Apache DataFusion 54.0.0 Released
Posted on: Fri 12 June 2026 by pmc
We are proud to announce the release of DataFusion 54.0.0. This post highlights
some of the major improvements since DataFusion 53.0.0. Notable additions
include LATERAL joins, SQL lambda functions, and a new Avro reader, alongside
significant join, scan, and planning performance improvements. The complete list
of changes is available in the changelog. This release represents roughly 11
weeks of development and 740 commits. Thanks to the 139 contributors
(a new record!) for making it possible.
Performance Improvements 🚀¶
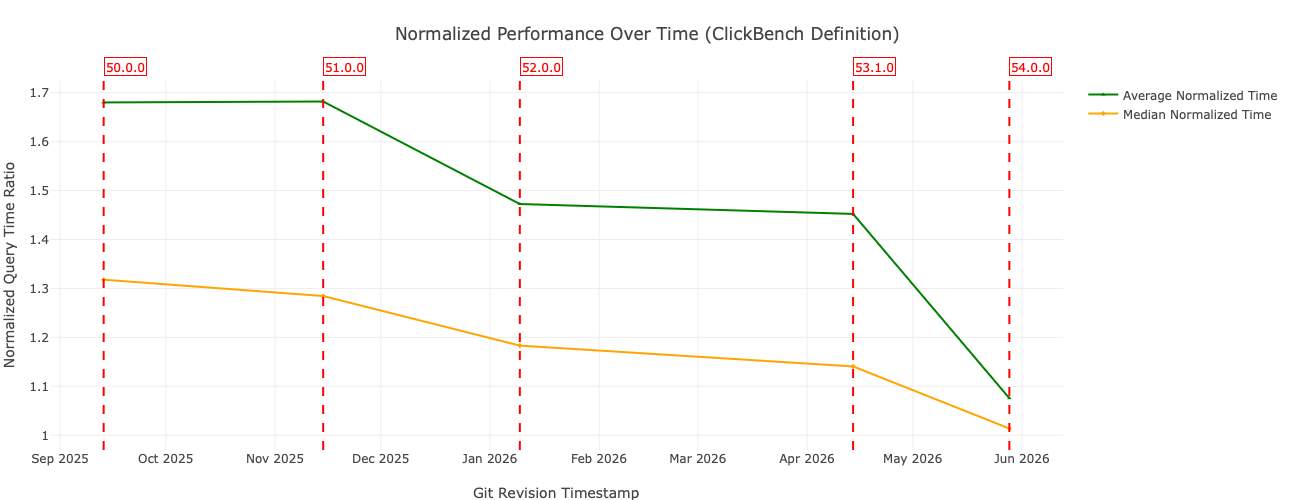
Figure 1: Average and median normalized execution times for DataFusion 54.0.0 on ClickBench queries, compared to previous releases. Query times are normalized using the ClickBench definition. See the DataFusion Benchmarking Page for more details.
We continue to make significant performance improvements in DataFusion, as explained below. This release prunes more redundant work out of plans and makes joins, repartitioning, scans, and many built-in functions faster.
Execution Operator Improvements¶
Physical Execution of Uncorrelated Scalar Subqueries:
DataFusion previously executed an uncorrelated scalar subquery (one that doesn't
depend on the outer query) by rewriting it into a join. DataFusion 54 instead
evaluates it once with a new physical operator. This lets functions use their
specialized scalar code paths, and allows uncorrelated scalar subqueries in
ORDER BY, JOIN ON, and as arguments to aggregate functions.
Thanks to @neilconway for implementing this feature, with reviews from
@Dandandan, @alamb, and @timsaucer. Related PRs: #21240
Faster Sort-Merge Joins:
Semi, anti, and mark joins now track matches with a per-row bitset instead of
materializing (outer, inner) pairs. Batched deferred filtering makes
near-unique LEFT and FULL joins 20-50x faster. Finally, join-key comparisons
now use a DynComparator that resolves the column type once rather than per row,
making microbenchmarks up to 12% faster and TPC-H ~5% faster overall.
Thanks to @mbutrovich for this work, with reviews from @Dandandan,
@comphead, and @rluvaton. Related PRs: #20806, #21184, #21484, #21517
Faster Repartitioning:
RepartitionExec now coalesces batches before sending them to distributor
channels, cutting per-batch overhead for up to 50% faster execution on some
repartition-heavy queries.
