Tuning Guide#
Partitions and Parallelism#
The goal of any distributed compute engine is to parallelize work as much as possible, allowing the work to scale by adding more compute resource.
The basic unit of concurrency and parallelism in Ballista is the concept of a partition. The leaf nodes of a query
are typically table scans that read files from object storage, and the number of partitions such a scan produces is
driven by datafusion.execution.target_partitions. This is currently a global setting for the entire context.
DataFusion’s own default for this setting is the number of CPU cores available to the process. Ballista overrides it
to 16 in SessionConfig::new_with_ballista(), so a context created with SessionContext::remote() or
SessionContext::standalone() starts at 16. If you instead build your own SessionConfig and pass it to
remote_with_state() or standalone_with_state(), Ballista leaves the setting alone and you get whatever that
config carries, which is the client machine’s core count for a plain SessionConfig::new(). Set it explicitly if
you care about the value.
A scan is partitioned in two steps:
When the table is listed, its files are sorted by path and distributed into at most
target_partitionsfile groups. A “customer” table of 200 Parquet files read withtarget_partitions = 16therefore produces 16 partitions of roughly 13 files each, not 200 partitions.The physical optimizer then splits individual files by byte range, so a table with fewer files than
target_partitionscan still be read in parallel. A table consisting of a single large Parquet file is split intotarget_partitionsbyte ranges rather than being read by one task. This step is controlled bydatafusion.optimizer.repartition_file_scans(defaulttrue) and only applies when the scan reads at leastdatafusion.optimizer.repartition_file_min_sizebytes (default 10 MB). Small tables below that threshold are left as a single partition, since splitting them costs more than it saves.
Ballista disables DataFusion’s round-robin repartitioning, so this file-group splitting is the only source of
parallelism for a scan stage. Raising target_partitions is the way to increase it, and lowering it is the way to
reduce the number of partitions a large table is read with.
Example: Setting the desired number of shuffle partitions when creating a context.
use ballista::extension::{SessionConfigExt, SessionContextExt};
let session_config = SessionConfig::new_with_ballista()
.with_target_partitions(200);
let state = SessionStateBuilder::new()
.with_default_features()
.with_config(session_config)
.build();
let ctx: SessionContext = SessionContext::remote_with_state(&url,state).await?;
Partitions and Tasks#
A stage’s partition count is not the same as its task count. The scheduler keeps a cursor over the stage’s
partitions and, each time an executor is assigned work, hands out a slice of those partitions to run as a single
task. The size of that slice is bounded by both the executor’s free vcores and
ballista.scheduler.max_partitions_per_task.
That setting still defaults to 1, so out of the box a 16-partition scan stage runs as 16 single-partition tasks.
Raising it lets the scheduler pack several partitions into one task, which reduces task count and scheduling
overhead and allows operators such as sort and hash join to work across partitions within a task. Setting it to 0
removes the cap entirely, so each task is filled up to the assigned executor’s free vcore count: a 16-partition
stage then runs as one task on an idle 16-vcore executor, or as four 4-partition tasks across four 4-vcore
executors.
key |
type |
default |
description |
|---|---|---|---|
ballista.scheduler.max_partitions_per_task |
UInt64 |
1 |
Upper bound on the number of input partitions packed into a single task. |
Stages whose plan collapses all input into a single partition (for example under a CoalescePartitionsExec or
SortPreservingMergeExec) ignore this cap and always pack their full pending queue into one task, since splitting
them would produce partial results that downstream stages cannot merge.
Each task’s plan is rewritten before dispatch so that its scan sees only the file groups belonging to its own slice.
Configuring Executor Concurrency Levels#
Each executor instance advertises a fixed number of virtual cores (vcores) to the scheduler. This is specified by
passing a --vcores command-line parameter. The default setting is to use all available CPU cores.
Increasing this configuration setting will increase the number of tasks that each executor can run concurrently but this will also mean that the executor will use more memory. If executors are failing due to out-of-memory errors then decreasing the vcore count may help.
Configuring Executor Memory Pool#
By default the executor uses DataFusion’s unbounded memory pool, so spillable
operators (sort, hash join, hash aggregate) grow until the host runs out of
memory. To bound executor memory and let those operators spill to disk under
pressure, pass --memory-pool-size when starting the executor:
ballista-executor --memory-pool-size 8GB --vcores 8
The argument accepts human-readable sizes (8GB, 512MiB) or a plain byte
count. SI suffixes (KB/MB/GB) are powers of 10; IEC suffixes
(KiB/MiB/GiB) are powers of 2.
The total budget is divided equally across the executor’s vcores: each task
receives its own FairSpillPool of size memory_pool_size / vcores.
With --memory-pool-size 8GB --vcores 8, every task sees a 1 GB
pool, fully isolated from other tasks. Idle slots do not lend their share to
busy ones, which keeps task memory predictable at the cost of some unused
capacity when the executor is under-utilized.
The executor refuses to start if the per-task share would round to zero (i.e.
memory_pool_size < vcores).
When --memory-pool-size is not set, the executor behaves as before with no
memory pool installed.
