Apache DataFusion Ballista 53.0.0 Released
Posted on: Sun 24 May 2026 by pmc
We are pleased to announce version 53.0.0 of Apache DataFusion Ballista. Ballista is a distributed query execution engine that enhances Apache DataFusion by enabling parallel execution of workloads across multiple nodes.
The last Ballista blog post covered 43.0.0, released in January 2025. In the year and a bit since, the project has quietly shipped a release for every DataFusion release through 53.0.0. This post catches up on what changed across that span, what landed specifically in 53.0.0, and where the project is heading.
How Ballista has changed since 43.0.0¶
The story of 43.0.0 was one of simplification: experimental features were removed, the BallistaContext was
deprecated in favor of the standard DataFusion SessionContext, and the project's release cadence was
aligned with DataFusion's. The story of the year that followed has been one of putting things back, but
under a more deliberate design.
Production deployment¶
A lot of the work over this period has been about running Ballista in real clusters rather than just on a developer's laptop:
- S3 object store support has been added to both the executor and scheduler binaries, including credentials derived from the standard AWS environment, instance metadata, and explicit configuration.
- Docker images for the scheduler and executor are now published on each release, making Docker Compose and Kubernetes deployments straightforward.
- Cluster RPC can be configured with TLS and custom headers, enabling deployments that need encrypted inter-component traffic or pass-through authentication.
- Push-based task scheduling is now the default, replacing pull-staged scheduling. Push scheduling generally results in lower latency for short queries. Both modes remain available.
- Configurable gRPC timeouts, retry policies, and message size limits make it easier to operate clusters under varying network conditions.
- Memory bounds for executors can now be set with
--memory-pool-size, so executors no longer rely on unbounded growth.
Shuffle subsystem¶
The shuffle subsystem received the largest single rework over this period.
- A new sort-based shuffle writer was added in 52.0.0 and made the default in 53.0.0. The hash-based writer remains available behind a configuration flag.
- Buffered I/O in the shuffle writer significantly reduces the number of small writes, and disk I/O has been moved off the Tokio worker threads so that I/O latency does not block scheduling.
- Per-task spill thresholds bound writer memory in the sort-based path, and a deferred materialization
step using
interleave_record_batchreduces allocator pressure during shuffle write. - Remote shuffle reads now use Arrow Flight directly, with a client cache on the executor side, giving better throughput and resource utilization for shuffle-heavy queries.
- Shuffle reader cleanup removes job-local data once a job completes.
REST API and observability¶
The scheduler's REST API has grown from a small status surface to the primary control plane for inspecting running and completed jobs:
- The REST API is now enabled by default.
/api/jobsand/api/jobs/<job_id>expose job status, start/end times, logical and physical plans, per-stage task information, and metrics.- Plans can be rendered as a tree directly from the REST API.
- Per-executor system and process metrics are reported, and Prometheus metrics integration is available behind a feature flag.
A new Python interface¶
A redesigned Python client has replaced BallistaBuilder. The new entry point is BallistaSessionContext,
which mirrors the DataFusion Python SessionContext API:
from ballista import BallistaSessionContext
ctx = BallistaSessionContext(
"df://localhost:50050",
cluster_config={
"datafusion.execution.target_partitions": "32",
},
)
ctx.register_parquet("trips", "/mnt/bigdata/trips")
df = ctx.sql("SELECT vendor_id, COUNT(*) FROM trips GROUP BY vendor_id")
df.show()
A number of fixes since 43.0.0 made this client much more usable in distributed environments: session
configuration is now propagated from the Python client to the cluster; collect, show, and to_pandas
go through the cluster instead of falling back to a local execution path; and S3 access works without
requiring explicit credentials. This work has been done in close collaboration with the
datafusion-python team, who have been generous with API guidance and review. Jupyter notebook
integration is documented in the Python user guide.
The release process has also been extended so that future Ballista releases publish Python wheels to
PyPI as ballista.
Spark compatibility and Substrait¶
Ballista now supports the spark-compat Cargo feature, which auto-registers the
[datafusion-spark] function library in the executor session context. This makes it possible to evaluate
Spark-compatible SQL semantics on a Ballista cluster.
The scheduler also has a Substrait surface: SubstraitSchedulerClient accepts Substrait logical plans.
