Using External Indexes, Metadata Stores, Catalogs and Caches to Accelerate Queries on Apache Parquet
Posted on: Fri 15 August 2025 by Andrew Lamb (InfluxData)
It is a common misconception that Apache Parquet requires (slow) reparsing of metadata and is limited to indexing structures provided by the format. In fact, caching parsed metadata and using custom external indexes along with Parquet's hierarchical data organization can significantly speed up query processing.
In this blog, I describe the role of external indexes, caches, and metadata stores in high performance systems, and demonstrate how to apply these concepts to Parquet processing using Apache DataFusion. Note this is an expanded version of the companion video and presentation.
Motivation¶
System designers choose between a pre-configured data system or the often daunting task of building their own custom data platform from scratch. For many users and use cases, one of the existing data systems will likely be good enough. However, traditional systems such as Apache Spark, DuckDB, ClickHouse, Hive, or Snowflake are each optimized for a certain set of tradeoffs between performance, cost, availability, interoperability, deployment target, cloud / on-premises, operational ease and many other factors.
For new, or especially demanding use cases, where no existing system makes your optimal tradeoffs, you can build your own custom data platform. Previously this was a long and expensive endeavor, but today, in the era of Composable Data Systems, it is increasingly feasible. High quality, open source building blocks such as Apache Parquet for storage, Apache Arrow for in-memory processing, and Apache DataFusion for query execution make it possible to quickly build custom data platforms optimized for your specific needs1.
Introduction to External Indexes / Catalogs / Metadata Stores / Caches¶
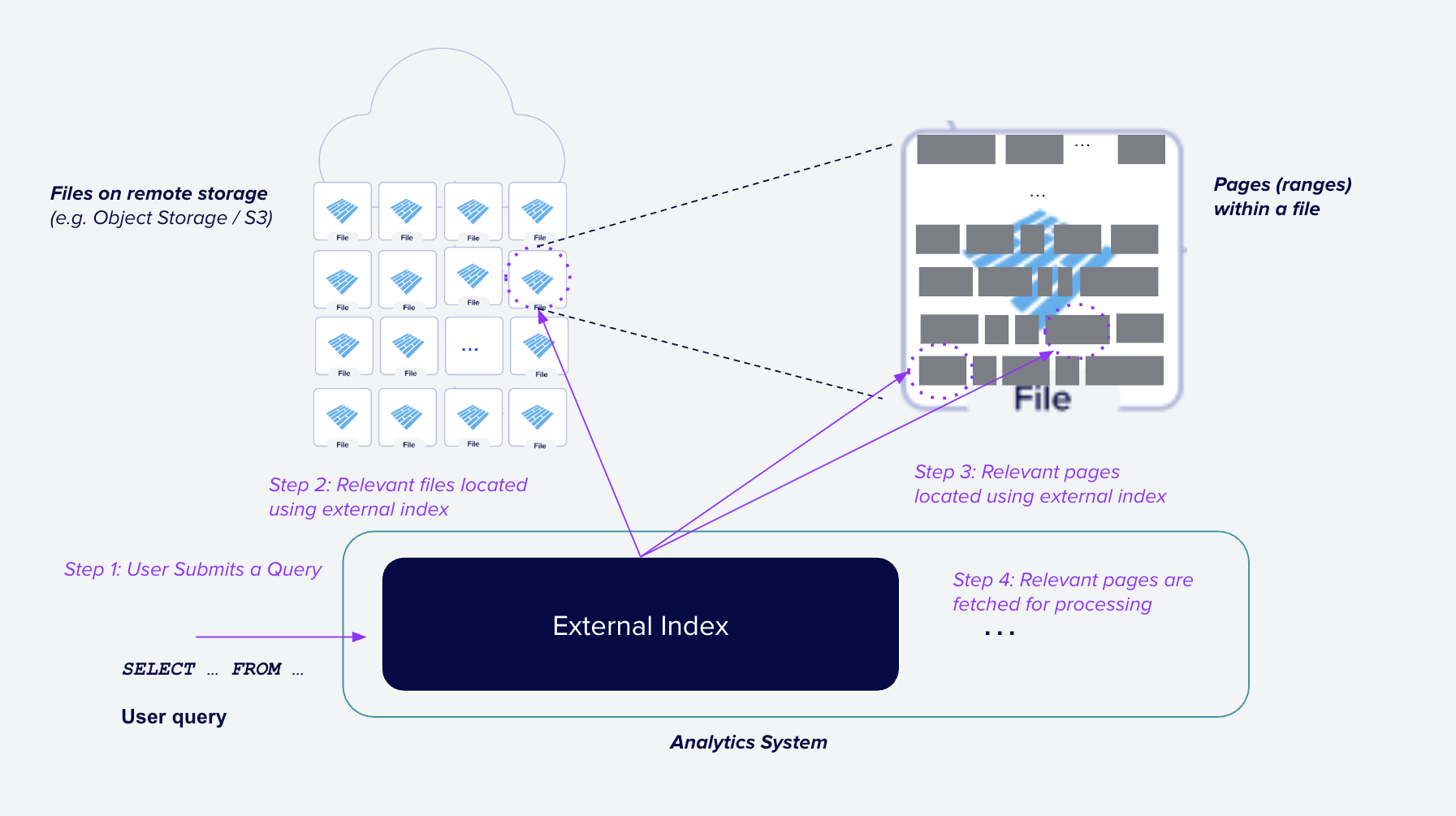
Figure 1: Using external indexes to speed up queries in an analytic system. Given a user's query (Step 1), the system uses an external index (one that is not stored inline in the data files) to quickly find files that may contain relevant data (Step 2). Then, for each file, the system uses the external index to further narrow the required data to only those parts of each file (e.g. data pages) that are relevant (Step 3). Finally, the system reads only those parts of the file and returns the results to the user (Step 4).
