Apache DataFusion Comet 0.15.0 Release
Posted on: Sat 18 April 2026 by pmc
The Apache DataFusion PMC is pleased to announce version 0.15.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for improved performance and efficiency without requiring any code changes.
This release covers approximately four weeks of development work and is the result of merging 142 PRs from 19 contributors. See the change log for more information.
Performance¶
Comet 0.15.0 provides a 2x speedup for TPC-H @ SF1000 (1TB), resulting in 50% cost savings.
That 2x speedup gives you a choice: finish the same Spark workload in half the time on the cluster you already have, or match your current Spark performance on roughly half the resources. Either way, the gain translates directly into lower cloud bills, reduced on-prem capacity, and lower energy usage, with no changes to your existing Spark SQL, DataFrame, or PySpark code. Comet runs on commodity hardware: no GPUs, FPGAs, or other specialized accelerators are required, so the savings come from better utilization of the infrastructure you already run on.
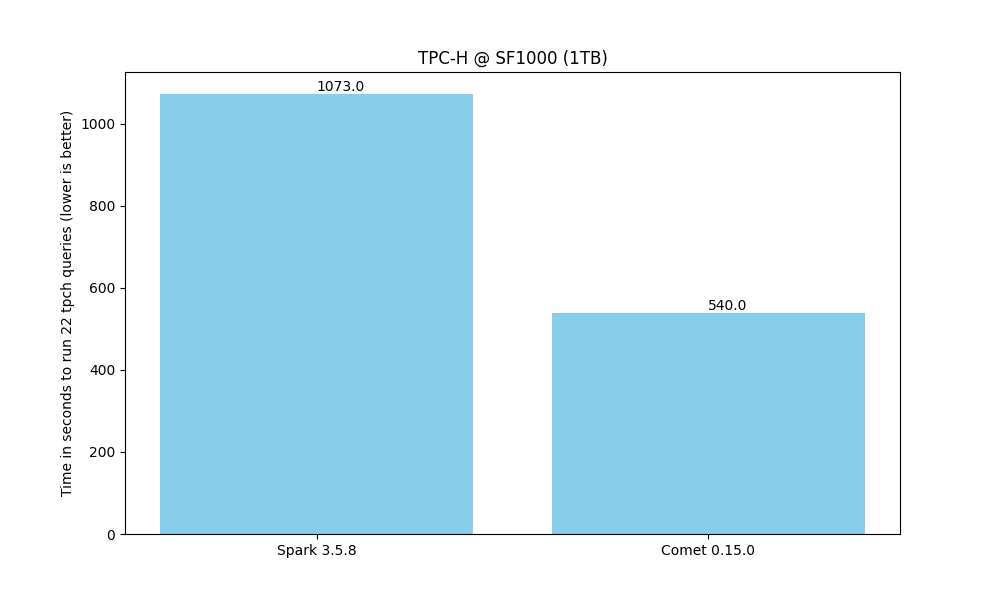
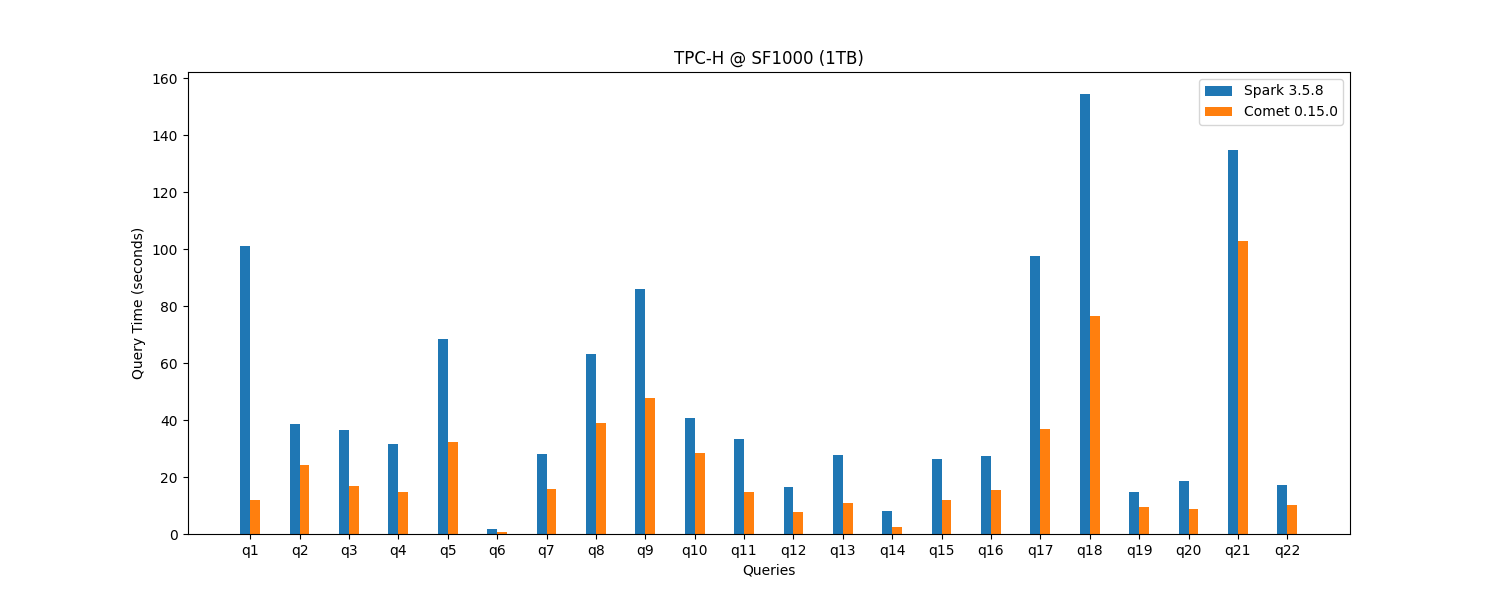
See the Comet Benchmarking Guide for more details.
Performance was a major theme of this release, with a series of targeted optimizations across the shuffle, scan, and execution layers.
Reducing JVM/Native Boundary Overhead¶
Several changes in this release target the cost of crossing between the JVM and native sides, which can dominate execution time in shuffle- and broadcast-heavy workloads:
- Shuffle read path: The native shuffle reader no longer uses FFI on the read side, removing a per-batch cost that was particularly visible in shuffle-heavy queries.
- Broadcast exchanges: Batches are now coalesced before broadcasting, reducing the number of small batches crossing the JVM/native boundary.
- FFI-safe operators: More operators are marked as FFI-safe, avoiding unnecessary deep copies when crossing the JVM/native boundary.
Expanded Native Execution Coverage¶
- Columnar-to-row (C2R): Native C2R conversion is now exercised for a broader set of query shapes.