This is an important step toward decoupling Ballista from any one client language.
Highlights of 53.0.0¶
53.0.0 is a feature-heavy release, with significant work in observability, the planner, and the executor.
Terminal User Interface¶
The Ballista CLI now ships with an integrated Terminal User Interface for monitoring a running cluster.
The TUI is enabled with ballista-cli --tui, or by typing \tui inside the CLI. It provides views for
executors, jobs, stages, tasks, plan trees, and metrics, all backed by the scheduler's REST API.
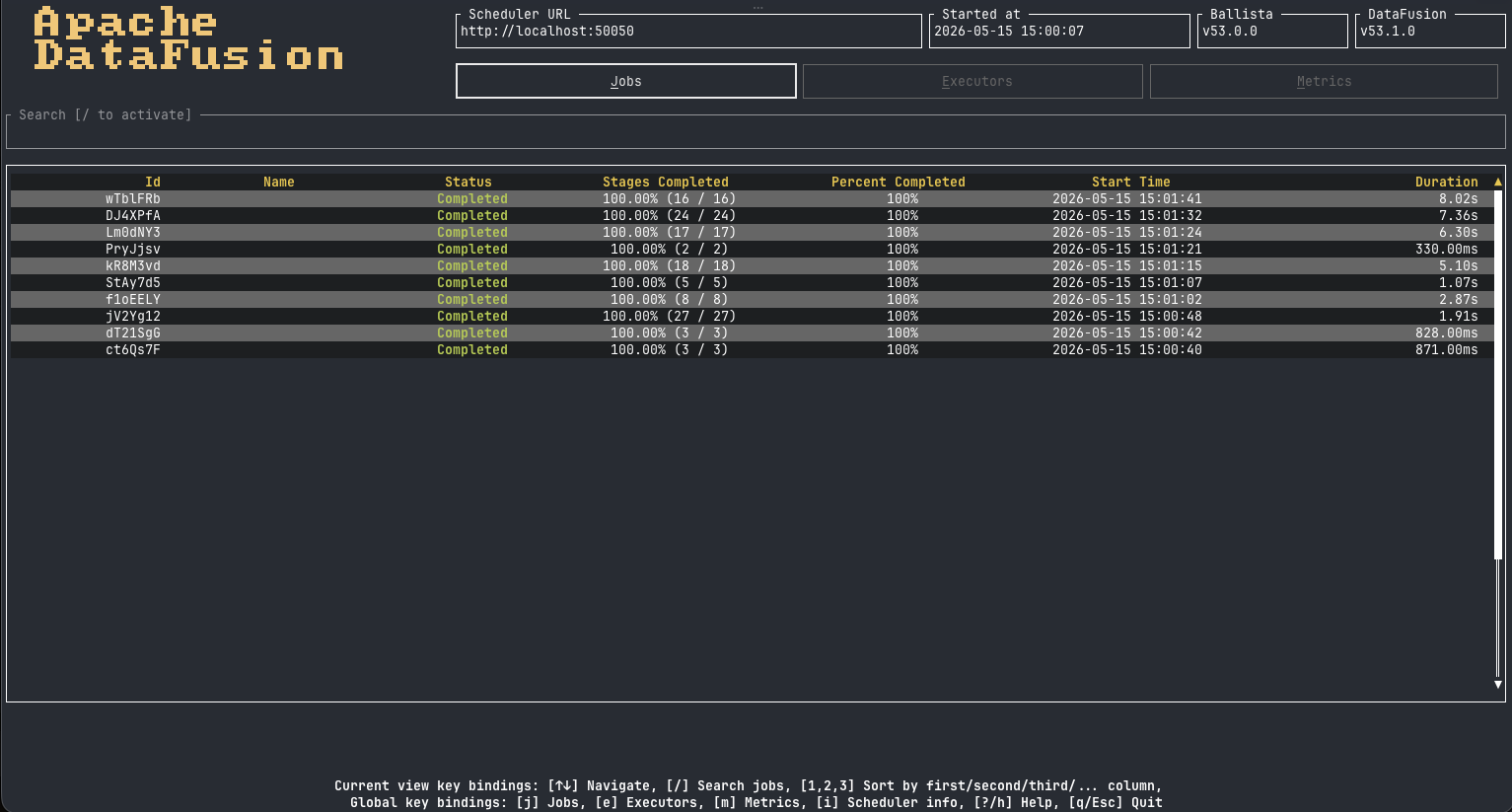
Plan rendering is available directly from the TUI, with logical, physical, and graph views:
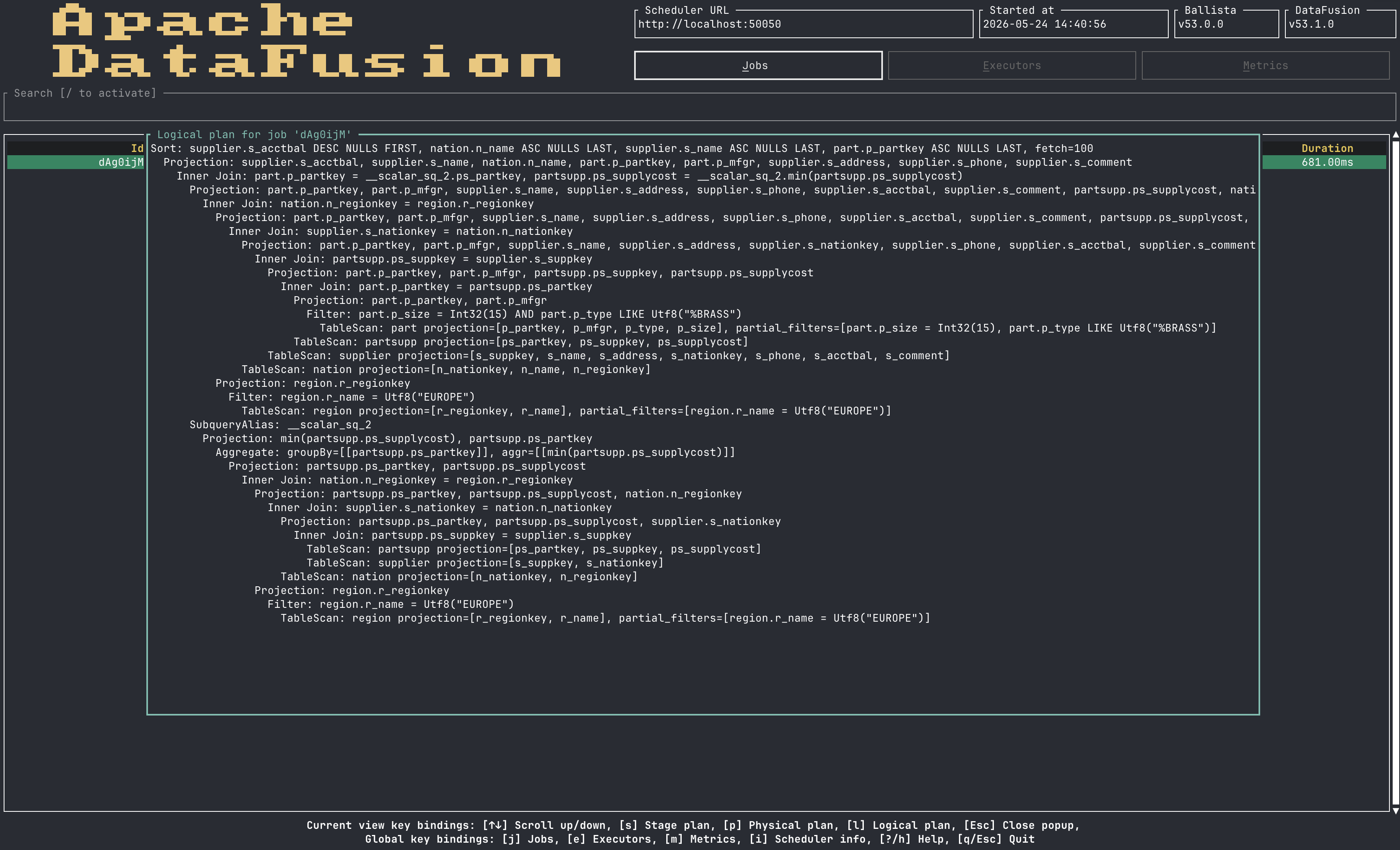
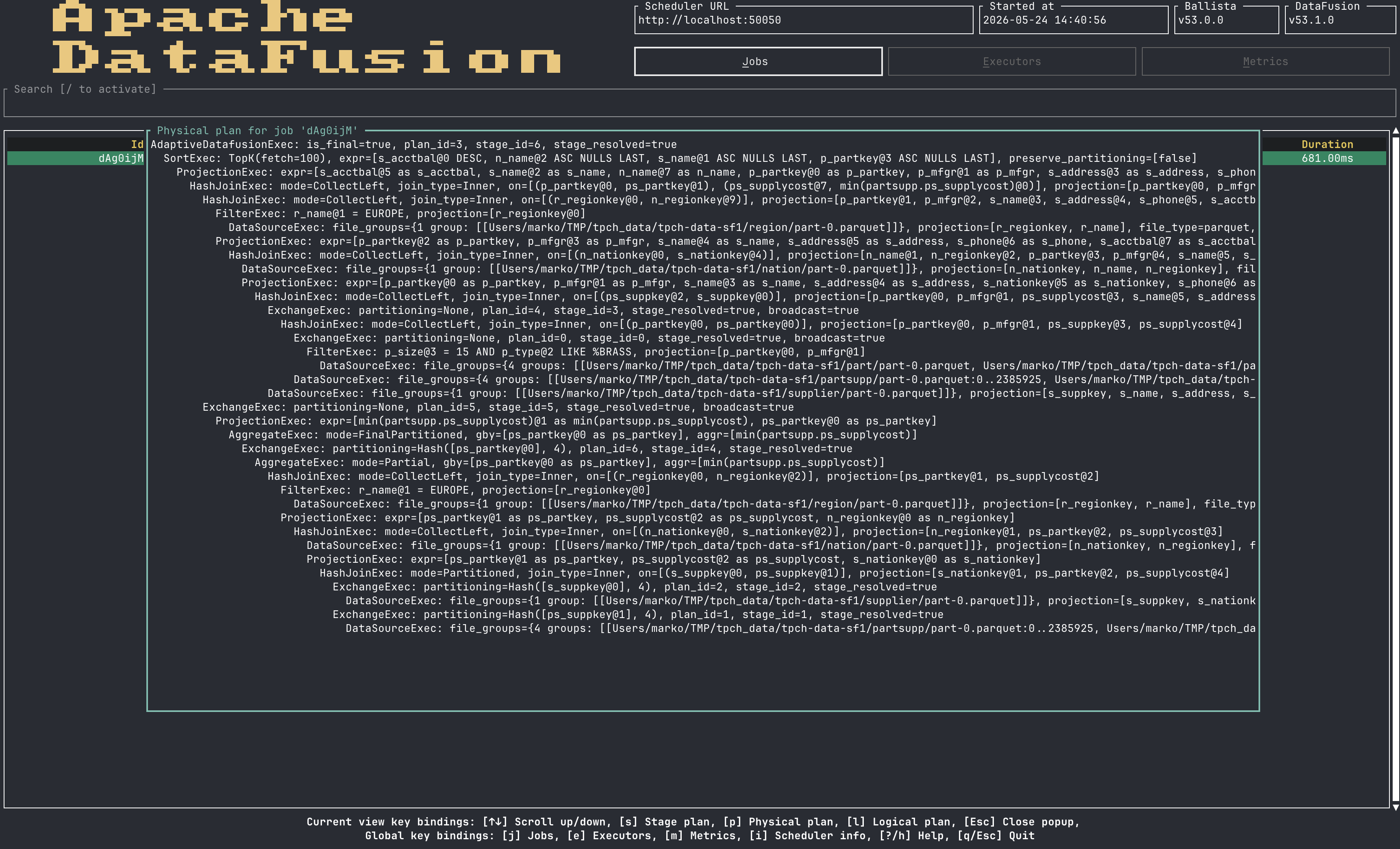
A web rendering of the TUI is in development.
Adaptive Query Execution (Experimental)¶
Ballista now has experimental support for Adaptive Query Execution (AQE). When enabled, the scheduler re-runs the DataFusion physical optimizer between query stages, using statistics collected from completed stages instead of relying solely on pre-execution estimates.
let session_config = SessionConfig::new_with_ballista()
.set_bool("ballista.planner.adaptive.enabled", true);
Two adaptive optimizations are implemented today:
- Join reordering based on runtime row counts so the smaller side drives the join.