In this blog, I use the term "index" to mean any structure that helps locate relevant data during processing, and a high level overview of how external indexes are used to speed up queries is shown in Figure 1.
All data systems typically store both the data itself and additional information (metadata) to more quickly find data relevant to a query. Metadata is often stored in structures with names like "index," "catalog" and "cache" and the terminology varies widely across systems.
There are many different types of indexes, types of content stored in indexes, strategies to keep indexes up to date, and ways to apply indexes during query processing. These differences each have their own set of tradeoffs, and thus different systems understandably make different choices depending on their use case. There is no one-size-fits-all solution for indexing. For example, Hive uses the Hive Metastore, Vertica uses a purpose-built Catalog, and open data lake systems typically use a table format such as Apache Iceberg or Delta Lake.
External Indexes store information separately ("external") to the data itself. External indexes are flexible and widely used, but require additional operational overhead to keep in sync with the data files. For example, if you add a new Parquet file to your data lake, you must also update the relevant external index to include information about the new file. Note, you can avoid the operational overhead of external indexes by using only the data files themselves, including Embedding User-Defined Indexes in Apache Parquet Files. However, this approach comes with its own set of tradeoffs such as increased file sizes and the need to update the data files to update the index.
Examples of information commonly stored in external indexes include:
- Min/Max statistics
- Bloom filters
- Inverted indexes / Full Text indexes
- Information needed to read the remote file (e.g the schema, or Parquet footer metadata)
Examples of locations where external indexes can be stored include:
- Separate files such as JSON or Parquet files.
- Transactional databases such as PostgreSQL tables.
- Distributed key-value stores such as Redis or Cassandra.
- Local memory such as an in-memory hash map.
Using Apache Parquet for Storage¶
While the rest of this blog focuses on building custom external indexes using Parquet and DataFusion, I first briefly discuss why Parquet is a good choice for modern analytic systems. The research community frequently confuses limitations of a particular implementation of the Parquet format with the Parquet Format itself, and this confusion often obscures capabilities that make Parquet a good target for external indexes.
Apache Parquet's combination of good compression, high-performance, high quality open source libraries, and wide ecosystem interoperability make it a compelling choice when building new systems. While there are some niche use cases that may benefit from specialized formats, Parquet is typically the obvious choice. While recent proprietary file formats differ in details, they all use the same high level structure2 as Parquet:
- Metadata (typically at the end of the file)
- Data divided into columns and then into horizontal slices (e.g. Parquet Row Groups and/or Data Pages).
The structure is so widespread because it enables the hierarchical pruning approach described in the next section. For example, the native Clickhouse MergeTree format consists of Parts (similar to Parquet files), and Granules (similar to Row Groups). The Clickhouse indexing strategy follows a classic hierarchical pruning approach that first locates the Parts and then the Granules that may contain relevant data for the query. This is exactly the same pattern as Parquet based systems, which first locate the relevant Parquet files and then the Row Groups / Data Pages within those files.
A common criticism of using Parquet is that it is not as performant as some new proposal. These criticisms typically cherry-pick a few queries and/or datasets and build a specialized index or data layout for that specific case. However, as I explain in the companion video of this blog, even for ClickBench6, the current benchmaxxing3 target of analytics vendors, there is less than a factor of two difference in performance between custom file formats and Parquet. The difference becomes even lower when using Parquet files that use the full range of existing Parquet features such Column and Offset Indexes and Bloom Filters7. Compared to the low interoperability and expensive transcoding/loading step of alternate file formats, Parquet is hard to beat.
Hierarchical Pruning Overview¶
The key technique for optimizing query processing systems is skipping as much data as possible, as quickly as possible. Analytic systems typically use a hierarchical approach to progressively narrow the set of data that needs to be processed. The standard approach is shown in Figure 2:
- Entire files are ruled out
- Within each file, large sections (e.g. Row Groups) are ruled out
- (Optionally) smaller sections (e.g. Data Pages) are ruled out
- Finally, the system reads only the relevant data pages and applies the query predicate to the data

Figure 2: Hierarchical Pruning: The system first rules out files, then Row Groups, then Data Pages, and finally reads only the relevant data pages.
The process is hierarchical because the per-row computation required at the earlier stages (e.g. skipping an entire file) is lower than the computation required at later stages (apply predicates to the data). As mentioned before, while the details of what metadata is used and how that metadata is managed varies substantially across query systems, they almost all use a hierarchical pruning strategy.
Apache Parquet Overview¶
This section provides a brief background on the organization of Apache Parquet files which is needed to fully understand the sections on implementing external indexes. If you are already familiar with Parquet, you can skip this section.
Logically, Parquet files are organized into Row Groups and Column Chunks as shown below.