Join Strategy#
Ballista defaults to sort-merge join rather than hash join. This is the opposite of DataFusion’s standalone default and reflects two facts:
DataFusion’s hash join implementation does not yet support spilling: the full build side must fit in memory per task.
Ballista executors run multiple tasks in parallel per host, so per-task build sides aggregate quickly under load and can OOM the executor.
Sort-merge join spills under memory pressure (via the executor’s memory pool, when configured), making it the safer default for distributed execution.
If you know the build side of a particular query fits comfortably in memory and you want hash-join performance, opt back in at the session level:
SET datafusion.optimizer.prefer_hash_join = true;
or in code:
let session_config = SessionConfig::new_with_ballista()
.set_bool("datafusion.optimizer.prefer_hash_join", true);
This setting applies per session and does not require restarting the scheduler or executors.
Shuffle Implementation#
Ballista exchanges data between query stages by writing the output of each upstream task to local files, which downstream tasks read either from disk (when co-located) or over Arrow Flight. Ballista uses a sort-based shuffle writer that bounds file count and memory use. Single-partition stages (a query’s final output, coalesce, and broadcast-build stages) are written directly to one file.
Sort-based shuffle#
The sort-based writer accumulates incoming batches in memory, tracking each row’s output partition. It spills the buffered batches to disk when either of two independent triggers fires:
the runtime memory pool rejects a growth request (the executor is under memory pressure — see Configuring Executor Memory Pool), or
the per-task buffered-bytes budget (
ballista.shuffle.sort_based.memory_limit_per_task_bytes) is reached. This budget is counted independently of the memory pool, so it bounds the writer’s memory even when the pool is unbounded (the default). Setting it to0disables this trigger, leaving memory-pool pressure as the sole spill signal.
Warning: setting memory_limit_per_task_bytes to 0 while the executor
uses the default unbounded memory pool disables both spill triggers. The writer
then buffers the entire task’s shuffle output in memory and never spills, which
can exhaust the executor and cause an out-of-memory failure on large inputs.
Only use 0 together with a bounded memory pool (see
Configuring Executor Memory Pool), so
pool pressure still forces spilling.
After the input stream finishes, the remaining in-memory data and any spilled batches are written into a single consolidated Arrow IPC file per input partition, alongside an index file that lets readers seek directly to a given output partition.
This produces 2 × N files instead of N × M, coalesces small batches
to a target size before writing, and bounds shuffle memory use via
spilling.
Worst-case sort-shuffle memory per executor is approximately
vcores × memory_limit_per_task_bytes, since one writer task can run per
core. Lower the per-task budget on memory-constrained executors to spill
sooner, or raise it to keep more data in memory and reduce spill I/O. Setting it
to 0 removes the budget entirely and is safe only with a bounded memory pool
(see the warning above).
The following session-level keys tune its behavior:
key |
type |
default |
description |
|---|---|---|---|
ballista.shuffle.sort_based.batch_size |
UInt64 |
8192 |
Target row count when coalescing buffered batches before they are written or spilled. |
ballista.shuffle.sort_based.memory_limit_per_task_bytes |
UInt64 |
268435456 |
Per-task buffered-bytes budget at which the writer spills to disk (256 MiB default). Counted independently of the runtime memory pool. Set to |
Adaptive Query Execution (Experimental)#
Ballista has experimental support for adaptive query execution (AQE), where the scheduler re-runs the DataFusion physical optimizer between query stages. This lets the planner make decisions using statistics collected from completed stages rather than relying solely on pre-execution estimates.
AQE is disabled by default. To enable it, set
ballista.planner.adaptive.enabled to true on your SessionConfig:
let session_config = SessionConfig::new_with_ballista()
.set_bool("ballista.planner.adaptive.enabled", true);
When AQE is enabled, the scheduler logs a warning at job submission so it is clear that AQE was used:
Adaptive Query Planning is EXPERIMENTAL, should be used for testing purposes only!
Configuration#
key |
type |
default |
description |
|---|---|---|---|
ballista.planner.adaptive.enabled |
Boolean |
false |
Enables the adaptive planner. Experimental. |
ballista.optimizer.broadcast_join_threshold_bytes |
UInt64 |
10485760 |
Byte-size threshold below which a hash join’s smaller side is broadcast ( |
ballista.optimizer.broadcast_join_threshold_rows |
UInt64 |
1000000 |
Row-count fallback threshold used when byte-size statistics are unavailable. Applies to AQE. Set to 0 to disable promotion via the row-count path. |
What AQE does today#
When AQE is enabled, the scheduler builds the stage DAG incrementally. As each shuffle stage completes, the planner re-optimizes the remaining plan and emits the next set of runnable stages. Two adaptive optimizations are currently implemented:
Join reordering. Uses runtime row counts from completed stages so the smaller side drives the join.
Broadcast join selection. When a join input’s runtime size falls under
ballista.optimizer.broadcast_join_threshold_bytes(or the row-count fallback), the smaller side is broadcast (CollectLeft) instead of shuffled.Empty stage elimination. When a completed stage produces zero rows, its downstream exchange is replaced with an empty execution node, and emptiness is propagated up the plan so downstream stages are skipped entirely.
