Dynamic Filters: Passing Information Between Operators During Execution for 25x Faster Queries
Posted on: Wed 10 September 2025 by Adrian Garcia Badaracco (Pydantic), Andrew Lamb (InfluxData)
This blog post introduces the query engine optimization techniques called TopK and dynamic filters. We describe the motivating use case, how these optimizations work, and how we implemented them with the Apache DataFusion community to improve performance by an order of magnitude for some query patterns.
Motivation and Results¶
The main commercial product at Pydantic, Logfire, is an observability platform built on DataFusion. One of the most common workflows / queries is "show me the last K traces" which translates to a query similar to:
SELECT * FROM records ORDER BY start_timestamp DESC LIMIT 1000;
We noticed this was pretty slow, even though DataFusion has long had the
classic TopK optimization (described below). After implementing the dynamic
filter techniques described in this blog, we saw performance improve by over 10x
for this query pattern, and are applying the optimization to other queries and
operators as well.
Let's look at some preliminary numbers, using ClickBench, which has the same pattern as our motivating example:
SELECT * FROM hits WHERE "URL" LIKE '%google%' ORDER BY "EventTime" LIMIT 10;

Figure 1: Execution times for ClickBench Q23 with and without dynamic filters (DF)1, and late materialization (LM)2 for different partitions / core usage. Dynamic filters alone (yellow) and late materialization alone (red) show a large improvement over the baseline (blue). When both optimizations are enabled (green) performance improves by up to 22x. See the appendix for more measurement details.
Background: TopK and Dynamic Filters¶
To explain how dynamic filters improve query performance, we first need to explain the so-called "TopK" optimization. To do so, we will use a simplified version of ClickBench Q23:
SELECT *
FROM hits
ORDER BY "EventTime"
LIMIT 10
A straightforward, though slow, plan to answer this query is shown in Figure 2.
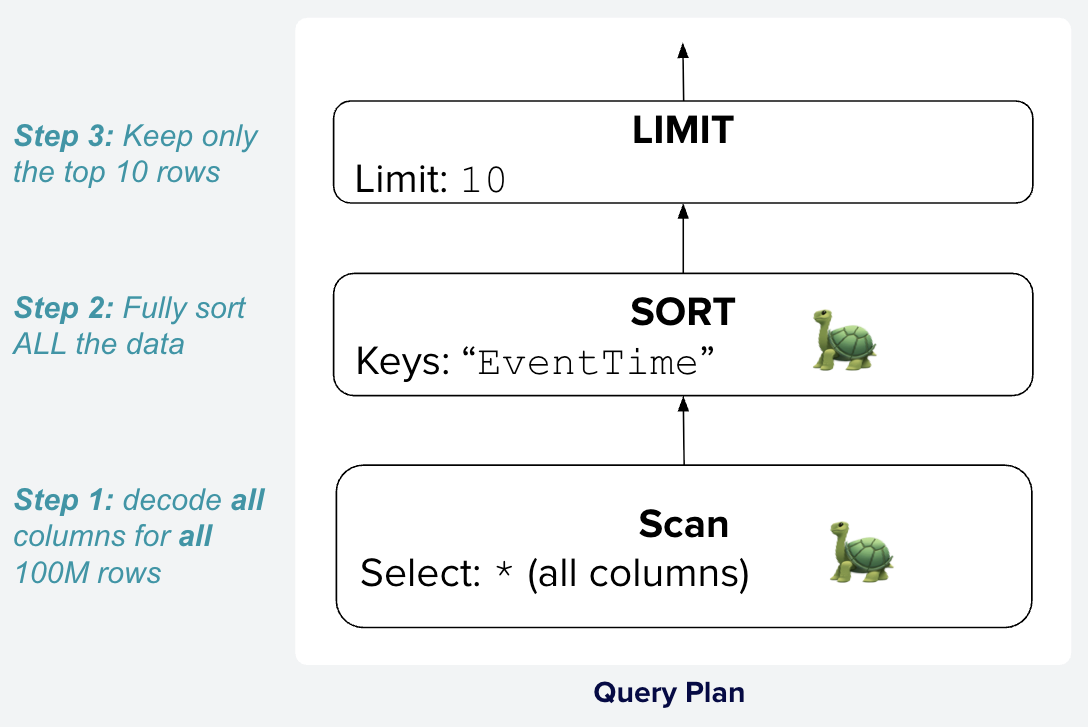
Figure 2: Simple Query Plan for ClickBench Q23. Data flows in plans from the
scan at the bottom to the limit at the top. This plan reads all 100M rows of the
hits table, sorts them by EventTime, and then discards everything except the top 10 rows.