Thanks to @gabotechs for this work, with reviews from @Dandandan and
@alamb. Related PRs: #22010
Faster Functions and Hashing:
DataFusion ships hundreds of built-in functions, so speeding them up pays off
across many workloads. This release optimizes many, including array_to_string,
array_concat, array_sort, split_part, substr, strpos, left, right,
string_agg, and approx_distinct, plus better NULL handling across many
array and datetime functions. The first_value and last_value aggregates are
also substantially faster over Utf8 and Binary columns thanks to a new
GroupsAccumulator (#21090). DataFusion 54 also swaps ahash for foldhash in
datafusion-common, and optimizes regexp_replace by stripping trailing .*
from anchored patterns.
Thanks to the many contributors who drove this work, especially @UBarney,
@neilconway, @Dandandan, @zhangxffff, @lyne7-sc, @CuteChuanChuan,
@kumarUjjawal, and @coderfender.
Planner Improvements¶
Pruning Functionally Redundant Sort Keys:
Sorting is expensive, so it pays to sort by as few columns as possible.
DataFusion 54 now drops functionally redundant ORDER BY keys: when an earlier
key determines a later one, the later key can't change the ordering, so removing
it cuts sorting cost without affecting results.
Thanks to @xiedeyantu for implementing this feature, with reviews from
@alamb and @neilconway. Related PRs: #21362
Skip Redundant Parquet Filters: When statistics prove a filter matches every row in a Parquet row group, DataFusion now skips evaluating it — both row filters and page-level pruning — for that row group instead of re-checking each row. Thanks to @xudong963 for implementing this, building on a suggestion from @crepererum. Related issues and PRs: #19028, #21637
Statistics-Driven Sort Pushdown and TopK:
Files and Parquet row groups are now ordered using statistics, which can avoid
sorting entirely and improve dynamic filtering and early stopping for TopK
(ORDER BY ... LIMIT) queries. The most promising data is read first, often
satisfying the LIMIT before scanning the rest.
Thanks to @zhuqi-lucas for driving this work, with reviews from @adriangb.
Related PRs: #21182, #21426, #21956
Improved Statistics and Cardinality Estimation: Good plans depend on good statistics. This release extracts NDV (number of distinct values) statistics from Parquet metadata, uses NDV for equality-filter selectivity, adds a pluggable StatisticsRegistry for operator-level statistics propagation, and improves cardinality estimation for semi and anti joins. Thanks to @asolimando, @jonathanc-n, and @buraksenn for driving this work. Related PRs: #19957, #20789, #21077, #21081, #21483, #20904
Scan Improvements¶
Morsel-Driven Parquet Scans: Parquet scan parallelism was previously bounded by the slowest scan thread, so data skew (large row groups, less-selective filters, or variable object store latency) left cores underutilized. DataFusion 54 reworks the Parquet scan around a morsel-driven design, where idle threads dynamically pull small units of work ("morsels") instead of each being assigned a fixed partition up front. This spreads work more evenly and can be up to ~2x faster for skewed scans such as ClickBench. Thanks to @Dandandan, @alamb, @adriangb, @xudong963, and @zhuqi-lucas for collaborating on this substantial effort. Related issues and PRs: #20529, #21327, #21342, #21351
Struct Field Filter Pushdown and Leaf-Level Projection:
Filters on struct fields (e.g. WHERE s['foo'] > 67) are now pushed down into the
Parquet decoder rather than evaluated after a full scan, and both filtering and
projection read only the struct leaves they actually access,
significantly improving performance for nested and Variant data in large
Parquet files.
Thanks to @friendlymatthew for this work, with reviews from @adriangb,
@cetra3, and @AdamGS. Related PRs: #20822, #20854, #20925
New Features ✨¶
LATERAL Joins¶
Lateral joins have been long requested (#10048). DataFusion 54 adds basic
support for CROSS JOIN LATERAL, INNER JOIN LATERAL, and LEFT JOIN LATERAL
(#21202, #21352). A lateral subquery in the FROM clause can reference
columns from preceding tables — handy for expanding a per-row series or
correlating against a set-returning function. It uses decorrelation, so the
subquery is evaluated once rather than re-executed per outer row.
-- For each row in t1, expand a series 1..t1_int and join the values back
SELECT t1_id, t1_name, i
FROM join_t1 t1
CROSS JOIN LATERAL (
SELECT * FROM unnest(generate_series(1, t1_int))
) AS series(i);
Thanks to @neilconway for implementing this feature, with reviews from @Dandandan, @alamb, and @crm26.
