────┐ │
││ DataPage │ │
│└───────────────────┘ │
Standard Parquet │┌───────────────────┐ │
Data Pages ││ DataPage │ │
│└───────────────────┘ │
│ ... │
│┌───────────────────┐ │
││ DataPage │ │
│└───────────────────┘ │
│┏━━━━━━━━━━━━━━━━━━━┓ │
Non standard │┃ ┃ │
index (ignored by │┃Custom Binary Index┃ │
other Parquet │┃ (Distinct Values) ┃◀│─ ─ ─
readers) │┃ ┃ │ │
│┗━━━━━━━━━━━━━━━━━━━┛ │
Standard Parquet │┏━━━━━━━━━━━━━━━━━━━┓ │ │ key/value metadata
Page Index │┃ Page Index ┃ │ contains location
│┗━━━━━━━━━━━━━━━━━━━┛ │ │ of special index
│╔═══════════════════╗ │
│║ Parquet Footer w/ ║ │ │
│║ Metadata ║ ┼ ─ ─
│║ (Thrift Encoded) ║ │
│╚═══════════════════╝ │
└──────────────────────┘
Serializing the Distinct‑Value Index¶
The example uses a simple newline‑separated UTF‑8 format as the binary format. The code to serialize the distinct index is shown below:
/// Magic bytes to identify our custom index format
const INDEX_MAGIC: &[u8] = b"IDX1";
/// Serialize the distinct index to a writer as bytes
fn serialize<W: Write + Send>(
&self,
arrow_writer: &mut ArrowWriter<W>,
) -> Result<()> {
let serialized = self
.inner
.iter()
.map(|s| s.as_str())
.collect::<Vec<_>>()
.join("\n");
let index_bytes = serialized.into_bytes();
// Set the offset for the index
let offset = arrow_writer.bytes_written();
let index_len = index_bytes.len() as u64;
// Write the index magic and length to the file
arrow_writer.write_all(INDEX_MAGIC)?;
arrow_writer.write_all(&index_len.to_le_bytes())?;
// Write the index bytes
arrow_writer.write_all(&index_bytes)?;
// Append metadata about the index to the Parquet file footer metadata
arrow_writer.append_key_value_metadata(KeyValue::new(
"distinct_index_offset".to_string(),
offset.to_string(),
));
Ok(())
}
This code does the following:
-
Creates a newline‑separated UTF‑8 string from the distinct values.
-
Writes a magic header (
IDX1) and the length of the index. -
Writes the index bytes to the file using the ArrowWriter API.
-
Records the index location by adding a key/value entry (
"distinct_index_offset" -> <offset>) in the Parquet footer metadata.
Note: Use the ArrowWriter::write_all API to ensure the offsets in the footer metadata are correctly tracked.
Reading the Index¶
This code reads the distinct index from a Parquet file:
/// Read a `DistinctIndex` from a Parquet file
fn read_distinct_index(path: &Path) -> Result<DistinctIndex> {
let file = File::open(path)?;
let file_size = file.metadata()?.len();
println!("Reading index from {} (size: {file_size})", path.display(), );
let reader = SerializedFileReader::new(file.try_clone()?)?;
let meta = reader.metadata().file_metadata();
let offset = get_key_value(meta, "distinct_index_offset")
.ok_or_else(|| ParquetError::General("Missing index offset".into()))?
.parse::<u64>()
.map_err(|e| ParquetError::General(e.to_string()))?;
println!("Reading index at offset: {offset}, length");
DistinctIndex::new_from_reader(file, offset)
}
This function:
-
Opens the Parquet footer metadata and extracts
distinct_index_offsetfrom the metadata. -
Calls
DistinctIndex::new_from_readerto read the index from the file at that offset.