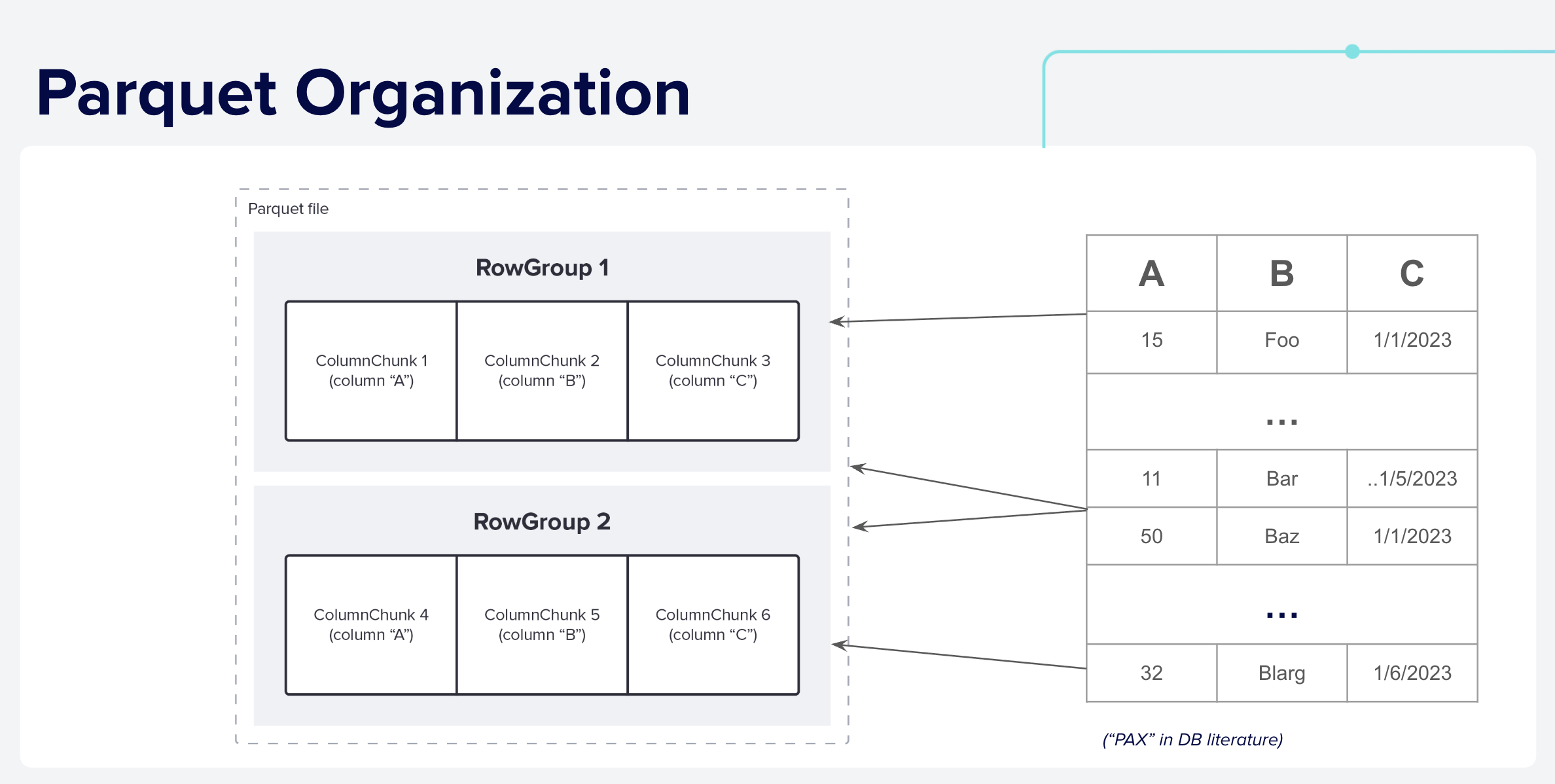
Figure 3: Logical Parquet File Layout: Data is first divided in horizontal slices called Row Groups. The data is then stored column by column in Column Chunks. This arrangement allows efficient access to only the portions of columns needed for a query.
Physically, Parquet data is stored as a series of Data Pages along with metadata stored at the end of the file (in the footer), as shown below.
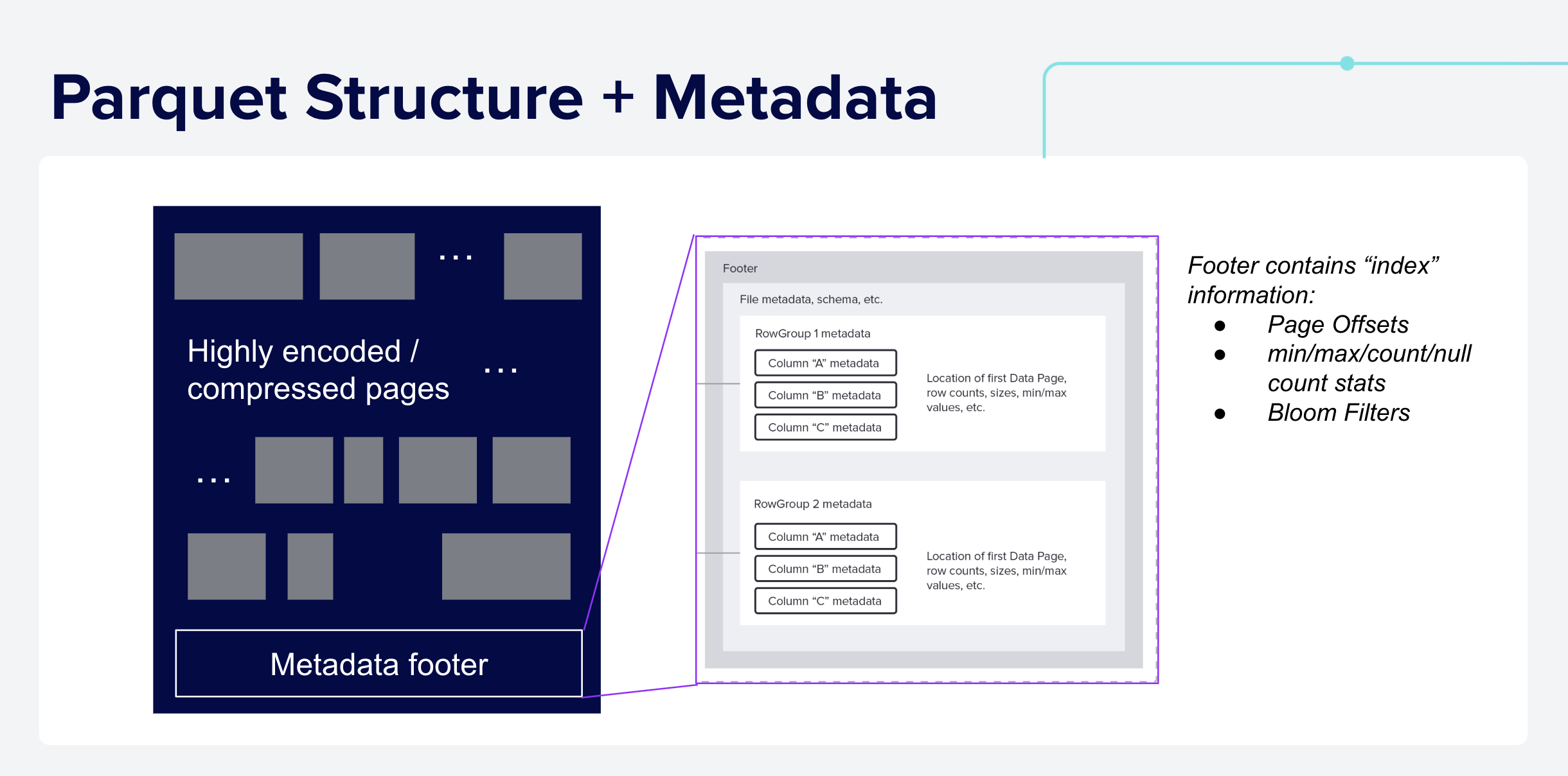
Figure 4: Physical Parquet File Layout: A typical Parquet file is composed of many data pages, which contain the raw encoded data, and a footer that stores metadata about the file, including the schema and the location of the relevant data pages, and optional statistics such as min/max values for each Column Chunk.
Parquet files are organized to minimize IO and processing using two key mechanisms:
-
Projection Pushdown: if a query needs only a subset of columns from a table, it only needs to read the pages for the relevant Column Chunks
-
Filter Pushdown: Similarly, given a query with a filter predicate such as
WHERE C > 25, query engines can use statistics such as (but not limited to) the min/max values stored in the metadata to skip reading and decoding pages that cannot possibly match the predicate.
The high level mechanics of Parquet predicate pushdown is shown below:
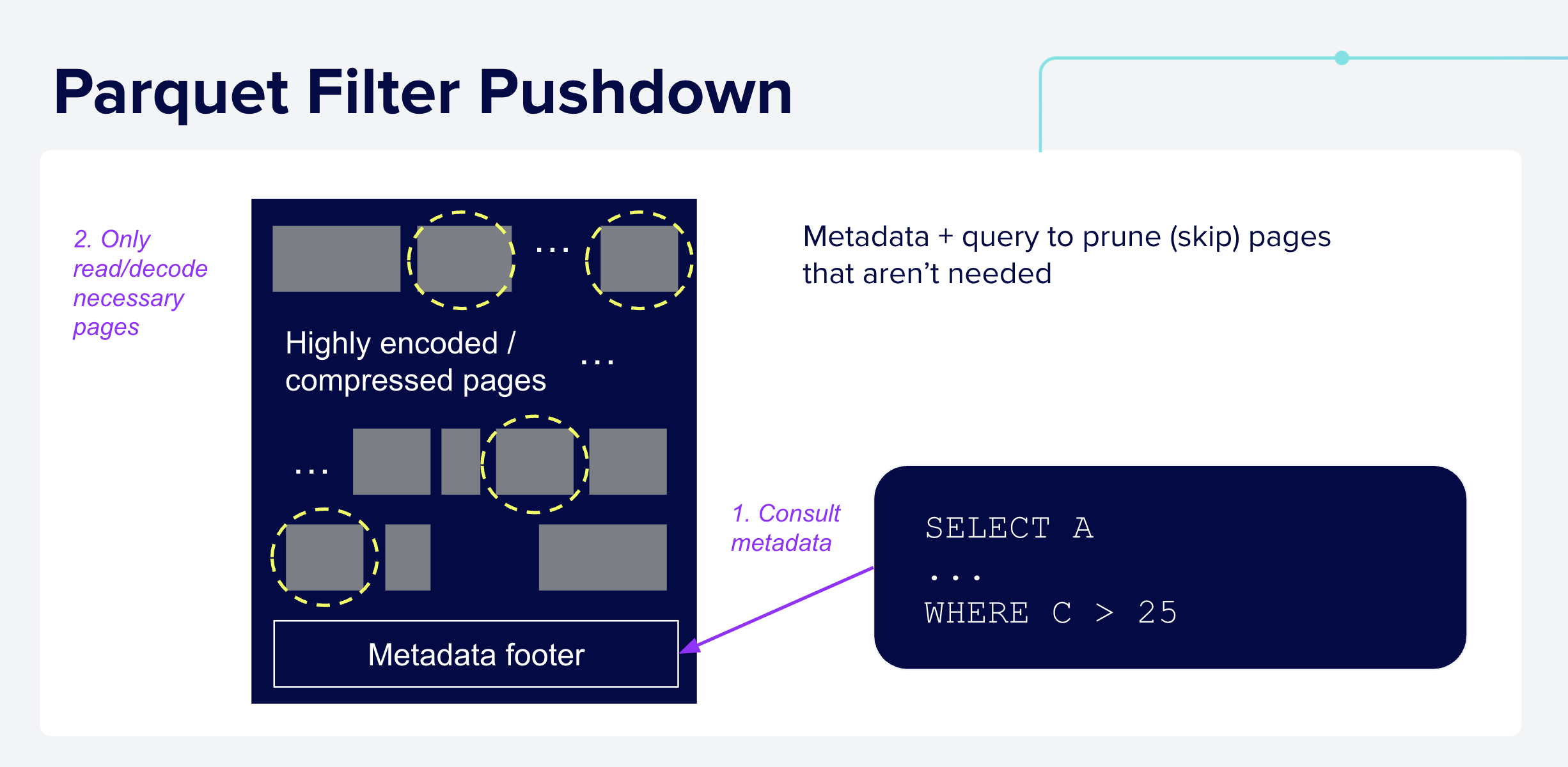
Figure 5: Filter Pushdown in Parquet: query engines use the predicate,
C > 25, from the query along with statistics from the metadata, to identify
pages that may match the predicate which are read for further processing.
Please refer to the Efficient Filter Pushdown blog for more details.
NOTE the exact same pattern can be applied using information from external
indexes, as described in the next sections.
Pruning Files with External Indexes¶
The first step in hierarchical pruning is quickly ruling out files that cannot
match the query. For example, if a system expects to see queries that
apply to a time range, it might create an external index to store the minimum
and maximum time values for each file. Then, during query processing, the
system can quickly rule out files that cannot possibly contain relevant data.
For example, if the user issues a query that only matches the last 7 days of data:
WHERE time > now() - interval '7 days'
then the index can quickly rule out files that only have data older than the most recent 7 days.
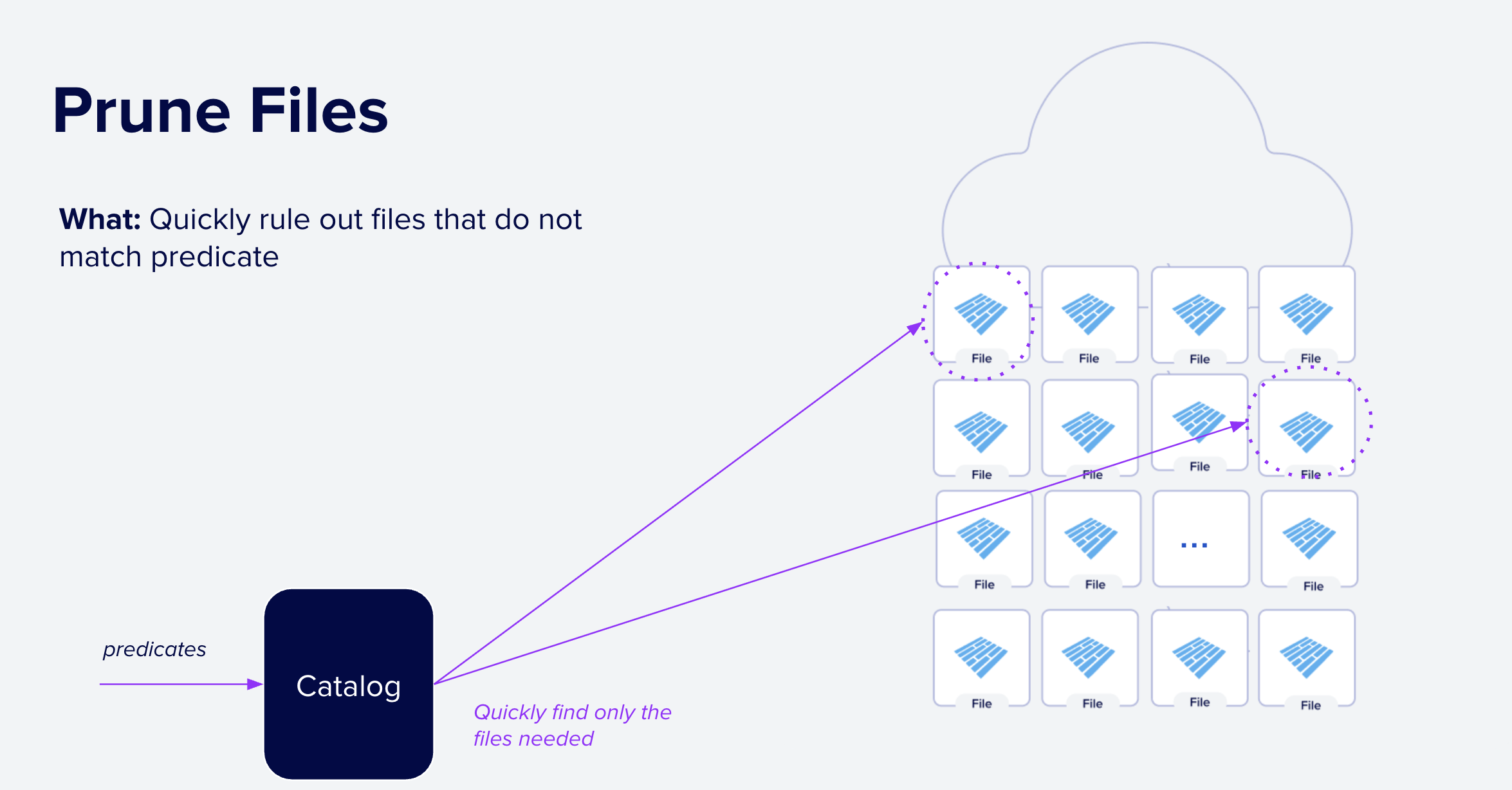
Figure 6: Step 1: File Pruning. Given a query predicate, systems use external indexes to quickly rule out files that cannot match the query. In this case, by consulting the index all but two files can be ruled out.
