Apache DataFusion 51.0.0 Released
Posted on: Tue 25 November 2025 by pmc
Introduction¶
We are proud to announce the release of DataFusion 51.0.0. This post highlights some of the major improvements since DataFusion 50.0.0. The complete list of changes is available in the changelog. Thanks to the 128 contributors for making this release possible.
Performance Improvements 🚀¶
We continue to make significant performance improvements in DataFusion, both in the core engine and in the Parquet reader.
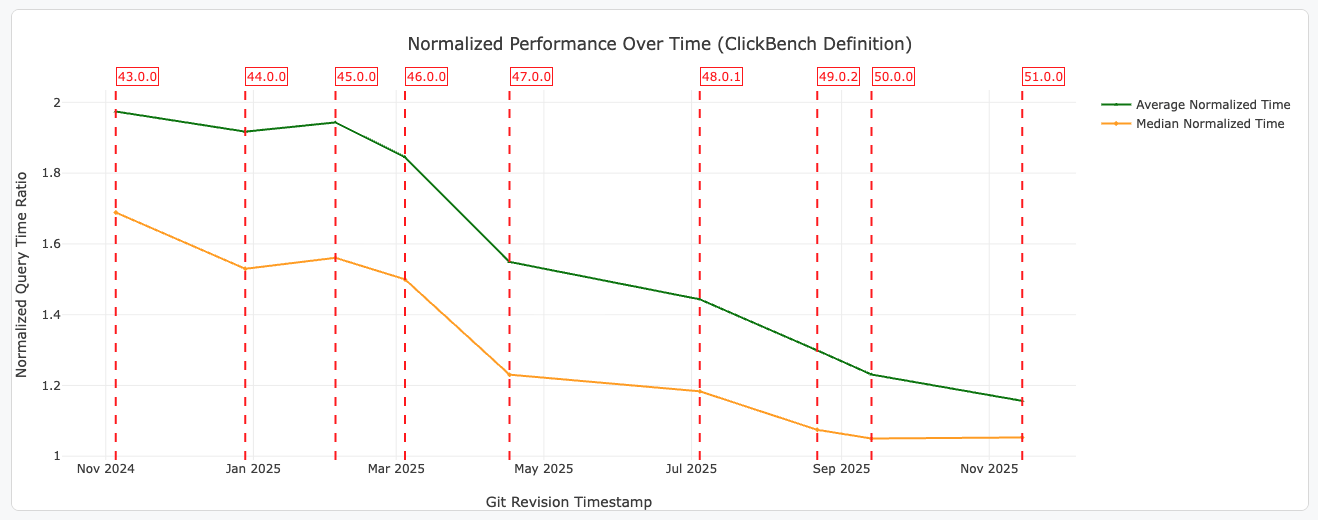
Figure 1: Average and median normalized query execution times for ClickBench queries for DataFusion 51.0.0 compared to previous releases. Query times are normalized using the ClickBench definition. See the DataFusion Benchmarking Page for more details.
Faster CASE expression evaluation¶
This release builds on the CASE performance epic with significant improvements. Expressions short‑circuit earlier, reuse partial results, and avoid unnecessary scattering, speeding up common ETL patterns. Thanks to pepijnve, chenkovsky, and petern48 for leading this effort. We hope to share more details on our implementation in a future post.
Better Defaults for Remote Parquet Reads¶
By default, DataFusion now always fetches the last 512KB (configurable) of Apache Parquet files
which usually includes the footer and metadata (#18118). This
change typically avoids 2 I/O requests for each Parquet. While this
setting has existed in DataFusion for many years, it was not previously enabled
by default. Users can tune the number of bytes fetched in the initial I/O
request via the datafusion.execution.parquet.metadata_size_hint config setting. Thanks to
zhuqi-lucas for leading this effort.
Faster Parquet metadata parsing¶
DataFusion 51 also includes the latest Parquet reader from Arrow Rust 57.0.0, which parses Parquet metadata significantly faster. This is especially beneficial for workloads with many small Parquet files and scenarios where startup time or low latency is important. You can read more about the upstream work by etseidl and jhorstmann that enabled these improvements in the Faster Apache Parquet Footer Metadata Using a Custom Thrift Parser blog.
![]()
Figure 2: Metadata parsing performance improvements in Arrow/Parquet 57.0.0.
New Features ✨¶
Decimal32/Decimal64 support¶
The new Arrow types Decimal32 and Decimal64 are now supported in DataFusion
(#17501), including aggregations such as SUM, AVG, MIN/MAX, and window
functions. Thanks to AdamGS for leading this effort.
SQL Pipe Operators¶
DataFusion now supports the SQL pipe operator syntax (#17278), enabling inline transforms such as:
SELECT * FROM t
|> WHERE a > 10
|> ORDER BY b
|> LIMIT 5;
This syntax, popularized by Google BigQuery, keeps multi-step transformations concise while preserving regular SQL semantics. Thanks to simonvandel for leading this effort.
I/O Profiling in datafusion-cli¶
datafusion-cli now has built-in instrumentation to trace object store calls
(#17207). Toggle profiling
with the \object_store_profiling command and inspect the exact GET/LIST requests issued during
query execution:
DataFusion CLI v51.0.0
> \object_store_profiling trace
ObjectStore Profile mode set to Trace
> select count(*) from 'https://datasets.clickhouse.com/hits_compatible/athena_partitioned/hits_1.parquet';
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row(s) fetched.
Elapsed 0.367 seconds.
Object Store Profiling
Instrumented Object Store: instrument_mode: Trace, inner: HttpStore
2025-11-19T21:10:43.476121+00:00 operation=Head duration=0.069763s path=hits_compatible/athena_partitioned/hits_1.parquet
2025-11-19T21:10:43.545903+00:00 operation=Head duration=0.025859s path=hits_compatible/athena_partitioned/hits_1.parquet
2025-11-19T21:10:43.571768+00:00 operation=Head duration=0.025684s path=hits_compatible/athena_partitioned/hits_1.parquet
2025-11-19T21:10:43.597463+00:00 operation=Get duration=0.034194s size=524288 range: bytes=174440756-174965043 path=hits_compatible/athena_partitioned/hits_1.parquet
2025-11-19T21:10:43.705821+00:00 operation=Head duration=0.022029s path=hits_compatible/athena_partitioned/hits_1.parquet
Summaries:
+-----------+----------+-----------+-----------+-----------+-----------+-------+
| Operation | Metric | min | max | avg | sum | count |
+-----------+----------+-----------+-----------+-----------+-----------+-------+
| Get | duration | 0.034194s | 0.034194s | 0.034194s | 0.034194s | 1 |
| Get | size | 524288 B | 524288 B | 524288 B | 524288 B | 1 |
| Head | duration | 0.022029s | 0.069763s | 0.035834s | 0.143335s | 4 |
| Head | size | | | | | 4 |
+-----------+----------+-----------+-----------+-----------+-----------+-------+
This makes it far easier to diagnose slow remote scans and validate caching strategies. Thanks to BlakeOrth for leading this effort.
DESCRIBE <query>¶
DESCRIBE now works on arbitrary queries, returning the schema instead
of being an alias for EXPLAIN (#18234). This brings DataFusion in line with engines
like DuckDB and makes it easy to inspect the output schema of queries
without executing them. Thanks to djanderson for leading this effort.
For example:
DataFusion CLI v51.0.0
> create table t(a int, b varchar, c float) as values (1, 'a', 2.0);
0 row(s) fetched.
Elapsed 0.002 seconds.
> DESCRIBE SELECT a, b, SUM(c) FROM t GROUP BY a, b;
+-------------+-----------+-------------+
| column_name | data_type | is_nullable |
+-------------+-----------+-------------+
| a | Int32 | YES |
| b | Utf8View | YES |
| sum(t.c) | Float64 | YES |
+-------------+-----------+-------------+
3 row(s) fetched.