This naive plan requires substantial effort as all columns from all rows are decoded and sorted, even though only 10 are returned.
High-performance query engines typically avoid the expensive full sort with a specialized operator that tracks the current top rows using a heap, rather than sorting all the data. For example, this operator is called TopK in DataFusion, SortWithLimit in Snowflake, and topn in DuckDB. The plan for Q23 using this specialized operator is shown in Figure 3.
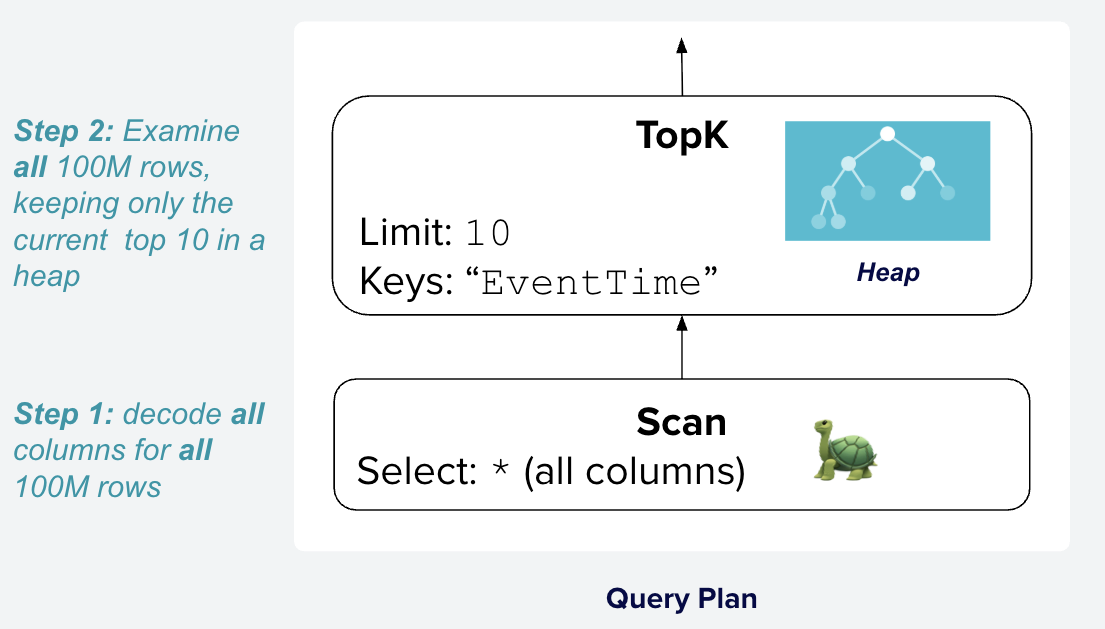
Figure 3: Query plan for Q23 in DataFusion using the TopK operator. This
plan still reads all 100M rows of the hits table, but instead of first sorting
them all by EventTime, the TopK operator keeps track of the current top 10
rows using a min/max heap. Credit to Visualgo for the
heap icon
Figure 3 is better, but it still reads and decodes all 100M rows of the hits table,
which is often unnecessary once we have found the top 10 rows. For example,
while running the query, if the current top 10 rows all have EventTime in
2025, then any subsequent rows with EventTime in 2024 or earlier can be
skipped entirely without reading or decoding them. This technique is especially
effective at skipping entire files or row groups if the top 10 values are in the
first few files read, which is very common when the
data insert order is approximately the same as the timestamp order.