autoscan mode: Theautoscan mode now enables thenative_datafusionscan where supported, giving users the benefits of the native Parquet reader without having to explicitly opt in. This is part of the ongoing effort to makenative_datafusionthe default Parquet path once the deprecation ofnative_iceberg_compatcompletes.
Memory Management¶
- Shared memory pools: Unified memory pools are now shared across native execution contexts within a Spark task, improving memory accounting and reducing OOMs.
Object Storage I/O¶
- Object store caching: Object stores and bucket region lookups are cached, dramatically reducing DNS query volume on workloads that open many files.
get_rangesperformance: Picked up an upstreamopendalfix that restores fast range reads from object storage.
Together, these changes reduce CPU and memory overhead for shuffle-heavy, broadcast-heavy, and object-storage-bound workloads.
Native Iceberg Reader Enabled by Default¶
This release marks a major milestone for Iceberg users: Comet's fully-native Iceberg reader is now enabled by default. Workloads that read Iceberg tables will automatically benefit from native Rust-based scans built on iceberg-rust, with no additional configuration required.
To support this change, the release bundles a broad set of Iceberg-focused improvements:
- Dynamic Partition Pruning (DPP): The native Iceberg reader supports DPP, allowing partition filters derived at runtime to prune Iceberg file scans and substantially reduce I/O for star-schema-style queries.
- Correct classloader handling: Iceberg classes are now loaded via the thread context classloader, resolving class-loading issues in environments where the executor classloader differs from the application classloader.
- Continuous Iceberg CI: Iceberg Spark integration tests now run on every PR and push to
main, providing continuous validation of the native Iceberg code path. Test diffs for Spark 3.4 were updated to keep the matrix green across supported Spark versions. - iceberg-rust upgrade: Comet picks up the latest iceberg-rust, pulling in fixes for Parquet reader edge cases discovered in earlier testing.
- Refreshed documentation: The Iceberg user guide has been rewritten to reflect current capabilities, and the contributor guide now documents how to run the Iceberg Spark test suites locally.