External indexes offer much faster lookups and lower I/O overhead than Parquet's built-in file-level indexes by skipping further processing for many data files. Without an external index, systems typically fall back to reading each file's footer to find files needed for further processing. Skipping per-file processing is especially important when reading from remote object stores such as S3, GCS or Azure Blob Store, where each request adds tens to hundreds of milliseconds of latency.
There are many different systems that use external indexes to find files such as Hive Metadata Store, Iceberg, Delta Lake, DuckLake, and Hive Style Partitioning4. Of course, each of these systems works well for their intended use cases, but if none meets your needs, or you want to experiment with different strategies, you can easily build your own external index using DataFusion.
Pruning Files with External Indexes Using DataFusion¶
To implement file pruning in DataFusion, you implement a custom TableProvider
with the supports_filter_pushdown and scan methods. The
supports_filter_pushdown method tells DataFusion which predicates can be used
and the scan method uses those predicates with the
external index to find the files that may contain data that matches the query.
The DataFusion repository contains a fully working and well-commented example,
parquet_index.rs, of this technique that you can use as a starting point.
The example creates a simple index that stores the min/max values for a column
called value along with the file name. Then it runs the following query:
SELECT file_name, value FROM index_table WHERE value = 150
The custom IndexTableProvider's scan method uses the index to find files
that may contain data matching the predicate as shown below:
impl TableProvider for IndexTableProvider {
async fn scan(
&self,
state: &dyn Session,
projection: Option<&Vec<usize>>,
filters: &[Expr],
limit: Option<usize>,
) -> Result<Arc<dyn ExecutionPlan>> {
let df_schema = DFSchema::try_from(self.schema())?;
// Combine all the filters into a single ANDed predicate
let predicate = conjunction(filters.to_vec());
// Use the index to find the files that might have data that matches the
// predicate. Any file that can not have data that matches the predicate
// will not be returned.
let files = self.index.get_files(predicate.clone())?;
let object_store_url = ObjectStoreUrl::parse("file://")?;
let source = Arc::new(ParquetSource::default().with_predicate(predicate));
let mut file_scan_config_builder =
FileScanConfigBuilder::new(object_store_url, self.schema(), source)
.with_projection(projection.cloned())
.with_limit(limit);
// Add the files to the scan config
for file in files {
file_scan_config_builder = file_scan_config_builder.with_file(
PartitionedFile::new(file.path(), file_size.size()),
);
}
Ok(DataSourceExec::from_data_source(
file_scan_config_builder.build(),
))
}
...
}
DataFusion handles the details of pushing down the filters to the
TableProvider and the mechanics of reading the Parquet files, so you can focus
on the system specific details such as building, storing, and applying the index.
While this example uses a standard min/max index, you can implement any indexing
strategy you need, such as bloom filters, a full text index, or a more complex
multidimensional index.
DataFusion also includes several libraries to help with common filtering and pruning tasks, such as:
-
A full and well documented expression representation (Expr) and APIs for building, visiting, and rewriting query predicates.
-
Range Based Pruning (PruningPredicate) for cases where your index stores min/max values.
-
Expression simplification (ExprSimplifier) for simplifying predicates before applying them to the index.
-
Range analysis for predicates (cp_solver) for interval-based range analysis (e.g.
col > 5 AND col < 10).
Pruning Parts of Parquet Files with External Indexes¶
