Optimizing for Almost Sorted Data: Sort Pushdown in Apache DataFusion
Qi Zhu (Massive); Andrew Lamb (InfluxData)
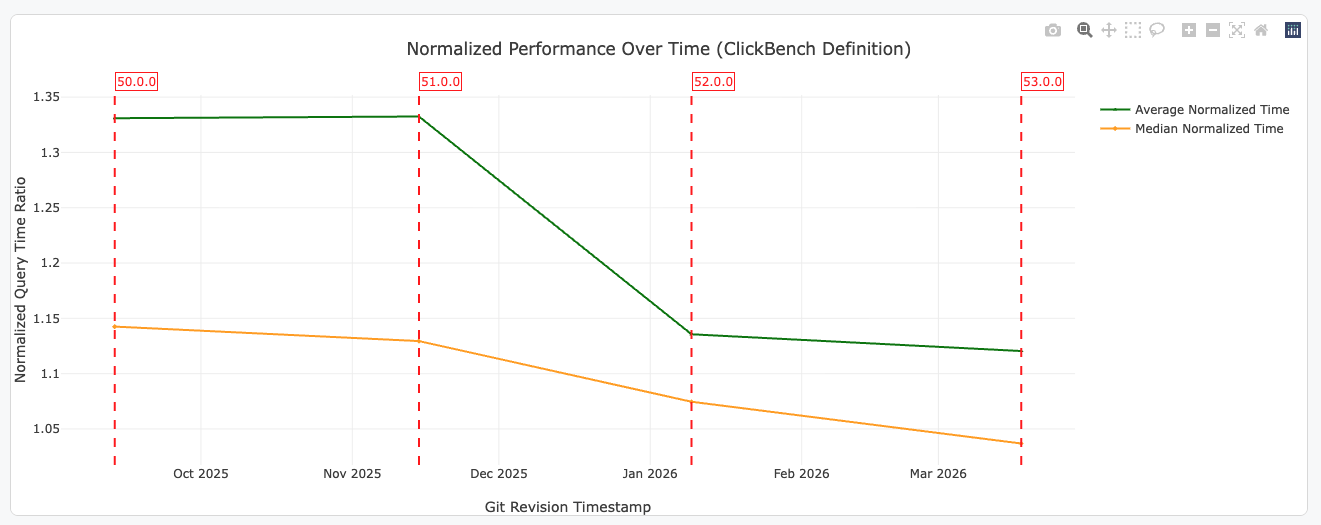
Apache DataFusion uses sortedness automatically — even when data is only partially sorted or when no ordering was declared. This post explains how plan-time sort pushdown, runtime scan reordering, and row-group pruning driven by dynamic filters make that possible.
Are Real Datasets Sorted?¶
Sorting data …