Apache DataFusion Comet 0.11.0 Release
Posted on: Tue 21 October 2025 by pmc
The Apache DataFusion PMC is pleased to announce version 0.11.0 of the Comet subproject.
Comet is an accelerator for Apache Spark that translates Spark physical plans to DataFusion physical plans for improved performance and efficiency without requiring any code changes.
This release covers approximately five weeks of development work and is the result of merging 131 PRs from 15 contributors. See the change log for more information.
Release Highlights¶
Parquet Modular Encryption Support¶
Spark supports Parquet Modular Encryption to independently encrypt column values and metadata. Furthermore, Spark supports custom encryption factories for users to provide their own key-management service (KMS) implementations. Thanks to a number of contributions in upstream DataFusion and arrow-rs, Comet now supports Parquet Modular Encryption with Spark KMS for native readers, enabling secure reading of encrypted Parquet files in production environments.
Improved Memory Management¶
Comet 0.11.0 introduces significant improvements to memory management, making it easier to deploy and more resilient to out-of-memory conditions:
- Changed default memory pool: The default off-heap memory pool has been changed from
greedy_unifiedtofair_unified, providing better memory fairness across operations - Off-heap deployment recommended: To simplify configuration and improve performance, Comet now expects to be deployed with Spark's off-heap memory configuration. On-heap memory is still available for development and debugging, but is not recommended for deployment
- Better disk management: The DiskManager
max_temp_directory_sizeis now configurable for better control over temporary disk usage - Enhanced safety: Memory pool operations now use checked arithmetic operations to prevent overflow issues
These changes make Comet significantly easier to configure and deploy in production environments.
Improved Apache Spark 4.0 Support¶
Comet has improved its support for Apache Spark 4.0.1 with several important enhancements:
- Updated support from Spark 4.0.0 to Spark 4.0.1
- Spark 4.0 is now included in the release build script
- Expanded ANSI mode compatibility with several new implementations:
- ANSI evaluation mode arithmetic operations
- ANSI mode integral divide
- ANSI mode rounding functions
- ANSI mode remainder function
Spark 4.0 compatible jar files are now available on Maven Central. See the installation guide for instructions on using published jar files.
Complex Types for Columnar Shuffle¶
ashdnazg submitted a fantastic refactoring PR that simplified the logic for writing rows in Comet’s JVM-based, columnar shuffle. A benefit of this refactoring is better support for complex types (e.g., structs, lists, and arrays) in columnar shuffle. Comet no longer falls back to Spark to shuffle these types, enabling native acceleration for queries involving nested data structures. This enhancement significantly expands the range of queries that can benefit from Comet's columnar shuffle implementation.
RangePartitioning for Native Shuffle¶
Comet's native shuffle now supports RangePartitioning, providing better performance for operations that require range-based data distribution. Comet now matches Spark behavior for computing and distributing range boundaries, and serializes them to native execution for faster shuffle operations.
New Functionality¶
The following SQL functions are now supported:
weekday- Extract day of week from datelpad- Left pad a string with column support for pad lengthrpad- Right pad a string with column support and additional character supportreverse- Support for ArrayType input in addition to stringscount(distinct)- Native support without falling back to Sparkbit_get- Get bit value at position
New expression capabilities include:
- Nested array literal support
- Array-to-string cast support
- Spark-compatible cast from integral to decimal types
- Support for decimal type to boolean cast
- More date part expressions
Performance Improvements¶
- Improved BroadcastExchangeExec conversion for better broadcast join performance
- Use of DataFusion's native
count_udafinstead ofSUM(IF(expr IS NOT NULL, 1, 0)) - New configuration from shared conf to reduce overhead
- Buffered index writes to reduce system calls in shuffle operations
Comet 0.11.0 TPC-H Performance¶
Comet 0.11.0 continues to deliver significant performance improvements over Spark. In our TPC-H benchmarks, Comet reduced overall query runtime from 687 seconds to 302 seconds when processing 100 GB of Parquet data using a single 8-core executor, achieving a 2.2x speedup.
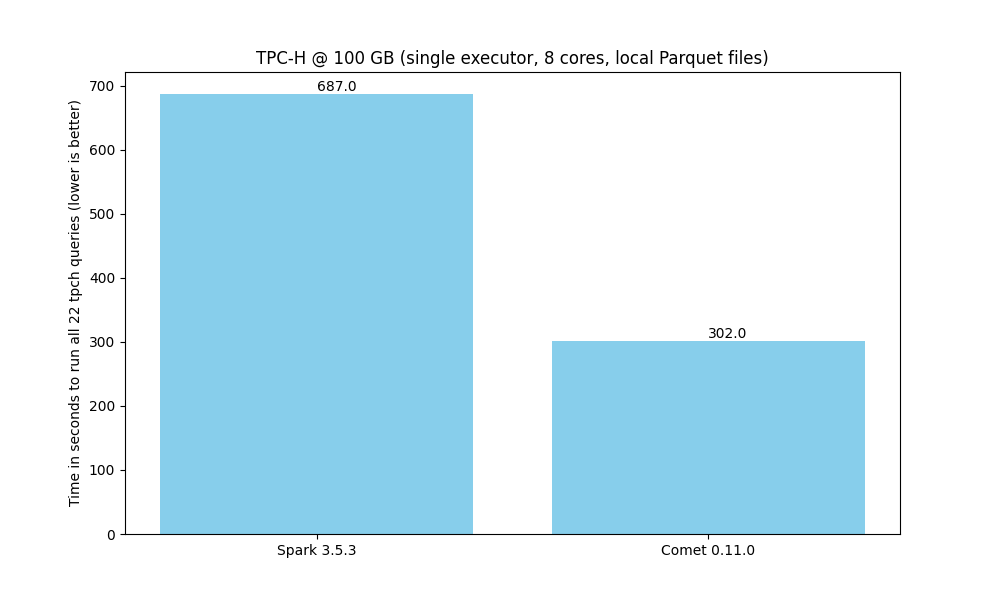
The performance gains are consistent across individual queries, with most queries showing substantial improvements:
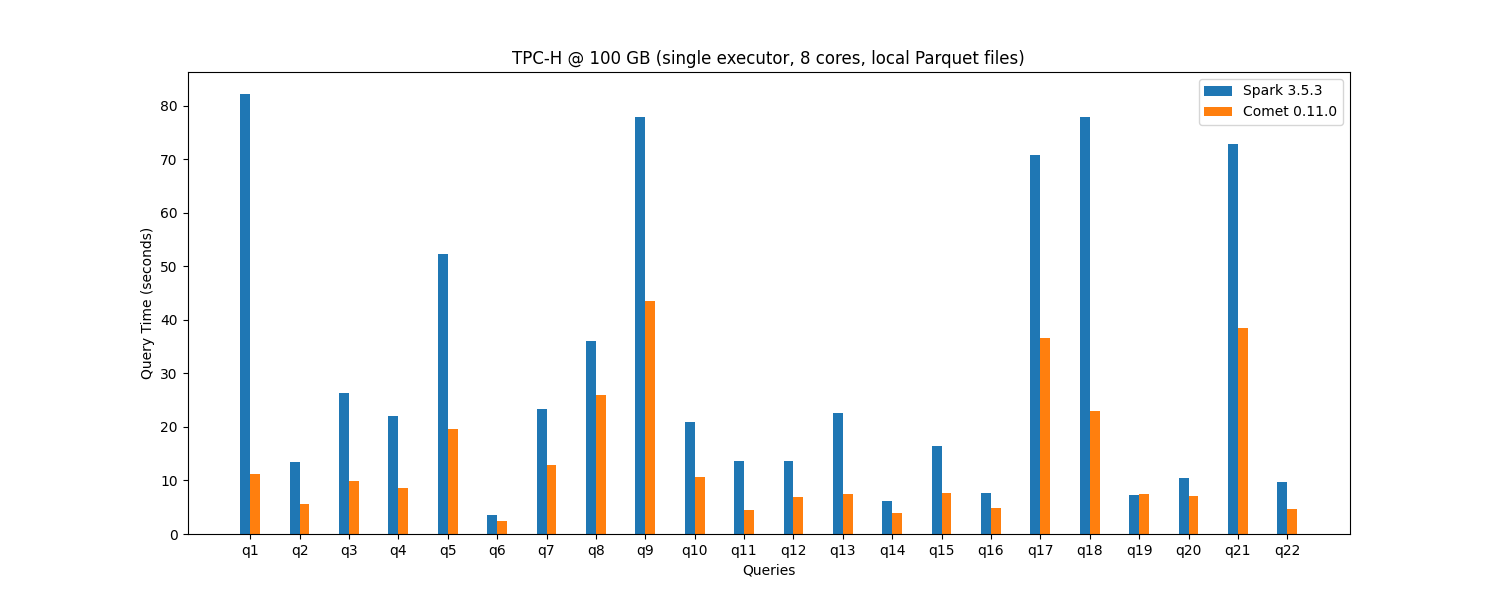
You can reproduce these benchmarks using our Comet Benchmarking Guide. We encourage you to run your own performance tests with your workloads.
Apache Iceberg Support¶
- Updated support for Apache Iceberg 1.9.1
- Additional Parquet-independent API improvements for Iceberg integration
- Improved resource management in Iceberg reader instances
UX Improvements¶
- Added plan conversion statistics to extended explain info for better observability
- Improved fallback information to help users understand when and why Comet falls back to Spark
- Added
backtracefeature to simplify enabling native backtraces inCometNativeException - Native log level is now configurable via Comet configuration
Bug Fixes¶
- Resolved issues with reused broadcast plans in non-AQE mode
- Fixed thread safety in setNumPartitions
- Improved error handling when resolving S3 bucket region
- Fixed byte array literal casting issues
- Corrected subquery filter pushdown behavior for native_datafusion scan
Documentation Updates¶
- Updated documentation for native shuffle configuration and tuning
- Added documentation for ANSI mode support in various functions
- Improved EC2 benchmarking guide
- Split configuration guide into different sections (scan, exec, shuffle, etc.) for better organization
- Various clarifications and improvements throughout the documentation
Spark Compatibility¶
- Spark 3.4.3 with JDK 11 & 17, Scala 2.12 & 2.13
- Spark 3.5.4 through 3.5.6 with JDK 11 & 17, Scala 2.12 & 2.13
- Spark 4.0.1 with JDK 17, Scala 2.13
We are looking for help from the community to fully support Spark 4.0.1. See EPIC: Support 4.0.0 for more information.
Getting Involved¶
The Comet project welcomes new contributors. We use the same Slack and Discord channels as the main DataFusion project and have a weekly DataFusion video call.
The easiest way to get involved is to test Comet with your current Spark jobs and file issues for any bugs or performance regressions that you find. See the Getting Started guide for instructions on downloading and installing Comet.
There are also many good first issues waiting for contributions.
Comments
We use Giscus for comments, powered by GitHub Discussions. To respect your privacy, Giscus and comments will load only if you click "Show Comments"