Leveraging this insight is the key idea behind dynamic filters, which introduce a runtime mechanism for the TopK operator to provide the current top values to the scan operator, allowing it to skip unnecessary rows, entire files, or portions of files. The plan for Q23 with dynamic filters is shown in Figure 4.
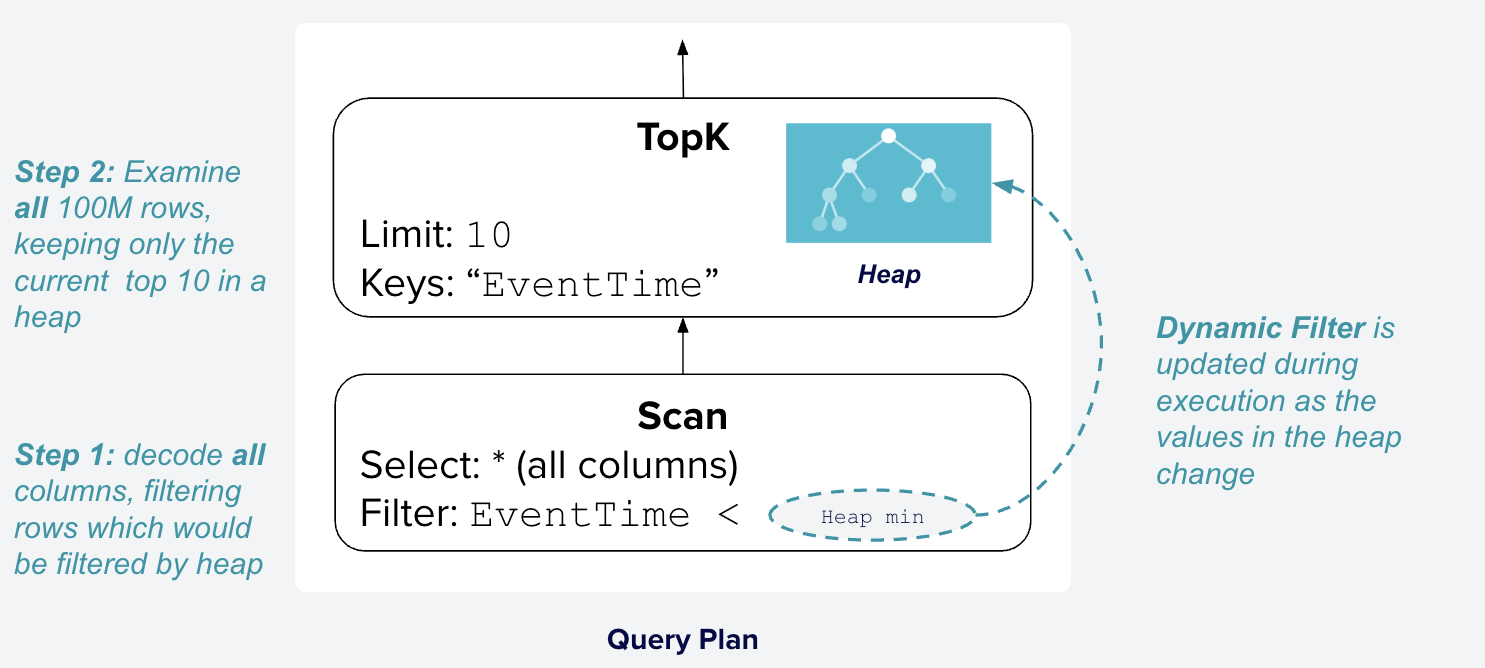
Figure 4: Query plan for Q23 in DataFusion with specialized TopK operator
and dynamic filters. The TopK operator provides the minimum EventTime of the
current top 10 rows to the scan operator, allowing it to skip rows with
EventTime later than that value. The scan operator uses this dynamic filter
to skip unnecessary files and rows, reducing the amount of data that needs to
be read and processed.