Once the set of files to be scanned has been determined, the next step in the hierarchical pruning process is to further narrow down the data within each file. Similarly to the previous step, almost all advanced query processing systems use additional metadata to prune unnecessary parts of the file, such as Data Skipping Indexes in ClickHouse.
For Parquet-based systems, the most common strategy is using the built-in metadata such as min/max statistics and Bloom Filters. However, it is also possible to use external indexes for filtering WITHIN Parquet files as shown below.
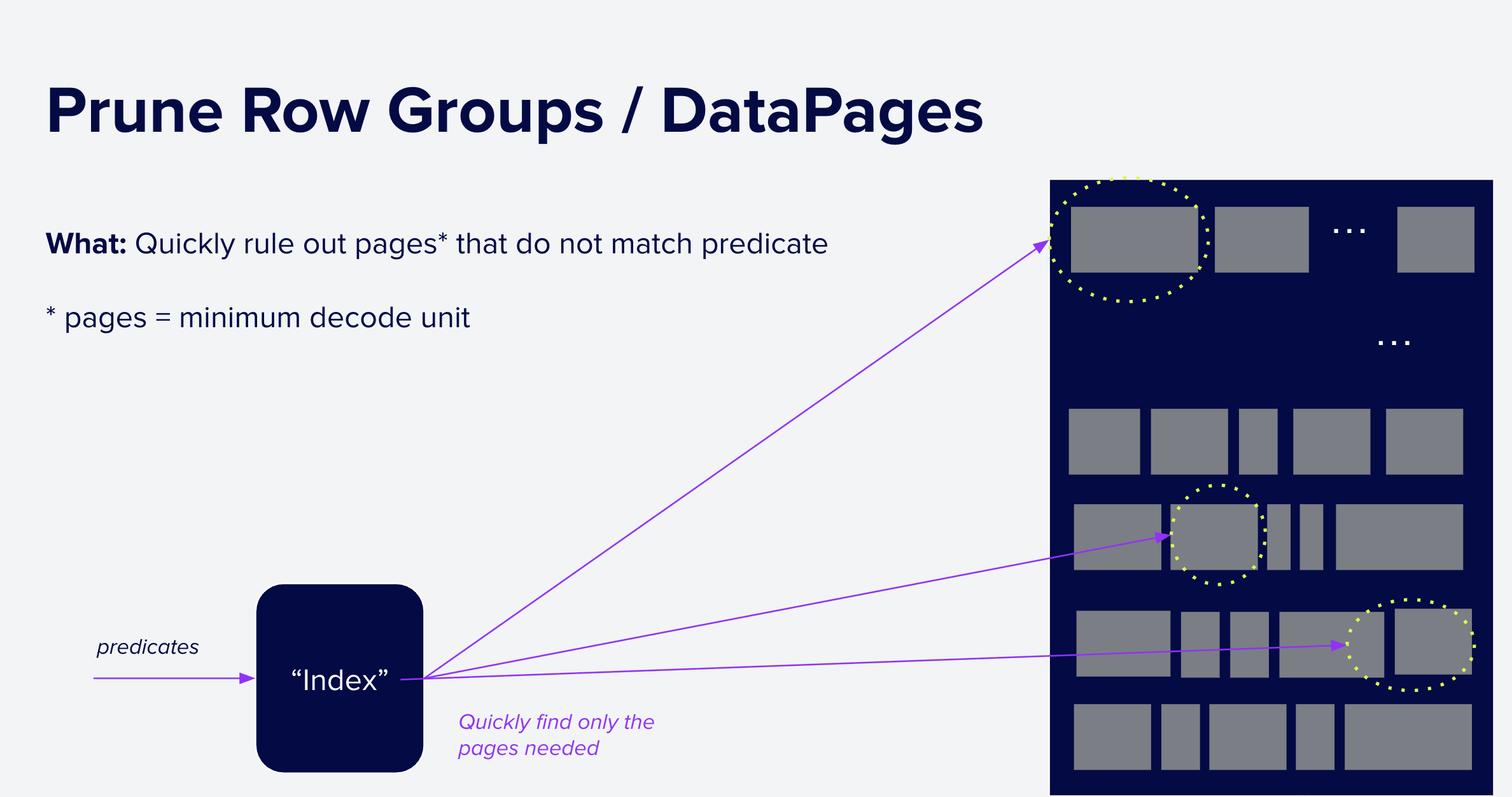
Figure 7: Step 2: Pruning Parquet Row Groups and Data Pages. Given a query predicate, systems can use external indexes / metadata stores as well as Parquet's built-in structures to quickly rule out Row Groups and Data Pages that cannot match the query. In this case, the index has ruled out all but three data pages which must then be fetched for more processing.
Pruning Parts of Parquet Files with External Indexes using DataFusion¶
To implement pruning within Parquet files, you use the same [TableProvider] APIs
as for pruning files. For each file your provider wants to scan, you provide
an additional ParquetAccessPlan that tells DataFusion what parts of the file to read. This plan is
then further refined by the DataFusion Parquet reader using the built-in
Parquet metadata to potentially prune additional row groups and data pages
during query execution. You can find a full working example in
the advanced_parquet_index.rs example of the DataFusion repository.
Here is how you build a ParquetAccessPlan to scan only specific row groups
and rows within those row groups.
// Default to scan all (4) row groups
let mut access_plan = ParquetAccessPlan::new_all(4);
access_plan.skip(0); // skip row group 0
// Specify scanning rows 100-200 and 350-400
// in row group 1 that has 1000 rows
let row_selection = RowSelection::from(vec![
RowSelector::skip(100),
RowSelector::select(100),
RowSelector::skip(150),
RowSelector::select(50),
RowSelector::skip(600), // skip last 600 rows
]);
access_plan.scan_selection(1, row_selection);
access_plan.skip(2); // skip row group 2
// all of row group 3 is scanned by default
The rows that are selected by the resulting plan look like this:
┌───────────────────┐
│ │
│ │ SKIP
│ │
└───────────────────┘
Row Group 0
┌───────────────────┐
│ ┌───────────────┐ │ SCAN ONLY ROWS
│ └───────────────┘ │ 100-200
│ ┌───────────────┐ │ 350-400
│ └───────────────┘ │
└───────────────────┘
Row Group 1
┌───────────────────┐
│ │
│ │ SKIP
│ │
└───────────────────┘
Row Group 2
┌───────────────────┐
│ │
│ │ SCAN ALL ROWS
│ │
└───────────────────┘
Row Group 3
In the scan method, you return an ExecutionPlan that includes the
ParquetAccessPlan for each file as shown below (again, slightly simplified for
clarity):
impl TableProvider for IndexTableProvider {
async fn scan(
&self,
state: &dyn Session,
projection: Option<&Vec<usize>>,
filters: &[Expr],
limit: Option<usize>,
) -> Result<Arc<dyn ExecutionPlan>> {
let indexed_file = &self.indexed_file;
let predicate = self.filters_to_predicate(state, filters)?;
// Use the external index to create a starting ParquetAccessPlan
// that determines which row groups to scan based on the predicate
let access_plan = self.create_plan(&predicate)?;
let partitioned_file = indexed_file
.partitioned_file()
// provide the access plan to the DataSourceExec by
// storing it as "extensions" on PartitionedFile
.with_extensions(Arc::new(access_plan) as _);
let file_source = Arc::new(
ParquetSource::default()
// provide the predicate to the standard DataFusion source as well so
// DataFusion's Parquet reader will apply row group pruning based on
// the built-in Parquet metadata (min/max, bloom filters, etc) as well
.with_predicate(predicate)
);
let file_scan_config =
FileScanConfigBuilder::new(object_store_url, schema, file_source)
.with_limit(limit)
.with_projection(projection.cloned())
.with_file(partitioned_file)
.build();
// Finally, put it all together into a DataSourceExec
Ok(DataSourceExec::from_data_source(file_scan_config))
}
...