DistinctIndex::new_from_reader actually reads the index as shown below:
/// Read the distinct values index from a reader at the given offset and length
pub fn new_from_reader<R: Read + Seek>(mut reader: R, offset: u64) -> Result<DistinctIndex> {
reader.seek(SeekFrom::Start(offset))?;
let mut magic_buf = [0u8; 4];
reader.read_exact(&mut magic_buf)?;
if magic_buf != INDEX_MAGIC {
return exec_err!("Invalid index magic number at offset {offset}");
}
let mut len_buf = [0u8; 8];
reader.read_exact(&mut len_buf)?;
let stored_len = u64::from_le_bytes(len_buf) as usize;
let mut index_buf = vec![0u8; stored_len];
reader.read_exact(&mut index_buf)?;
let Ok(s) = String::from_utf8(index_buf) else {
return exec_err!("Invalid UTF-8 in index data");
};
Ok(Self {
inner: s.lines().map(|s| s.to_string()).collect(),
})
}
This code:
-
Seeks to the offset of the index in the file.
-
Reads the magic bytes and checks they match
IDX1. -
Reads the length of the index and allocates a buffer.
-
Reads the index bytes, converts them to a
String, and splits into lines to populate theHashSet<String>.
Extending DataFusion’s TableProvider¶
To use the distinct index for file-level pruning, extend DataFusion's TableProvider to read the index and apply it during query execution:
impl TableProvider for DistinctIndexTable {
/* ... */
/// Prune files before reading: only keep files whose distinct set
/// contains the filter value
async fn scan(
&self,
_ctx: &dyn Session,
_proj: Option<&Vec<usize>>,
filters: &[Expr],
_limit: Option<usize>,
) -> Result<Arc<dyn ExecutionPlan>> {
// This example only handles filters of the form
// `category = 'X'` where X is a string literal
//
// You can use `PruningPredicate` for much more general range and
// equality analysis or write your own custom logic.
let mut target: Option<&str> = None;
if filters.len() == 1 {
if let Expr::BinaryExpr(expr) = &filters[0] {
if expr.op == Operator::Eq {
if let (
Expr::Column(c),
Expr::Literal(ScalarValue::Utf8(Some(v)), _),
) = (&*expr.left, &*expr.right)
{
if c.name == "category" {
println!("Filtering for category: {v}");
target = Some(v);
}
}
}
}
}
// Determine which files to scan
// files_and_index is a Vec<(String, DistinctIndex)>,
// See the full example for how this is populated.
let files_to_scan: Vec<_> = self
.files_and_index
.iter()
.filter_map(|(f, distinct_index)| {
// keep file if no target or target is in the distinct set
if target.is_none() || distinct_index.contains(target?) {
Some(f)
} else {
None
}
})
.collect();
// Build ParquetSource to actually read the files
let url = ObjectStoreUrl::parse("file://")?;
let source = Arc::new(ParquetSource::default().with_enable_page_index(true));
let mut builder = FileScanConfigBuilder::new(url, self.schema.clone(), source);
for file in files_to_scan {
let path = self.dir.join(file);
let len = std::fs::metadata(&path)?.len();
// If the index contained information about row groups or pages,
// you could also pass that information here to further prune
// the data read from the file.
let partitioned_file =
PartitionedFile::new(path.to_str().unwrap().to_string(), len);
builder = builder.with_file(partitioned_file);
}
Ok(DataSourceExec::from_data_source(builder.build()))
}
/// Tell DataFusion that we can handle filters on the "category" column
fn supports_filters_pushdown(
&self,
fs: &[&Expr],
) -> Result<Vec<TableProviderFilterPushDown>> {
// Mark as inexact since pruning is file‑granular
Ok(vec![TableProviderFilterPushDown::Inexact; fs.len()])
}
}
This code does the following:
-
Implements the
scanmethod to filter files based on the distinct index. -
Checks if the filter is an equality predicate on the
categorycolumn. -
If the target value is specified, checks if the distinct index contains that value.
-
Builds a
FileScanConfigwith only the files that match the filter.
Putting It All Together¶
To use the distinct index in a DataFusion query, write sample Parquet files with the embedded index, register the DistinctIndexTable provider, and run a query with a predicate that can be optimized by the index as shown below.