Worked Example¶
To make dynamic filters more concrete, here is a fully worked example. Imagine
we have a table records with a column start_timestamp and we are running the
motivating query:
SELECT *
FROM records
ORDER BY start_timestamp
DESC LIMIT 3;
In this example, at some point during execution, the heap in the TopK operator
will contain the actual 3 most recent values, which might be:
| start_timestamp |
|---|
| 2025-08-16T20:35:15.00Z |
| 2025-08-16T20:35:14.00Z |
| 2025-08-16T20:35:13.00Z |
Since 2025-08-16T20:35:13.00Z is the smallest of these values, we know that
any subsequent rows with start_timestamp less than or equal to this value
cannot possibly be in the top 3, and can be skipped entirely.
This knowledge is encoded in a filter of the form start_timestamp >
'2025-08-16T20:35:13.00Z'. If we knew the correct timestamp value before
starting the plan, we could simply write:
SELECT *
FROM records
WHERE start_timestamp > '2025-08-16T20:35:13.00Z' -- Filter to skip rows
ORDER BY start_timestamp DESC
LIMIT 3;
And DataFusion's existing hierarchical pruning (described in this blog) would skip reading unnecessary files and row groups, and only decode the necessary rows.
However, obviously when we start running the query we don't have the value
'2025-08-16T20:35:13.00Z', so what DataFusion now does is put a dynamic filter
into the plan instead, which you can think of as a function call like
dynamic_filter(), something like this:
SELECT *
FROM records
WHERE dynamic_filter() -- Updated during execution as we know more
ORDER BY start_timestamp DESC
LIMIT 3;
In this case, dynamic_filter() initially has the value true (passes all
rows) but will be progressively updated by the TopK operator as the query
progresses to filter more and more rows. Note that while we are using SQL for
illustrative purposes in this example, these optimizations are done at the
physical plan (ExecutionPlan) level — and they apply equally to SQL, DataFrame
APIs, and custom query languages built with DataFusion.
TopK + Dynamic Filters¶
As mentioned above, DataFusion has a specialized sort operator named TopK that
only keeps K rows in memory. For a DESC sort order, each new input batch is
compared against the current K largest values, and then the current K rows
possibly get replaced with any new input rows that are larger. The code is
here.
Prior to dynamic filters, DataFusion had no early termination: it would read the
entire records table even if it already had the top K rows because it
still had to check that there were no rows that had larger start_timestamp.
You can see how this is a problem if you have 2 years' worth of time-series data
and the largest 1000 values of start_timestamp are likely within the first
few files read. Even once the TopK operator has seen 1000 timestamps (e.g. on
August 16th, 2025), DataFusion would still read all remaining files (e.g. even
those that contain data only from 2024) just to make sure.
InfluxData optimized a similar query pattern in InfluxDB IOx using another
operator called ProgressiveEvalExec. However, ProgressiveEvalExec requires that the data
is already sorted and a careful analysis of ordering to prove that it can be
used and still produce correct results. That is not the case for Logfire data (and many other datasets):
data tends to be roughly sorted (e.g. if you append to files as you receive
it) but that does not guarantee that it is fully sorted, either within or between
files.
We discussed possible solutions with the community, and ultimately decided to implement generic "dynamic filters", which are general enough to be used in joins as well (see next section). Our implementation appears very similar to recently announced optimizations in closed-source, commercial systems such as Accelerating TopK Queries in Snowflake, or self-sharpening runtime filters in Alibaba Cloud's PolarDB, and we are excited that we can offer similar features in an open source query engine like DataFusion.
At the query plan level, Q23 looks like this before it is executed:
┌───────────────────────────┐
│ SortExec(TopK) │
│ -------------------- │
│ EventTime@4 ASC NULLS LAST│
│ │
│ limit: 10 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ DataSourceExec │
│ -------------------- │
│ files: 100 │
│ format: parquet │
│ │
│ predicate: │
│ CAST(URL AS Utf8View) LIKE│
│ %google% AND true │
└───────────────────────────┘
Figure 5: Physical plan for ClickBench Q23 prior to execution. The dynamic
filter is shown as true in the predicate field of the DataSourceExec
operator.
The dynamic filter is updated by the SortExec(TopK) operator during execution
as shown in Figure 6.