Current limitations#
The implementation covers the happy path only. The following are known to be missing or incomplete:
Executor failure handling on the AQE path (#1986)
Dynamic coalescing of shuffle partitions (#1987)
Switching from hash join to sort-merge join based on runtime statistics (#1988)
Switching from streaming aggregation to hash aggregation based on runtime statistics (#1989)
Until these gaps are closed, AQE should be used for testing and experimentation rather than production workloads. See issue #1359 for the tracking epic and ongoing work.
Push-based vs Pull-based Task Scheduling#
Ballista supports both push-based and pull-based task scheduling. It is recommended that you try both to determine which is the best for your use case.
Pull-based scheduling works in a similar way to Apache Spark and push-based scheduling can result in lower latency.
The scheduling policy can be specified in the --scheduler-policy parameter when starting the scheduler and executor
processes. The default is pull-staged.
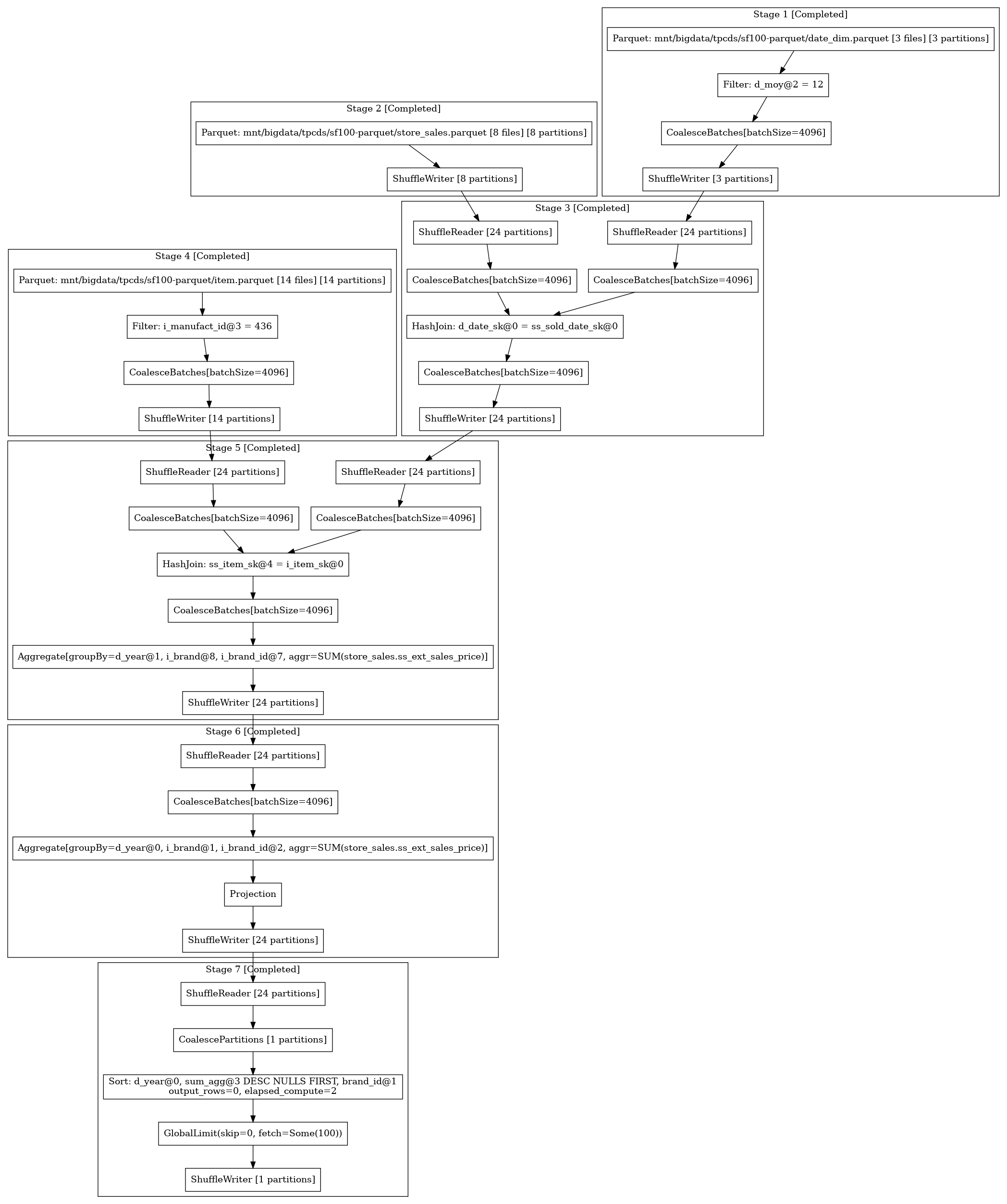
Viewing Query Plans and Metrics#
The scheduler provides a REST API for monitoring jobs. See the scheduler documentation for more information.
This is optional scheduler feature which should be enabled with rest-api feature
To download a query plan in dot format from the scheduler, submit a request to the following API endpoint
http://localhost:50050/api/job/{job_id}/dot
The resulting file can be converted into an image using graphviz:
dot -Tpng query.dot > query.png
Here is an example query plan: