Apache DataFusion 50.0.0 Released
Posted on: Mon 29 September 2025 by pmc
Introduction¶
We are proud to announce the release of DataFusion 50.0.0. This blog post highlights some of the major improvements since the release of DataFusion 49.0.0. The complete list of changes is available in the changelog. Thanks to numerous contributors for making this release possible!
Performance Improvements 🚀¶
DataFusion continues to focus on enhancing performance, as shown in ClickBench and other benchmark results.
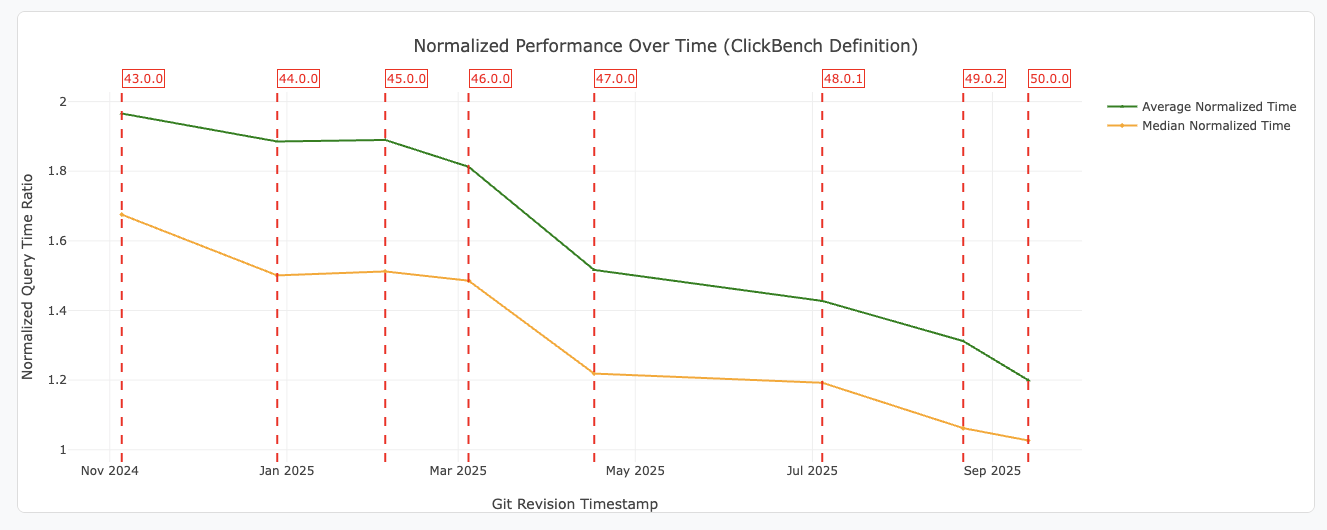
Figure 1: Average and median normalized query execution times for ClickBench queries for each git revision. Query times are normalized using the ClickBench definition. See the DataFusion Benchmarking Page for more details.
Here are some noteworthy optimizations added since DataFusion 49:
Dynamic Filter Pushdown Improvements
The dynamic filter pushdown optimization, which allows runtime filters to cut down on the amount of data read, has been extended to support inner hash joins, dramatically improving performance when one relation is relatively small or filtered by a highly selective predicate. More details can be found in the Dynamic Filter Pushdown for Hash Joins section below. The dynamic filters in the TopK operator have also been improved in DataFusion 50.0.0, further increasing the effectiveness and efficiency of the optimization. More details can be found in this ticket.
Nested Loop Join Optimization
The nested loop join operator has been rewritten to reduce execution time and memory
usage by adopting a finer-grained approach. Specifically, we now limit the
intermediate data size to around a single RecordBatch for better memory
efficiency, and we have eliminated redundant conversions from the old
implementation to further improve execution speed.
When evaluating this new approach in a microbenchmark, we measured up to a 5x
improvement in execution time and a 99% reduction in memory usage. More details and
results can be found in this
ticket.
Parquet Metadata Caching
DataFusion now automatically caches the metadata of Parquet files (statistics, page indexes, etc.), to avoid unnecessary disk/network round-trips. This is especially useful when querying the same table multiple times over relatively slow networks, allowing us to achieve an order of magnitude faster execution time when running many small reads over large files. More information can be found in the Parquet Metadata Cache section.
Community Growth 📈¶
Between 49.0.0 and 50.0.0, we continue to see our community grow:
- Qi Zhu (zhuqi-lucas) and Yoav Cohen (yoavcloud) became committers. See the mailing list for more details.
- In the core DataFusion repo alone, we reviewed and accepted 318 PRs from 79 different committers, created over 235 issues, and closed 197 of them 🚀. All changes are listed in the detailed changelogs.
- DataFusion published several blogs, including Using External Indexes, Metadata Stores, Catalogs and Caches to Accelerate Queries on Apache Parquet, Dynamic Filters: Passing Information Between Operators During Execution for 25x Faster Queries, and Implementing User Defined Types and Custom Metadata in DataFusion.
New Features ✨¶
Improved Spilling Sorts for Larger-than-Memory Datasets¶
DataFusion has long been able to sort datasets that do not fit entirely in memory, but still struggled with particularly large inputs or highly memory-constrained setups. Larger-than-memory sorts in DataFusion 50.0.0 have been improved with the recent introduction of multi-level merge sorts (more details in the respective ticket). It is now possible to execute almost any sorting query that would have previously triggered out-of-memory errors, by relying on disk spilling. Thanks to Raz Luvaton, Yongting You, and ding-young for delivering this feature.
Dynamic Filter Pushdown for Hash Joins¶
The dynamic filter pushdown optimization has been extended to inner hash joins, dramatically reducing the amount of scanned data in some workloads—a technique sometimes referred to as Sideways Information Passing.
These filters are automatically applied to inner hash joins, while future work will introduce them to other join types.
For example, given a query that looks for a specific customer and
their orders, DataFusion can now filter the orders relation based on the
c_custkey of the target customer, reducing the amount of data
read from disk by orders of magnitude.
-- retrieve the orders of the customer with c_phone = '25-989-741-2988'
SELECT *
FROM customer
JOIN orders ON c_custkey = o_custkey
WHERE c_phone = '25-989-741-2988';
The following shows an execution plan in DataFusion 50.0.0 with this optimization:
HashJoinExec
DataSourceExec: <-- read customer
predicate=c_phone@4 = 25-989-741-2988
metrics=[output_rows=1, ...]
DataSourceExec: <-- read orders
-- dynamic filter is added here, filtering directly at scan time
predicate=DynamicFilterPhysicalExpr [ o_custkey@1 >= 1 AND o_custkey@1 <= 1 ]
-- the number of output rows is kept to a minimum
metrics=[output_rows=11, ...]
Because there is a single customer in this query,
almost all rows from orders are filtered out by the join.
In previous versions of DataFusion, the entire orders relation would be
scanned to join with the target customer, but now the dynamic filter pushdown can
filter it right at the source, minimizing the amount of data decoded.
More information can be found in the respective
ticket and the next step will be to
extend the dynamic filters to other types of joins, such as LEFT and
RIGHT outer joins. Thanks to Adrian Garcia Badaracco, Qi Zhu, xudong963, Daniël Heres, and Lía Adriana
for delivering this feature.
Parquet Metadata Cache¶
The metadata of Parquet files (statistics, page indexes, etc.) is now
automatically cached when using the built-in ListingTable, which reduces disk/network round-trips and repeated decoding
of the same information. With a simple microbenchmark that executes point reads
(e.g., SELECT v FROM t WHERE k = x) over large files, we measured a 12x
improvement in execution time (more details can be found in the respective
ticket). This optimization
is production ready and enabled by default (more details in the
Epic).
Thanks to Nuno Faria, Jonathan Chen, Shehab Amin, Oleks V, Tim Saucer, and Blake Orth for delivering this feature.
Here is an example of the metadata cache in action:
-- disabling the metadata cache
> SET datafusion.runtime.metadata_cache_limit = '0M';
-- simple query (t.parquet: 100M rows, 3 cols)
> EXPLAIN ANALYZE SELECT * FROM 't.parquet' LIMIT 1;
DataSourceExec: ... metrics=[..., metadata_load_time=229.196422ms, ...]
Elapsed 0.246 seconds.
-- enabling the metadata cache
> SET datafusion.runtime.metadata_cache_limit = '50M';
> EXPLAIN ANALYZE SELECT * FROM 't.parquet' LIMIT 1;
DataSourceExec: ... metrics=[..., metadata_load_time=228.612µs, ...]
Elapsed 0.003 seconds. -- 82x improvement in this specific query
The cache can be configured with the following runtime parameter:
datafusion.runtime.metadata_cache_limit
The default FileMetadataCache uses a
least-recently-used eviction algorithm and up to 50MB of memory.
If the underlying file changes, the cache is automatically invalidated.
Setting the limit to 0 will disable any metadata caching. As with most APIs in
DataFusion, users can provide their own behavior using a custom
FileMetadataCache
implementation when setting up the RuntimeEnv.
For users with custom TableProvider:
-
If the custom provider uses the
ParquetFormat, caching will work without any changes. -
Otherwise the
CachedParquetFileReaderFactorycan be provided when creating aParquetSource.
Users can inspect the cache contents through the
FileMetadataCache::list_entries
method, or with the
metadata_cache()
function in datafusion-cli:
> SELECT * FROM metadata_cache();
+---------------+-------------------------+-----------------+--------------------------+---------+---------------------+------+-----------------+
| path | file_modified | file_size_bytes | e_tag | version | metadata_size_bytes | hits | extra |
+---------------+-------------------------+-----------------+--------------------------+---------+---------------------+------+-----------------+
| .../t.parquet | 2025-09-21T17:40:13.650 | 420827020 | 0-63f5331fb4458-19154f8c | NULL | 44480534 | 27 | page_index=true |
+---------------+-------------------------+-----------------+--------------------------+---------+---------------------+------+-----------------+
1 row(s) fetched.
Elapsed 0.003 seconds.
QUALIFY Clause¶
DataFusion now supports the QUALIFY SQL clause
(#16933), which simplifies
filtering window function output (similar to how HAVING filters
aggregation output).
For example, filtering the output of the rank() function previously
required a query like this:
SELECT a, b, c
FROM (
SELECT a, b, c, rank() OVER(PARTITION BY a ORDER BY b) as rk
FROM t
)
WHERE rk = 1
The same query can now be written like this:
SELECT a, b, c, rank() OVER(PARTITION BY a ORDER BY b) as rk
FROM t
QUALIFY rk = 1
Although it is not part of the SQL standard (yet), it has been gaining adoption in several SQL analytical systems such as DuckDB, Snowflake, and BigQuery. Thanks to Huaijin and Jonah Gao for delivering this feature.
FILTER Support for Window Functions¶
Continuing the theme, the FILTER clause has been extended to support
aggregate window functions.
It allows these functions to apply to specific rows without having to
rely on CASE expressions, similar to what was already possible with regular
aggregate functions.
For example, we can gather multiple distinct sets of values matching different criteria with a single pass over the input:
SELECT
ARRAY_AGG(c2) FILTER (WHERE c2 >= 2) OVER (...) -- e.g. [2, 3, 4]
ARRAY_AGG(CASE WHEN c2 >= 2 THEN c2 END) OVER (...) -- e.g. [NULL, NULL, 2, 3, 4]
...
FROM table
Thanks to Geoffrey Claude and Jeffrey Vo for delivering this feature.
ConfigOptions Now Available to Functions¶
DataFusion 50.0.0 now passes session configuration parameters to User-Defined Functions (UDFs) via ScalarFunctionArgs (#16970). This allows behavior that varies based on runtime state; for example, time UDFs can use the session-specified time zone instead of just UTC.
Thanks to Bruce Ritchie, Piotr Findeisen, Oleks V, and Andrew Lamb for delivering this feature.
Additional Apache Spark Compatible Functions¶
Finally, due to Apache Spark's impact on analytical processing, many DataFusion users desire Spark compatibility in their workloads, so DataFusion provides a set of Spark-compatible functions in the datafusion-spark crate. You can read more about this project in the announcement and epic. DataFusion 50.0.0 adds several new such functions:
arraybit_get/bit_countbitmap_countcrc32/sha1date_add/date_subiflast_daylike/ilikeluhn_checkmod/pmodnext_dayparse_urlrintwidth_bucket
Thanks to David López, Chen Chongchen, Alan Tang, Peter Nguyen, and Evgenii Glotov for delivering these functions. We are looking for additional help reviewing and implementing more functions; please reach out on the epic if you are interested.
Known Issues / Patchset¶
As DataFusion continues to mature, we regularly release patch versions to fix issues
in major releases. Since the release of 50.0.0, we have identified a few
issues, and expect to release 50.1.0 to address them. You can track progress
in this ticket.
Upgrade Guide and Changelog¶
Upgrading to 50.0.0 should be straightforward for most users. Please review the Upgrade Guide for details on breaking changes and code snippets to help with the transition. Recently, some users have reported success automatically upgrading DataFusion by pairing AI tools with the upgrade guide. For a comprehensive list of all changes, please refer to the changelog.
About DataFusion¶
Apache DataFusion is an extensible query engine, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion is used by developers to create new, fast, data-centric systems such as databases, dataframe libraries, and machine learning and streaming applications. While DataFusion’s primary design goal is to accelerate the creation of other data-centric systems, it provides a reasonable experience directly out of the box as a dataframe library, Python library, and command-line SQL tool.
DataFusion's core thesis is that, as a community, together we can build much more advanced technology than any of us as individuals or companies could build alone. Without DataFusion, highly performant vectorized query engines would remain the domain of a few large companies and world-class research institutions. With DataFusion, we can all build on top of a shared foundation and focus on what makes our projects unique.
How to Get Involved¶
DataFusion is not a project built or driven by a single person, company, or foundation. Rather, our community of users and contributors works together to build a shared technology that none of us could have built alone.
If you are interested in joining us, we would love to have you. You can try out DataFusion on some of your own data and projects and let us know how it goes, contribute suggestions, documentation, bug reports, or a PR with documentation, tests, or code. A list of open issues suitable for beginners is here, and you can find out how to reach us on the communication doc.
Comments
We use Giscus for comments, powered by GitHub Discussions. To respect your privacy, Giscus and comments will load only if you click "Show Comments"