┌───────────────────────────┐
│ SortExec(TopK) │
│ -------------------- │
│ EventTime@4 ASC NULLS LAST│
│ │
│ limit: 10 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ DataSourceExec │
│ -------------------- │
│ files: 100 │
│ format: parquet │
│ │
│ predicate: │
│ CAST(URL AS Utf8View) LIKE│
│ %google% AND │
│ EventTime < 1372713773.0 │
└───────────────────────────┘
Figure 6: Physical plan for ClickBench Q23 after execution. The dynamic filter has been
updated to EventTime < 1372713773.0, which allows the DataSourceExec operator to skip
files and rows that do not match the filter.
Hash Join + Dynamic Filters¶
We spent significant effort to make dynamic filters a general-purpose optimization (see the Extensibility section below for more details). Instead of a one-off optimization for TopK queries, we created a general mechanism for passing information between operators during execution that can be used in multiple contexts. We have already used the dynamic filter infrastructure to improve hash joins by implementing a technique called sideways information passing, which is similar to Bloom filter joins in Apache Spark. See issue #7955 for more details.
In a Hash Join, the query engine picks one input of the join to be the "build" input and the other input to be the "probe" side.
-
First, the build side is loaded into memory, and turned into a hash table.
-
Then, the probe side is scanned, and matching rows are found by looking in the hash table. Non-matching rows are discarded and thus joins often act as filters.
Many hash joins act as selective filters for rows from the probe side (when only
a small number of rows are matched), so it is natural to use the same dynamic
filter technique. DataFusion 50.0.0 pushes down knowledge of what keys exist on
the build side into the scan of the probe side with a dynamic filter based on
min/max join key values. For example, if the build side only has keys in the
range [100, 200], then DataFusion will filter out all probe rows with keys
outside that range during the scan.
This simple approach is fast to evaluate and the filter improves performance significantly when combined with statistics pruning, late materialization, and other optimizations as shown in Figure 7.

Figure 7: Join performance with and without dynamic filters. In DataFusion 49.0.2 the join takes 2.5s, even with late materialization (LM) enabled. In DataFusion 50.0.0 with dynamic filters enabled (the default), the join takes only 0.7s, a 5x improvement. With both dynamic filters and late materialization, DataFusion 50.0.0 takes 0.1s, a 25x improvement. See this discussion for more details.
You can see dynamic join filters in action with the following example.
-- create two tables: small_table with 1K rows and large_table with 100K rows
COPY (SELECT i as k, i as v FROM generate_series(1, 1000) t(i)) TO 'small_table.parquet';
CREATE EXTERNAL TABLE small_table STORED AS PARQUET LOCATION 'small_table.parquet';
COPY (SELECT i as k FROM generate_series(1, 100000) t(i)) TO 'large_table.parquet';
CREATE EXTERNAL TABLE large_table STORED AS PARQUET LOCATION 'large_table.parquet';
-- Join the two tables, with a filter on small_table
EXPLAIN
SELECT *
FROM small_table JOIN large_table ON small_table.k = large_table.k
WHERE small_table.v >= 50;
Note there are no filters on the large_table in the initial query, but a
dynamic filter is introduced by DataFusion on the large_table scan. As the
small_table is read and the hash table is built, the dynamic filter is updated
to become more and more effective. Before execution, the plan
looks like this:
+---------------+------------------------------------------------------------+
| plan_type | plan |
+---------------+------------------------------------------------------------+
| physical_plan | ┌───────────────────────────┐ |
| | │ CoalesceBatchesExec │ |
| | │ -------------------- │ |
| | │ target_batch_size: │ |
| | │ 8192 │ |
| | └─────────────┬─────────────┘ |
| | ┌─────────────┴─────────────┐ |
| | │ HashJoinExec │ |
| | │ -------------------- ├──────────────┐ |
| | │ on: (k = k) │ │ |
| | └─────────────┬─────────────┘ │ |