Users who need to fall back to the previous behavior can still opt out, but we encourage the community to exercise the native reader and report any issues.
Sort-Merge Join Performance¶
Comet relies heavily on sort-merge join (SMJ) because DataFusion's hash joins do not yet support spilling to disk. For larger-than-memory joins, SMJ is the only viable path, making its performance critical for real-world workloads at scale.
DataFusion 53 includes several SMJ improvements that Comet 0.15.0 benefits from directly:
- Zero-copy slicing instead of the take kernel (datafusion#20463)
- Streaming output instead of waiting for all input before emitting (datafusion#20482)
- Cached row counts to avoid O(n) recounting (datafusion#20478)
Additional SMJ work is landing in upstream DataFusion and will arrive in a future Comet release:
- Specialized semi/anti join stream (datafusion#20806)
- Batch deferred filtering with 20–50x improvements for near-unique LEFT and FULL joins (datafusion#21184)
- DynComparator for ~5% TPC-H improvement (datafusion#21484)
- Vec-based filter state replacing HashMap (datafusion#21517)
- Full outer join correctness fix for NULL filter results (datafusion#21660)
With these performance improvements, the next release of Comet will enable SMJ with filters by default.
Other Key Features¶
New Expressions and Function Support¶
This release adds support for the following:
- Date/time functions:
days,hours,date_from_unix_date - String/JSON functions: native
get_json_objectwith improved performance over the fallback path - Hash/math functions:
bin - Array functions:
sort_array - Window functions:
LEADandLAGwithIGNORE NULLS - Aggregates: SQL
FILTER (WHERE ...)clauses now execute natively;Corraggregate enabled
Expanded Metrics and Observability¶
Comet metrics can now be exposed through Spark's external monitoring system, making it easier to integrate Comet
execution statistics with existing observability dashboards. Native DataFusion scans also now report accurate
filesScanned and bytesScanned input metrics, matching Spark's native Parquet scan reporting.
Stability and Correctness¶
A significant portion of this release is dedicated to stability and Spark compatibility. Highlights include:
- Cast string to timestamp: Multiple fixes for UTC timestamps, timezone handling, special formats
(
epoch,now, etc.), and compatibility with Spark's semantics. - Cast decimal to string: Added legacy mode handling to match Spark's output formatting.
- String to decimal: Support for full-width characters, null characters, and negative scale.
- Decimal arithmetic: Fixes for decimal division and additional test coverage for ANSI overflow handling, including scalar decimal overflow.
- Array expressions: Corrected
GetArrayItemnull handling for dynamic indices;array_appendreturn type fixed and markedCompatible; auditedarray_insertfor correctness;array_compactmarkedCompatible; array-to-array cast enabled. - DateTrunc/TimestampTrunc: Fixed native crashes when the input is a literal.
- Ambiguous local times: Correct handling of ambiguous and non-existent local times across DST transitions.
- Case-insensitive Parquet fields:
native_datafusionnow correctly detects duplicate/ambiguous fields in case-insensitive mode and falls back where appropriate. - Shuffle planning: Shuffle fallback decisions are now "sticky" across planning passes, and Comet columnar shuffle is skipped for stages containing DPP scans to avoid mismatched partitioning.
- Error propagation: Native error messages are now propagated through
SparkExceptioneven when theerrorClassis empty, and file-not-found errors flow through the standard Spark error JSON path. - Trigonometric compatibility:
tanandatan2are now Spark-compatible.
Dependency Upgrades¶
This release upgrades to DataFusion 53.1 and Arrow 58.1, and picks up the latest iceberg-rust release
with additional reader fixes. The jni crate was upgraded to 0.22.4.
Deprecations and Removals¶
The SupportsComet interface has been removed, along with the Java-based Iceberg integration path (which is
fully superseded by the native Iceberg reader). See comet#2921
for background on the decision to standardize on the native iceberg-rust integration. The native_iceberg_compat
scan remains deprecated and is expected to be removed in a future release in favor of native_datafusion.
Compatibility¶
Supported platforms include Spark 3.4.3, 3.5.4–3.5.8, and Spark 4.0.x with various JDK and Scala combinations.
The community encourages users to test Comet with existing Spark and Iceberg workloads and welcomes contributions to ongoing development.
Get Started with Comet 0.15.0¶
Ready to try it out? Follow the Comet 0.15.0 Installation Guide to get up and running, then point Comet at your existing Spark workloads and see the speedup for yourself.