}
Caching Parquet Metadata¶
It is often said that Parquet is unsuitable for low latency query systems because the footer must be read and parsed for each query. This is simply not true, and many systems use Parquet for low latency analytics and cache the parsed metadata in memory to avoid re-reading and re-parsing the footer for each query.
Caching Parquet Metadata using DataFusion¶
Reusing cached Parquet Metadata is also shown in the advanced_parquet_index.rs example. The example reads and caches the metadata for each file when the index is first built and then uses the cached metadata when reading the files during query execution.
(Note that thanks to Nuno Faria, Jonathan Chen, and Shehab Amin the built
in ListingTable TableProvider included with DataFusion will cache Parquet
metadata in the next release of DataFusion (50.0.0). See the mini epic for
details).
To avoid reparsing the metadata, first implement a custom ParquetFileReaderFactory as shown below, again slightly simplified for clarity:
impl ParquetFileReaderFactory for CachedParquetFileReaderFactory {
fn create_reader(
&self,
_partition_index: usize,
file_meta: FileMeta,
metadata_size_hint: Option<usize>,
_metrics: &ExecutionPlanMetricsSet,
) -> Result<Box<dyn AsyncFileReader + Send>> {
let filename = file_meta.location();
// Pass along the information to access the underlying storage
// (e.g. S3, GCS, local filesystem, etc)
let object_store = Arc::clone(&self.object_store);
let mut inner =
ParquetObjectReader::new(object_store, file_meta.object_meta.location)
.with_file_size(file_meta.object_meta.size);
// retrieve the pre-parsed metadata from the cache
// (which was built when the index was built and is kept in memory)
let metadata = self
.metadata
.get(&filename)
.expect("metadata for file not found: {filename}");
// Return a ParquetReader that uses the cached metadata
Ok(Box::new(ParquetReaderWithCache {
filename,
metadata: Arc::clone(metadata),
inner,
}))
}
}
Then, in your TableProvider use the factory to avoid re-reading the metadata for each file:
impl TableProvider for IndexTableProvider {
async fn scan(
&self,
state: &dyn Session,
projection: Option<&Vec<usize>>,
filters: &[Expr],
limit: Option<usize>,
) -> Result<Arc<dyn ExecutionPlan>> {
// Configure a factory interface to avoid re-reading the metadata for each file
let reader_factory =
CachedParquetFileReaderFactory::new(Arc::clone(&self.object_store))
.with_file(indexed_file);
// build the partitioned file (see example above for details)
let partitioned_file = ...;
// Create the ParquetSource with the predicate and the factory
let file_source = Arc::new(
ParquetSource::default()
// provide the factory to create Parquet reader without re-reading metadata
.with_parquet_file_reader_factory(Arc::new(reader_factory)),
);
// Pass along the information needed to read the files
let file_scan_config =
FileScanConfigBuilder::new(object_store_url, schema, file_source)
.with_limit(limit)
.with_projection(projection.cloned())
.with_file(partitioned_file)
.build();
// Finally, put it all together into a DataSourceExec
Ok(DataSourceExec::from_data_source(file_scan_config))
}
...
}
Conclusion¶
Parquet has the right structure for high performance analytics via hierarchical pruning, and it is straightforward to build external indexes to speed up queries using DataFusion without changing the file format. If you need to build a custom data platform, it has never been easier to build it with Parquet and DataFusion.
I am a firm believer that data systems of the future will be built on a foundation of modular, high quality, open source components such as Parquet, Arrow, and DataFusion. We should focus our efforts as a community on improving these components rather than building new file formats that are optimized for narrow use cases.
Come Join Us! 🎣
![]()
About the Author¶
Andrew Lamb is a Staff Engineer at InfluxData, and a member of the Apache DataFusion and Apache Arrow PMCs. He has been working on Databases and related systems more than 20 years.
About DataFusion¶
Apache DataFusion is an extensible query engine toolkit, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion and similar technology are part of the next generation “Deconstructed Database” architectures, where new systems are built on a foundation of fast, modular components, rather than as a single tightly integrated system.
The DataFusion community is always looking for new contributors to help improve the project. If you are interested in learning more about how query execution works, help document or improve the DataFusion codebase, or just try it out, we would love for you to join us.
Acknowledgements¶
Thank you to Qi Zhu, Adam Reeve, Jigao Luo, Oleks V, Shehab Amin, Nuno Faria and Bruce Ritchie for their insightful feedback on this blog post.
Footnotes¶
1: This trend is described in more detail in the FDAP Stack blog
2: This layout is referred to as PAX in the
database literature after the first research paper to describe the technique.
3: Benchmaxxing (verb): to add specific optimizations that only
impact benchmark results and are not widely applicable to real world use cases.
4: Hive Style Partitioning is a simple and widely used form of indexing based on directory paths, where the directory structure is used to
store information about the data in the files. For example, a directory structure like year=2025/month=08/day=15/ can be used to store data for a specific day
and the system can quickly rule out directories that do not match the query predicate.
5: I am also convinced that we can speed up the process of parsing Parquet footer
with additional engineering effort (see Xiangpeng Hao's previous blog on the
topic). Ed Seidl is beginning this effort. See the ticket for details.
6: ClickBench includes a wide variety of query patterns
such as point lookups, filters of different selectivity, and aggregations.
7: For example, Qi Zhu was able to speed up reads by over 2x
simply by rewriting the Parquet files with Offset Indexes and no compression (see issue #16149 comment for details).
There is likely significant additional performance available by using Bloom Filters and resorting the data
to be clustered in a more optimal way for the queries.