Apache DataFusion 49.0.0 Released
Posted on: Mon 28 July 2025 by pmc
Introduction¶
We are proud to announce the release of DataFusion 49.0.0. This blog post highlights some of the major improvements since the release of DataFusion 48.0.0. The complete list of changes is available in the changelog.
Performance Improvements 🚀¶
DataFusion continues to focus on enhancing performance, as shown in the ClickBench and other results.
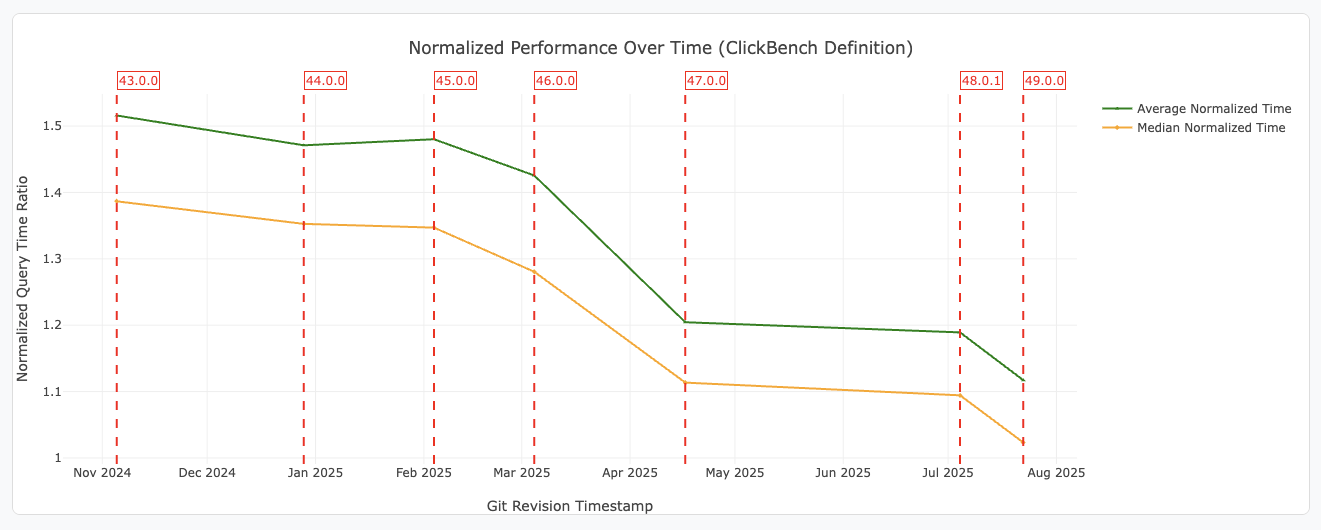
Figure 1: ClickBench performance improvements over time Average and median normalized query execution times for ClickBench queries for each git revision. Query times are normalized using the ClickBench definition. Data and definitions on the DataFusion Benchmarking Page.
Here are some noteworthy optimizations added since DataFusion 48:
Equivalence system upgrade: The lower levels of the equivalence system, which is used to implement the optimizations described in Using Ordering for Better Plans, were rewritten, leading to much faster planning times, especially for queries with a large number of columns. This change also prepares the way for more sophisticated sort-based optimizations in the future. (PR #16217 by ozankabak).
Dynamic Filters and TopK pushdown
DataFusion now supports dynamic filters, which are improved during query execution,
and physical filter pushdown. Together, these features improve the performance of
queries that use LIMIT and ORDER BY clauses, such as the following:
SELECT *
FROM data
ORDER BY timestamp DESC
LIMIT 10
While the query above is simple, without dynamic filtering or knowing that the data
is already sorted by timestamp, a query engine must decode all of the data to
find the top 10 values. With the dynamic filters system, DataFusion applies an
increasingly selective filter during query execution. It checks the current
top 10 values of the timestamp column before opening files or reading
Parquet Row Groups and Data Pages, which can skip older data very quickly.
Dynamic predicates are a common feature of advanced engines such as Dynamic Filters in Starburst and Top-K Aggregation Optimization at Snowflake. The technique drastically improves query performance (we've seen over a 1.5x improvement for some TPC-H-style queries), especially in combination with late materialization and columnar file formats such as Parquet. We plan to write a blog post explaining the details of this optimization in the future, and we expect to use the same mechanism to implement additional optimizations such as Sideways Information Passing for joins (Issue #15037 PR #15770 by adriangb).
Community Growth 📈¶
The last few months, between 46.0.0 and 49.0.0, have seen our community grow:
- New PMC members and committers: berkay, xudong963 and timsaucer joined the PMC. blaginin, milenkovicm, adriangb and kosiew joined as committers. See the mailing list for more details.
- In the core DataFusion repo alone, we reviewed and accepted over 850 PRs from 172 different committers, created over 669 issues, and closed 379 of them 🚀. All changes are listed in the detailed changelogs.
- DataFusion published a number of blog posts, including User defined Window Functions, Optimizing SQL (and DataFrames) in DataFusion part 1, part 2, Using Rust async for Query Execution and Cancelling Long-Running Queries, and Embedding User-Defined Indexes in Apache Parquet Files.
New Features ✨¶
Async User-Defined Functions¶
It is now possible to write async User-Defined Functions
(UDFs) in DataFusion that perform asynchronous
operations, such as network requests or database queries, without blocking the
execution of the query. This enables new use cases, such as
integrating with large language models (LLMs) or other external services, and we can't
wait to see what the community builds with it.
See the documentation for more details and the async UDF example for working code.
You could, for example, implement a function ask_llm that asks a large language model
(LLM) service a question based on the content of two columns.
SELECT *
FROM animal a
WHERE ask_llm(a.name, 'Is this animal furry?')")
The implementation of an async UDF is almost identical to a normal
UDF, except that it must implement the AsyncScalarUDFImpl trait in addition to ScalarUDFImpl and
provide an async implementation via invoke_async_with_args:
#[derive(Debug)]
struct AskLLM {
signature: Signature,
}
#[async_trait]
impl AsyncScalarUDFImpl for AskLLM {
/// The `invoke_async_with_args` method is similar to `invoke_with_args`,
/// but it returns a `Future` that resolves to the result.
///
/// Since this signature is `async`, it can do any `async` operations, such
/// as network requests.
async fn invoke_async_with_args(
&self,
args: ScalarFunctionArgs,
options: &ConfigOptions,
) -> Result<ArrayRef> {
// Converts the arguments to arrays for simplicity.
let args = ColumnarValue::values_to_arrays(&args.args)?;
let [column_of_interest, question] = take_function_args(self.name(), args)?;
let client = Client::new();
// Make a network request to a hypothetical LLM service
let res = client
.post(URI)
.headers(get_llm_headers(options))
.json(&req)
.send()
.await?
.json::<LLMResponse>()
.await?;
let results = extract_results_from_llm_response(&res);
Ok(Arc::new(results))
}
}
(Issue #6518, PR #14837 from goldmedal 🏆)
Better Cancellation for Certain Long-Running Queries¶
In rare cases, it was previously not possible to cancel long-running queries,
leading to unresponsiveness. Other projects would likely have fixed this issue
by treating the symptom, but pepijnve and the DataFusion community worked together to
treat the root cause. The general solution required a deep understanding of the
DataFusion execution engine, Rust Streams, and the tokio cooperative
scheduling model. The resulting PR is a model of careful
community engineering and a great example of using Rust's async ecosystem
to implement complex functionality. It even resulted in a contribution upstream to tokio
(since accepted). See the blog post for more details.
Metadata for User Defined Types such as Variant and Geometry¶
User-defined types have been a long-requested feature, and this release provides the low-level APIs to support them efficiently.
- Metadata handling in PRs #15646 and #16170 from timsaucer
- Pushdown of filters and expressions (see "Dynamic Filters and TopK pushdown" section above)
We still have some work to do to fully support user-defined types, specifically in documentation and testing, and we would love your help in this area. If you are interested in contributing, please see issue #12644.
Parquet Modular Encryption¶
DataFusion now supports reading and writing encrypted Apache Parquet files with modular encryption. This allows users to encrypt specific columns in a Parquet file using different keys, while still being able to read data without needing to decrypt the entire file.
Here is an example of how to configure DataFusion to read an encrypted Parquet
table with two columns, double_field and float_field, using modular
encryption:
CREATE EXTERNAL TABLE encrypted_parquet_table
(
double_field double,
float_field float
)
STORED AS PARQUET LOCATION 'pq/' OPTIONS (
-- encryption
'format.crypto.file_encryption.encrypt_footer' 'true',
'format.crypto.file_encryption.footer_key_as_hex' '30313233343536373839303132333435', -- b"0123456789012345"
'format.crypto.file_encryption.column_key_as_hex::double_field' '31323334353637383930313233343530', -- b"1234567890123450"
'format.crypto.file_encryption.column_key_as_hex::float_field' '31323334353637383930313233343531', -- b"1234567890123451"
-- decryption
'format.crypto.file_decryption.footer_key_as_hex' '30313233343536373839303132333435', -- b"0123456789012345"
'format.crypto.file_decryption.column_key_as_hex::double_field' '31323334353637383930313233343530', -- b"1234567890123450"
'format.crypto.file_decryption.column_key_as_hex::float_field' '31323334353637383930313233343531', -- b"1234567890123451"
);
(Issue #15216, PR #16351 from corwinjoy and adamreeve)
Support for WITHIN GROUP for Ordered-Set Aggregate Functions¶
DataFusion now supports the WITHIN GROUP clause for ordered-set aggregate
functions such as approx_percentile_cont, percentile_cont, and
percentile_disc, which allows users to specify the precise order.
For example, the following query computes the 50th percentile for the temperature column
in the city_data table, ordered by date:
SELECT
percentile_disc(0.5) WITHIN GROUP (ORDER BY date) AS median_temperature
FROM city_data;
(Issue #11732, PR #13511, by Garamda)
Compressed Spill Files¶
DataFusion now supports compressing the files written to disk when spilling larger-than-memory datasets while sorting and grouping. Using compression can significantly reduce the size of the intermediate files and improve performance when reading them back into memory.
(Issue #16130, PR #16268 by ding-young)
Support for REGEX_INSTR function¶
DataFusion now supports the [REGEXP_INSTR function], which returns the position of a
regular expression match within a string.
For example, to find the position of the first match of the regular expression
C(.)(..) in the string ABCDEF, you can use:
> SELECT regexp_instr('ABCDEF', 'C(.)(..)');
+---------------------------------------------------------------+
| regexp_instr(Utf8("ABCDEF"),Utf8("C(.)(..)")) |
+---------------------------------------------------------------+
| 3 |
+---------------------------------------------------------------+
(Issue #13009, PR #15928 by nirnayroy)
Upgrade Guide and Changelog¶
Upgrading to 49.0.0 should be straightforward for most users. Please review the Upgrade Guide for details on breaking changes and code snippets to help with the transition. Recently, some users have reported success automatically upgrading DataFusion by pairing AI tools with the upgrade guide. For a comprehensive list of all changes, please refer to the changelog.
About DataFusion¶
Apache DataFusion is an extensible query engine, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion is used by developers to create new, fast, data-centric systems such as databases, dataframe libraries, and machine learning and streaming applications. While DataFusion’s primary design goal is to accelerate the creation of other data-centric systems, it provides a reasonable experience directly out of the box as a dataframe library, python library, and [command-line SQL tool].
DataFusion's core thesis is that as a community, together we can build much more advanced technology than any of us as individuals or companies could do alone. Without DataFusion, highly performant vectorized query engines would remain the domain of a few large companies and world-class research institutions. With DataFusion, we can all build on top of a shared foundation and focus on what makes our projects unique.
How to Get Involved¶
DataFusion is not a project built or driven by a single person, company, or foundation. Rather, our community of users and contributors works together to build a shared technology that none of us could have built alone.
If you are interested in joining us, we would love to have you. You can try out DataFusion on some of your own data and projects and let us know how it goes, contribute suggestions, documentation, bug reports, or a PR with documentation, tests, or code. A list of open issues suitable for beginners is here, and you can find out how to reach us on the communication doc.
Comments
We use Giscus for comments, powered by GitHub Discussions. To respect your privacy, Giscus and comments will load only if you click "Show Comments"