Named arguments in SQL functions¶
DataFusion now understands PostgreSQL-style named arguments (param => value)
for scalar, aggregate, and window functions (#17379). You can mix positional and named
arguments in any order, and error messages now list parameter names to make
diagnostics clearer. UDF authors can also expose parameter names so their
functions benefit from the same syntax. Thanks to timsaucer and bubulalabu for leading this effort.
For example, you can pass arguments to functions like this:
SELECT power(exponent => 3.0, base => 2.0);
Metrics improvements¶
The output of EXPLAIN ANALYZE has been improved to include more metrics about execution time and memory usage of each operator (#18217). You can learn more about these new metrics in the metrics user guide. Thanks to 2010YOUY01 for leading this effort.
The 51.0.0 release adds:
- Configuration: adds a new option
datafusion.explain.analyze_level, which can be set tosummaryfor a concise output ordevfor the full set of metrics (the previous default). - For all major operators: adds
output_bytes, reporting how many bytes of data each operator produces. - FilterExec: adds a
selectivitymetric (output_rows / input_rows) to show how effective the filter is. - AggregateExec:
- adds detailed timing metrics for group-ID computation, aggregate argument evaluation, aggregation work, and emitting final results.
- adds a
reduction_factormetric (output_rows / input_rows) to show how much grouping reduces the data. - NestedLoopJoinExec: adds a
selectivitymetric (output_rows / (left_rows * right_rows)) to show how many combinations actually pass the join condition. - Several display formatting improvements were added to make
EXPLAIN ANALYZEoutput easier to read.
For example, the following query:
set datafusion.explain.analyze_level = summary
explain analyze
select count(*)
from 'https://datasets.clickhouse.com/hits_compatible/athena_partitioned/hits_1.parquet'
where "URL" <> '';
Now shows easier-to-understand metrics such as:
metrics=[
output_rows=1000000,
elapsed_compute=16ns,
output_bytes=222.5 MB,
files_ranges_pruned_statistics=16 total → 16 matched,
row_groups_pruned_statistics=3 total → 3 matched,
row_groups_pruned_bloom_filter=3 total → 3 matched,
page_index_rows_pruned=0 total → 0 matched,
bytes_scanned=33661364,
metadata_load_time=4.243098ms,
]
Upgrade Guide and Changelog¶
Upgrading to 51.0.0 should be straightforward for most users. Please review the Upgrade Guide for details on breaking changes and code snippets to help with the transition. For a comprehensive list of all changes, please refer to the changelog.
About DataFusion¶
Apache DataFusion is an extensible query engine, written in Rust, that uses Apache Arrow as its in-memory format. DataFusion is used by developers to create new, fast, data-centric systems such as databases, dataframe libraries, and machine learning and streaming applications. While DataFusion’s primary design goal is to accelerate the creation of other data-centric systems, it provides a reasonable experience directly out of the box as a dataframe library, Python library, and command-line SQL tool.
DataFusion's core thesis is that, as a community, together we can build much more advanced technology than any of us as individuals or companies could build alone. Without DataFusion, highly performant vectorized query engines would remain the domain of a few large companies and world-class research institutions. With DataFusion, we can all build on top of a shared foundation and focus on what makes our projects unique.
How to Get Involved¶
DataFusion is not a project built or driven by a single person, company, or foundation. Rather, our community of users and contributors works together to build a shared technology that none of us could have built alone.
If you are interested in joining us, we would love to have you. You can try out DataFusion on some of your own data and projects and let us know how it goes, contribute suggestions, documentation, bug reports, or a PR with documentation, tests, or code. A list of open issues suitable for beginners is here, and you can find out how to reach us on the communication doc.
Comments
We use Giscus for comments, powered by GitHub Discussions. To respect your privacy, Giscus and comments will load only if you click "Show Comments"