Apache DataFusion Comet 0.1.0 Release
Posted on: Sat 20 July 2024 by pmc
The Apache DataFusion PMC is pleased to announce the first official source release of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for improved performance and efficiency without requiring any code changes.
Comet runs on commodity hardware and aims to provide 100% compatibility with Apache Spark. Any operators or expressions that are not fully compatible will fall back to Spark unless explicitly enabled by the user. Refer to the compatibility guide for more information.
This release covers five months of development work since the project was donated to the Apache DataFusion project and is the result of merging 343 PRs from 41 contributors. See the change log for more information.
This first release supports 15 data types, 13 operators, and 106 expressions. Comet is compatible with Apache Spark versions 3.3, 3.4, and 3.5. There is also experimental support for preview versions of Spark 4.0.
Project Status¶
The project's recent focus has been on fixing correctness and stability issues and implementing additional native operators and expressions so that a broader range of queries can be executed natively.
Here are some of the highlights since the project was donated:
- Implemented native support for:
- SortMergeJoin
- HashJoin
- BroadcastHashJoin
- Columnar Shuffle
- More aggregate expressions
- Window aggregates
- Many Spark-compatible CAST expressions
- Implemented a simple Spark Fuzz Testing utility to find correctness issues
- Published a User Guide and Contributors Guide
- Created a DataFusion Benchmarks repository with scripts and documentation for running benchmarks derived
from TPC-H and TPC-DS with DataFusion and Comet
Current Performance¶
Comet already delivers a modest performance speedup for many queries, enabling faster data processing and shorter time-to-insights.
We use benchmarks derived from the industry standard TPC-H and TPC-DS benchmarks for tracking progress with performance. The following chart shows the time it takes to run the 22 TPC-H queries against 100 GB of data in Parquet format using a single executor with eight cores. See the Comet Benchmarking Guide for details of the environment used for these benchmarks.
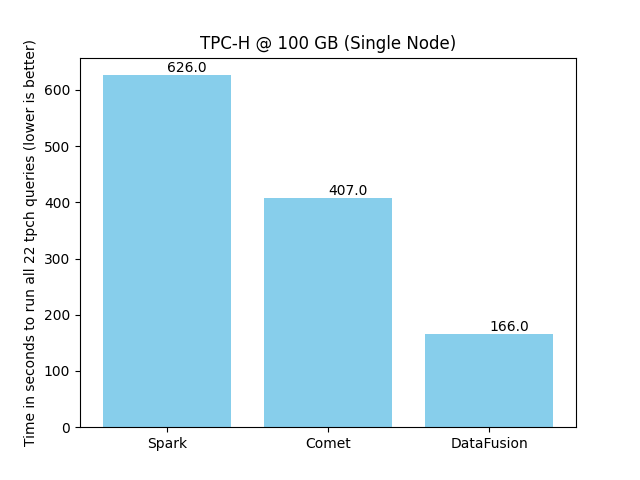
Comet reduces the overall execution time from 626 seconds to 407 seconds, a 54% speedup (1.54x faster).
Running the same queries with DataFusion standalone using the same number of cores results in a 3.9x speedup compared to Spark. Although this isn’t a fair comparison (DataFusion does not have shuffle or match Spark semantics in some cases, for example), it does give some idea about the potential future performance of Comet. Comet aims to provide a 2x-4x speedup for a wide range of queries once more operators and expressions can run natively.
The following chart shows how much Comet currently accelerates each query from the benchmark.
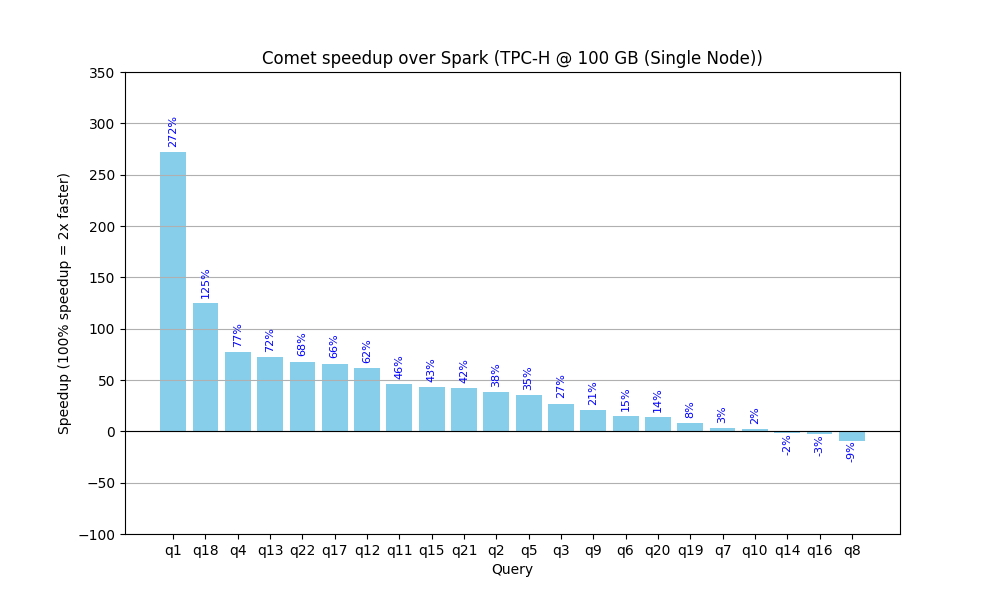
These benchmarks can be reproduced in any environment using the documentation in the Comet Benchmarking Guide. We encourage you to run these benchmarks in your environment or, even better, try Comet out with your existing Spark jobs.
Roadmap¶
Comet is an open-source project, and contributors are welcome to work on any features they are interested in, but here are some current focus areas.
- Improve Performance & Reliability:
- Implement the remaining features needed so that all TPC-H queries can run entirely natively
- Implement spill support in SortMergeJoin
- Enable columnar shuffle by default
- Fully support Spark version 4.0.0
- Support more Spark operators and expressions
- We would like to support many more expressions natively in Comet, and this is a great place to start contributing. The contributors' guide has a section covering adding support for new expressions.
- Move more Spark expressions into the datafusion-comet-spark-expr crate. Although the main focus of the Comet project is to provide an accelerator for Apache Spark, we also publish a standalone crate containing Spark-compatible expressions that can be used by any project using DataFusion, without adding any dependencies on JVM or Apache Spark.
- Release Process & Documentation
- Implement a binary release process so that we can publish JAR files to Maven for all supported platforms
- Add documentation for running Spark and Comet in Kubernetes, and add example Dockerfiles.
Getting Involved¶
The Comet project welcomes new contributors. We use the same Slack and Discord channels as the main DataFusion project, and there is a Comet community video call held every four weeks on Wednesdays at 11:30 a.m. Eastern Time, which is 16:30 UTC during Eastern Standard Time and 15:30 UTC during Eastern Daylight Time. See the Comet Community Meeting Google Document for the next scheduled meeting date, the video call link, and recordings of previous calls.
The easiest way to get involved is to test Comet with your current Spark jobs and file issues for any bugs or performance regressions that you find. See the Getting Started guide for instructions on downloading and installing Comet.
There are also many good first issues waiting for contributions.
Comments
We use Giscus for comments, powered by GitHub Discussions. To respect your privacy, Giscus and comments will load only if you click "Show Comments"