| | ┌─────────────┴─────────────┐┌─────────────┴─────────────┐ |
| | │ CoalescePartitionsExec ││ RepartitionExec │ |
| | │ ││ -------------------- │ |
| | │ ││ partition_count(in->out): │ |
| | │ ││ 1 -> 16 │ |
| | │ ││ │ |
| | │ ││ partitioning_scheme: │ |
| | │ ││ RoundRobinBatch(16) │ |
| | └─────────────┬─────────────┘└─────────────┬─────────────┘ |
| | ┌─────────────┴─────────────┐┌─────────────┴─────────────┐ |
| | │ CoalesceBatchesExec ││ DataSourceExec │ |
| | │ -------------------- ││ -------------------- │ |
| | │ target_batch_size: ││ files: 1 │ |
| | │ 8192 ││ format: parquet │ |
| | │ ││ predicate: true │ |
| | └─────────────┬─────────────┘└───────────────────────────┘ |
| | ┌─────────────┴─────────────┐ |
| | │ FilterExec │ |
| | │ -------------------- │ |
| | │ predicate: v >= 50 │ |
| | └─────────────┬─────────────┘ |
| | ┌─────────────┴─────────────┐ |
| | │ RepartitionExec │ |
| | │ -------------------- │ |
| | │ partition_count(in->out): │ |
| | │ 1 -> 16 │ |
| | │ │ |
| | │ partitioning_scheme: │ |
| | │ RoundRobinBatch(16) │ |
| | └─────────────┬─────────────┘ |
| | ┌─────────────┴─────────────┐ |
| | │ DataSourceExec │ |
| | │ -------------------- │ |
| | │ files: 1 │ |
| | │ format: parquet │ |
| | │ predicate: v >= 50 │ |
| | └───────────────────────────┘ |
| | |
+---------------+------------------------------------------------------------+
Figure 8: Physical plan for the join query before execution. The left input
to the join is the build side, which scans small_table and applies the filter
v >= 50. The right input to the join is the probe side, which scans large_table
and has the dynamic filter (shown here as the placeholder true).
Dynamic Filter Extensibility: Custom ExecutionPlan Operators¶
We went to great efforts to ensure that dynamic filters are not a hardcoded black box that only works for internal operators. This is important not only for software maintainability, but also because DataFusion is used in many different contexts including advanced custom operators specialized for specific use cases.
Dynamic filter creation and pushdown are implemented as methods on the
ExecutionPlan trait. Thus, it is possible for user-defined, custom
ExecutionPlans to work with dynamic filters with little to no modification. We
also provide an extensive library of helper structs and functions, so it often
takes only 1-2 lines of code to implement filter pushdown support or a source of
dynamic filters for custom operators.
This approach has already paid off, and we know of community members who have implemented support for dynamic filter pushdown using preview releases of DataFusion 50.0.0.
Design of Scan Operator Integration¶
A core design decision is to represent dynamic filters as Arc<dyn
PhysicalExpr>, the same interface as all other expressions in DataFusion. This
means that DataSourceExec and other scan operators do not require special
logic to handle dynamic filters, and existing filter pushdown logic works
without modification. We did add some new functionality to PhysicalExpr to
make working with dynamic filters more performant for specific use cases:
-
PhysicalExpr::generation() -> u64: to track if a tree of filters has changed (e.g. it has a dynamic filter that has been updated). For example, if a predicate changes fromc1 = 'a' AND DynamicFilter [ c2 > 1]toc1 = 'a' AND DynamicFilter [ c2 > 2]the generation value will also change so operators know if they should re-evaluate the filter against static data like file or row group level statistics. This is used in the ListingTable provider to do early termination of reading a file if the filter is updated mid scan to skip the entire file, without needlessly re-evaluating file level statistics on each batch. -
PhysicalExpr::snapshot() -> Arc<dyn PhysicalExpr>: to create a snapshot of the filter at a given point in time. Dynamic filters use this to return the current value of their inner static filter. This can be used to serialize the filter across the network for distributed engines or pass to systems that support specific static filter patterns (e.g. stats pruning rewrites).
This is all implemented in the DynamicFilterPhysicalExpr struct.