- Empty stage elimination, where downstream stages are short-circuited if an upstream stage produced zero rows.
The AQE work in 53.0.0 also added support for the sort-based shuffle writer in adaptive plans, lazy stage
evaluation, and a CoalescePartitionsRule that coalesces shuffle partitions based on resolved statistics.
AQE is disabled by default and should currently be considered experimental. Tracking work happens on issue #1359.
EXPLAIN ANALYZE¶
EXPLAIN ANALYZE now works through the Ballista scheduler, returning the executed physical plan along with
the per-stage runtime metrics collected during execution. This is the easiest way to inspect what actually
happened at runtime, including the metrics emitted by ShuffleWriterExec and ShuffleReaderExec.
Join planning¶
Two changes affect how joins are planned for distributed execution:
- Sort-merge join is the default for Ballista, which avoids the all-rows-on-one-node bottleneck that hash join can hit at scale.
- A broadcast-style hash join is selected when the build side is small enough to fit in memory across all partitions. The selection rule has been tightened to avoid swapping inputs in cases where the right side has multiple partitions.
Shuffle and executor improvements¶
53.0.0 builds on the shuffle work from earlier releases.
- Sort-based shuffle is now the default. Configuration knobs for buffer size, memory budget, spill threshold, and coalesce batch size are documented in the tuning guide.
- The shuffle writer's disk I/O runs off the Tokio worker pool to avoid blocking scheduling.
- The executor caches Ballista clients to reduce connection setup costs in shuffle-heavy plans.
- Executors expose system and process metrics, including memory utilization and shuffle counters.
REST API improvements¶
53.0.0 expands the REST API significantly: jobs now expose start/end times, the running job list works, stage running times are calculated correctly, plan tree rendering is available, and a number of edge-case panics have been fixed.
What people are working on¶
Active development is happening across a number of fronts. Some of the open work most likely to land in upcoming releases:
- Adaptive Query Execution (#1359) — broadcast join in AQE, partition splitting for skewed shuffles, executor failure handling, and global LIMIT early-stop.
- Cluster observability (#1426) — exposing more runtime metrics through the REST API and producing per-stage flame graphs.
- Web rendering of the TUI (#1660) — a browser-based view of the same data the terminal UI shows.
- Colocated-join optimizer for hash-bucketed tables (#1677) — Pinot-style optimization that avoids
shuffles when both sides are pre-bucketed on the join key. A related discussion is on extending
BroadcastSmallSideRuleandColocatedJoinRuletoSortMergeJoinExec(#1679). - Job data cleanup (#1316) — unifying cleanup paths and using targeted notifications instead of broadcasting cleanup to every executor.
- External remote shuffle services (#1539) — investigating support for Apache Celeborn and Apache Uniffle as a shuffle backend.
- Open table formats (#1241, Iceberg #890) — discussing a path to first-class support for Iceberg, Delta, and similar formats.
A separate scaling effort is tracking the gap between Ballista on TPC-H at SF=100 (where it is competitive) and SF=1000 (#1596), which is expected to surface bottlenecks in scheduler throughput, shuffle I/O, and small-files handling.
Roadmap¶
There is no formal long-term roadmap, but the rough direction continues to be:
- Close the gap between DataFusion and Ballista. Anything that DataFusion can plan and execute on a single node should plan and execute on a Ballista cluster with the same APIs and the same SQL surface.
- Make Ballista boring to operate. Predictable resource usage, good observability, sensible defaults, and robust error handling are higher priority than novel features.
- Land AQE. A working adaptive planner unlocks optimizations that are difficult to express statically and is the foundation for tackling skew and dynamic partition coalescing.
- Improve scaling. Identify and fix the bottlenecks that prevent Ballista from running large benchmarks like TPC-H at SF=1000.
Contributions in any of these areas are very welcome. Issues labeled good first issue are a good place to start.
Thank You¶
This release is the result of work from many contributors over the past 16 months. Thanks especially to Marko Milenković, Martin Grigorov, Daniel Tu, Alexander Domenti, Metehan Yildirim, Sajeevan Achuthan, Harrison Crosse, Andy Grove, and many others whose contributions are visible in the changelog.
Thanks also to the broader DataFusion community whose work Ballista builds on directly.