Lambda Functions¶
DataFusion now supports lambda expressions (x -> expr) with column capture,
plus new higher-order array UDFs like array_transform, array_filter, and
array_any_match (#21323, #21679). Lambdas express per-element computation
directly in SQL:
-- Apply `x * 10` to every element
SELECT array_transform([1, 2, 3, 4, 5], x -> x * 10);
-- [10, 20, 30, 40, 50]
-- Keep only elements where `x > 2`
SELECT array_filter([1, 2, 3, 4, 5], x -> x > 2);
-- [3, 4, 5]
-- True if any element satisfies `x > 2`
SELECT array_any_match([1, 2, 3], x -> x > 2);
-- true
Lambdas compose, so you can filter then transform in one expression:
-- Keep elements > 2, then multiply each survivor by 10
SELECT array_transform(array_filter([1, 2, 3, 4, 5], x -> x > 2), x -> x * 10);
-- [30, 40, 50]
Thanks to @gstvg and @rluvaton for leading this effort (first prototyped in #18921), @ologlogn and @LiaCastaneda for the array_filter and array_any_match functions, and @benbellick, @comphead, @martin-g, @pepijnve, and @shehabgamin for reviews.
Spilling Nested Loop Joins¶
NestedLoopJoinExec previously failed with an out-of-memory error when the build
side exceeded the memory budget. DataFusion 54 adds a memory-limited path that
transparently spills to disk and completes the query instead (#21448), with
zero overhead when memory is sufficient. It currently covers INNER, LEFT,
LEFT SEMI, LEFT ANTI, and LEFT MARK joins. Thanks to @viirya for
implementing this feature, with reviews from @2010YOUY01.
New Avro Reader¶
The Avro reader now uses the arrow-avro crate (#17861), replacing internal
conversion code with a faster, better-maintained implementation shared with the
Arrow ecosystem (see Introducing arrow-avro). Thanks to @getChan for this
work, with reviews from @adriangb, @alamb, and @jecsand838.
Extension Type Registry¶
Arrow extension types let users layer their own semantics on top of a physical storage type. DataFusion 54 adds a registry for registering their behavior (#18223, #20312), several more canonical extension types (#21291), and the ability to cast to an extension type in logical expressions (#18136). Thanks to @tschwarzinger and @paleolimbot for driving this work, with reviews from @adriangb and @cetra3.
Content-Defined Chunking for Parquet¶
DataFusion's Parquet writer can now use content-defined chunking (CDC) (#21110), which aligns data page boundaries with the data rather than fixed row counts. This improves deduplication and incremental storage, since inserting or editing a few rows no longer shifts every later page boundary. For background, see Parquet Content-Defined Chunking and Improving Parquet Dedupe on Hugging Face Hub. Thanks to @kszucs for this feature, with reviews from @alamb.
New Functions¶
SQL and Scalar Functions:
DataFusion 54 adds new scalar functions including array_compact,
cosine_distance, inner_product, array_normalize, cast_to_type, and
with_metadata, plus nanosecond date_part support (#20674) and the : JSON
access operator (#20628). The cosine_distance, inner_product, and
array_normalize additions round out DataFusion's vector-search building blocks. Thanks to @comphead, @crm26,
@adriangb, @mhilton, and @Samyak2 for these contributions.
Spark-Compatible Functions: The datafusion-spark crate gains many new or improved Spark-compatible functions, including round, floor, ceil, soundex, xxhash64, array_contains, array_compact, int/float-to-timestamp casts, and UTF-8 validation functions. Thanks to the contributors who drove this work, especially @comphead, @coderfender, @SubhamSinghal, @kazantsev-maksim, @andygrove, @buraksenn, @davidlghellin, @athlcode, and @shivbhatia10.
Upgrade Guide and Changelog 📖¶
Upgrading to 54.0.0 should be straightforward for most users, though there are some breaking changes. See the Upgrade Guide for details and migration snippets, and the changelog for the full list of changes.
About DataFusion¶
Apache DataFusion is an extensible query engine, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion is used by developers to create new, fast, data-centric systems such as databases, dataframe libraries, and machine learning and streaming applications. While DataFusion's primary design goal is to accelerate the creation of other data-centric systems, it provides a reasonable experience directly out of the box as a dataframe library, Python library, and command-line SQL tool.
DataFusion's core thesis is that, as a community, together we can build much more advanced technology than any of us as individuals or companies could build alone. Without DataFusion, highly performant vectorized query engines would remain the domain of a few large companies and world-class research institutions. With DataFusion, we can all build on top of a shared foundation and focus on what makes our projects unique.
How to Get Involved¶
DataFusion is not a project built or driven by a single person, company, or foundation. Rather, our community of users and contributors works together to build a shared technology that none of us could have built alone.
If you are interested in joining us, we would love to have you. You can try out DataFusion on some of your own data and projects and let us know how it goes, contribute suggestions, documentation, bug reports, or a PR with documentation, tests, or code. A list of open issues suitable for beginners is here, and you can find out how to reach us on the communication doc.