// Write sample files with embedded indexes
tmp_dir.iter().for_each(|(name, vals)| {
write_file_with_index(&dir.join(name), vals).unwrap();
});
// Register provider and query
let provider = Arc::new(DistinctIndexTable::try_new(dir, schema.clone())?);
ctx.register_table("t", provider)?;
// Only files containing 'foo' will be scanned
let df = ctx.sql("SELECT * FROM t WHERE category = 'foo'").await?;
df.show().await?;
Verifying Compatibility with DuckDB¶
Even with extra bytes and unknown metadata keys, standard Parquet readers ignore the index. You can verify this using another system such as DuckDB to read the Parquet created in the example. DuckDB will read the files without any issues, ignoring the custom index and unknown footer metadata.
SELECT * FROM read_parquet('/tmp/parquet_index_data/*');
┌──────────┐
│ category │
│ varchar │
├──────────┤
│ foo │
│ bar │
│ foo │
│ baz │
│ qux │
│ foo │
│ quux │
│ quux │
└──────────┘
Conclusion¶
In this post, we explained how index structures are stored in Apache Parquet, how to embed user-defined indexes without changing the format, and how to use user-defined indexes to speed up query processing.
Parquet-based systems can achieve significant performance improvements for almost any query pattern while still retaining broad compatibility, using user-defined embedded indexes, external indexes4 and rewriting files optimized for specific queries5. System designers can choose among the available options to make the appropriate trade-offs between operational complexity, performance, file size, and cost for their specific use cases.
We hope this post inspires you to explore custom indexes in Parquet files, rather than proposing new file formats and reimplementing existing features. The DataFusion community is excited to see how you use this feature in your projects!
About the Authors¶
Qi Zhu is a Senior Engineer at Cloudera, an active contributor to Apache DataFusion and Apache Arrow, a committer on Apache Hadoop and Apache YuniKorn. He has extensive experience in distributed systems, scheduling, and large-scale computing.
Jigao Luo is a 1.5-year PhD student at Systems Group @ TU Darmstadt. Regarding Parquet, he is an external contributor to NVIDIA RAPIDS cuDF, focusing on the GPU Parquet reader.
Andrew Lamb is a Staff Engineer at InfluxData, and a member of the Apache DataFusion and Apache Arrow PMCs. He has been working on Databases and related systems more than 20 years.
About DataFusion¶
Apache DataFusion is an extensible query engine toolkit, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion and similar technology are part of the next generation “Deconstructed Database” architectures, where new systems are built on a foundation of fast, modular components, rather than as a single tightly integrated system.
The DataFusion community is always looking for new contributors to help improve the project. If you are interested in learning more about how query execution works, help document or improve the DataFusion codebase, or just try it out, we would love for you to join us.
Footnotes¶
1: A commonly cited example is highly selective predicates (e.g. category = 'foo') but for which the built in BloomFilters are not sufficient.
2: There are other index structures, but they are either 1) not widely supported (such as statistics in the page headers) or 2) not yet widely used in practice at the time of this writing (such as GeospatialStatistics and SizeStatistics).
3: Seamless Integration of Parquet Files into Data Processing. / Rey, Alice; Freitag, Michael; Neumann, Thomas. / BTW 2023
4: For more information about external indexes, see this talk and the parquet_index.rs and advanced_parquet_index.rs examples in the DataFusion repository.
5: For information about rewriting files to optimize for specific queries, such as resorting, repartitioning, and tuning data page and row group sizes, see XiangpengHao/liquid‑cache#227 and the conversation between JigaoLuo and XiangpengHao for details. We hope to make a future post about this topic.
6: An index can also be stored inline in the key-value metadata. This approach is simple to implement and ensures the index is available once the footer is read, without additional I/O. However, it requires the index to be serialized as a UTF-8 string, which may be less efficient and increases the size of the footer metadata, impacting all Parquet readers, even those that ignore the index.