Another important design point was handling concurrency and information
flow. In early designs, the scan polled the source operators on every row /
batch, which had significant overhead. The final design is a "push" model where
the scan path has minimal locking and the write path (e.g. the TopK
operator) is responsible for updating the filter. You can think of
DynamicFilterPhysicalExpr as an Arc<RwLock<Arc<dyn PhysicalExpr>>>, which
allows the TopK operator to update the filter without blocking the scan
operator.
Future Work¶
Although we've made great progress and DataFusion now has one of the most advanced open-source dynamic filter / sideways information passing implementations that we know of, we see many areas of future improvement such as:
-
Support for more types of joins: This optimization is only implemented for
INNERhash joins so far, but it could be implemented for other join algorithms (e.g. nested loop joins) and join types (e.g.LEFT OUTER JOIN). -
Push down entire hash tables to the scan operator: Improve the representation of the dynamic filter beyond min/max values to improve performance for joins with many distinct matching keys that are not naturally ordered or have significant skew.
-
Use file level statistics to order files to match the
ORDER BYclause as much as possible. This can help TopK dynamic filters be more effective at pruning by skipping more work earlier in the scan.
Acknowledgements¶
Thank you to Pydantic and InfluxData for supporting our work on DataFusion and open source in general. Thank you to zhuqi-lucas, xudong963, Dandandan, and LiaCastaneda, for helping with the dynamic join filter implementation and testing. Thank you to nuno-faria for providing join performance results and djanderson for their helpful review comments.
About the Authors¶
Adrian Garcia Badaracco is a Founding Engineer at Pydantic, and an Apache DataFusion committer.
Andrew Lamb is a Staff Engineer at InfluxData, and a member of the Apache DataFusion and Apache Arrow PMCs. He has been working on databases and related systems for more than 20 years.
About DataFusion¶
Apache DataFusion is an extensible query engine toolkit, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion and similar technology are part of the next generation “Deconstructed Database” architectures, where new systems are built on a foundation of fast, modular components, rather than as a single tightly integrated system.
The DataFusion community is always looking for new contributors to help improve the project. If you are interested in learning more about how query execution works, help document or improve the DataFusion codebase, or just try it out, we would love for you to join us.
Footnotes¶
1 Dynamic Filters (DF) refers to the optimization described in this blog post. The TopK operator will generate a filter that is applied to the scan operators, which will first be used to skip rows and then as we open new files (if there are more to open) it will be used to skip entire files that do not match the filter.
2 Late Materialization (LM) refers to the optimization described in this blog post. Late Materialization is particularly effective when combined with dynamic filters as it can apply filters during a scan. Without late materialization, dynamic filters can only be used to prune row groups or entire files, which will be less effective if the files themselves are large or the top values are not in the first few files read.
Appendix¶
Queries and Data¶
Figure 1: ClickBench Q23¶
-- Data was downloaded using apache/datafusion -> benchmarks/bench.sh -> ./benchmarks/bench.sh data clickbench_partitioned
create external table hits stored as parquet location 'benchmarks/data/hits_partitioned';
-- Must set for ClickBench hits_partitioned dataset. See https://github.com/apache/datafusion/issues/16591
set datafusion.execution.parquet.binary_as_string = true;
-- Only matters if pushdown_filters is enabled but they don't get enabled together sadly
set datafusion.execution.parquet.reorder_filters = true;
set datafusion.execution.target_partitions = 1; -- or set to 12 to use multiple cores
set datafusion.optimizer.enable_dynamic_filter_pushdown = false;
set datafusion.execution.parquet.pushdown_filters = false;
explain analyze
SELECT *
FROM hits
WHERE "URL" LIKE '%google%'
ORDER BY "EventTime"
LIMIT 10;
| dynamic filters | late materialization | cores | time (s) |
|---|---|---|---|
| False | False | 1 | 32.039 |
| False | True | 1 | 16.903 |
| True | False | 1 | 18.195 |
| True | True | 1 | 1.42 |
| False | False | 12 | 5.04 |
| False | True | 12 | 2.37 |
| True | False | 12 | 5.055 |
| True | True | 12 | 0.602 |